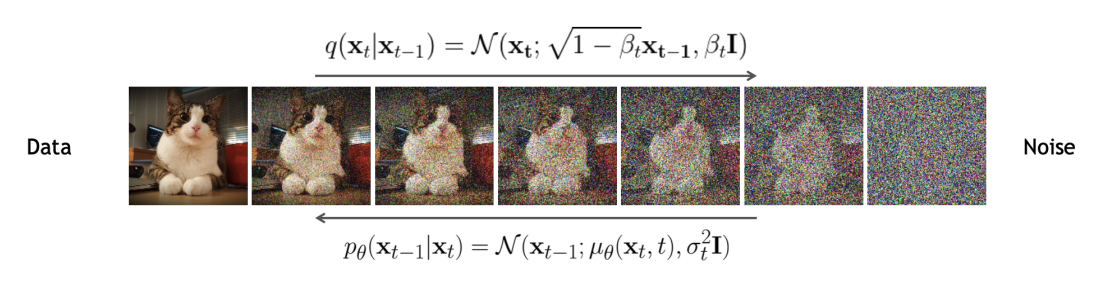Diffusion Models 디퓨전 모델 Diffusion Models 은 최근 이미지 생성 분야에서 가장 널리 사용되고 있는 딥러닝 아키텍쳐 중 하나이고, VAE, Normalizing Flow 등의 모델과 유사하다. 기본적인 아이디어는 노이즈로부터 구조화된 데이터(e.g. 이미지)를 찾는 것은 어렵지만, 구조화된 데이터를 노이즈로 변환하는 것은 비교적 간단하다는 것이다.이러한 과정...
2024. 1. 25.5 min read
Diffusion Models
디퓨전 모델Diffusion Models은 최근 이미지 생성 분야에서 가장 널리 사용되고 있는 딥러닝 아키텍쳐 중 하나이고, VAE, Normalizing Flow 등의 모델과 유사하다. 기본적인 아이디어는 노이즈로부터 구조화된 데이터(e.g. 이미지)를 찾는 것은 어렵지만, 구조화된 데이터를 노이즈로 변환하는 것은 비교적 간단하다는 것이다.이러한 과정을 diffusion process라고 하며, normalizing flow와 유사하게 주어진 데이터에 sequential한 변수변환을 주어 데이터 x0를 xT∼N(0,I)으로 변환한다. 이후, VAE와 유사하게 노이즈로부터 구조화된 데이터를 복원하게 된다.
Denoising diffusion probabilistic models (DDPM)
2015년에 제안된 denoising diffusion probabilistic models, 줄여서 DDPM이라고 부르는 모델은 디퓨전 모델의 근간이 된다 (Ho et al., 2020). 앞서 언급한 것과 같이, 주어진 input data x0를 latent states x1,⋯,xT로 변환시키며 최종적으로는 노이즈 형태로 변환하는 것이 목적이다. VAE와 마찬가지로 이러한 구조를 encoder로 정의하며, 아래 그림의 q(xt∣xt−1)을 의미한다.
DDPM의 구조 (Murphy, 2023)
다만, normalizing flow는 이러한 변환 q들에 대해 각각의 역변환이 존재해야 하지만(invertible), 디퓨전 모델에서는 그러한 제약조건이 존재하지 않는다. 또한, 인코더의 각 변환 q를 간단한 linear Gaussian model으로 구성하는데 DDPM에서는 이러한 인코더를 학습시키지 않는다는 특징이 있다.
노이즈를 기존 구조화된 데이터로 복원시키는 과정을 decoder로 정의하며, 이는 VAE에서의 경우와 마찬가지로 각 변환에 파라미터를 주어, 이들을 모델 훈련 과정에서 학습시키게 된다.
Encoder
Encoder process의 각 과정은 Markov property를 갖는 simple Linear Gaussian으로 가정한다. 즉, 다음과 같이 주어진다.
q(xt∣xt−1)=N(xt∣1−βtxt−1,βtI)
이때 β값들은 noise schedule에 따라 결정된다. 위 가정으로부터 잠재변수들에 대한 결합확률밀도는 다음과 같이 계산된다.
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
이는 Markov chain이 되므로 marginal distribution을 다음과 같이 구할 수 있다.
다만, 학습 과정이 아닌 데이터 생성 과정에서는 x0에 대한 정보가 없으므로, 이 경우에는 x0을 평균적으로 잘 근사하는 approximator p를 학습시킨다.
pθ(xt−1∣xt)=N(xt−1∣μθ(xt,t),Σθ(xt,t))
Model Fitting
DDPM은 VAE와 유사하게, ELBOevidence lower bound를 최대화하는 방향으로 모델 학습을 진행시킨다. 이때, evidence는 decoder에서의 input data의 marginial probability logpθ(x0)으로 주어진다. 이는 다음과 같이 나타낼 수 있다.
여기서 λt 부분이 목적함수 L을 최적화하는 문제가 최대가능도 추정의 방향으로 학습이 진행되도록 하는 역할을 한다. 다만, 실험적으로 λt=1 로 세팅하는 것이 모델의 샘플 생성 과정에서 더 나은 결과를 갖는다는 것이 알려져 있다고 한다. 이러한 세팅에서의 loss를 simplified loss라고 한다.
Noise Scheduling
이번에는 앞서 언급한 noise schedule 방법에 대해 살펴보고자 한다. Noise scheduling은 인코더 부분에서 이루어지며, 이 과정으로 ELBO를 최대화한다. 이러한 접근법을 Variational Diffusion Model 이라고도 한다 (Kingma et al., 2023). 우선, 인코더의 marginal distribution을 다음과 같이 나타내도록 하자.
q(xt∣x0)=N(xt∣α^tx0,σ^t2I)(1)
여기서 모수 α^t,σ^t2를 각각 학습하기 보다는 이들의 비율인 signal noise ratio(SNR) 를 학습한다.
R(t)=σ^t2α^t2
t가 증가할수록 q(xt∣x0)이 N(0,I)에 수렴하므로 R(t)는 t에 대한 단조감소함수임을 확인할 수 있다. 일반적으로 monotonic neural network γϕ를 이용하여 R(t)=exp(−γϕ(t)) 로 나타낸다.
Parametrization (1)로부터 Diffusion loss LD는 다음과 같이 주어진다.
LD(x0)=21E[∫01R′(t)∥x0−x^θ(zt,t)∥22]dt
여기서 zt=αtx0+σtϵ이고 ϵ∼N(0,I) 이다. 그런데, SNR 함수 R은 역함수가 존재하기 때문에, x~θ(z,t)=x^θ(zt,R−1(t)) 가 성립하고 diffusion loss는 다음과 같이 변환가능하다.
LD(x0)=21E[∫R(0)R(1)∥x0−x~θ(zv,v)∥22dv]
위 적분은 timestep t∈[T] 를 샘플링하여 근사할 수 있다. 다만, 무작위로 독립적인 timestep들을 추출하는 것 대신에 low-discrepancy sampler을 이용할 수 있는데, 이는 u0∼Unif(0,1) 을 샘플링하여 i번째 timestep으로 ti=mod(u0+ki,1) 을 사용한다.
References
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models (arXiv:2006.11239). arXiv. http://arxiv.org/abs/2006.11239
Murphy, K. P. (2023). Probabilistic machine learning: Advanced topics. The MIT Press.