Differential Privacy Setting $D=(d{1},\ldots,d{n})\in \mathcal{D}$을 입력 데이터베이스라고 하자. 또한, $M:\mathcal{D} \to \mathbb{R}^{d}$를 non-private 알고리즘이라고 하고, $M(D)$를 그에 대응하는 출력이라고 하자. 그러면, 출력 공간 (e.g. $\mathbb{R}^{d}$)을 고려하여, 랜...
2024. 1. 31.6 min read
Differential Privacy
Setting
D=(d1,…,dn)∈D을 입력 데이터베이스라고 하자. 또한, M:D→Rd를 non-private 알고리즘이라고 하고, M(D)를 그에 대응하는 출력이라고 하자. 그러면, 출력 공간 (e.g. Rd)을 고려하여, 랜덤화된 메커니즘은 분포 {PD:D∈D}로 특성화할 수 있다. Ω를 σ-field F가 부여된 공간이라고 하자. 그러면, 우리는 분포에 대한 DP를 정의할 수 있다.
Definition
분포들의 집합 {PD:D∈D}은 다음 조건을 만족하면 (ϵ,δ)-DP를 만족한다고 한다.
PD(A)≤eϵPD′(A)+δ,∀A∈F(1)
여기서 F는 PD가 정의되는 가장 작은 σ-field이다.
Sigma-field of DP algorithm
σ-field F 은 DP 알고리즘에서 중요한 역할을 한다.
F={Ω,ϕ}이면 조건 (1)은 자명하게 만족된다.
따라서 Ω가 이산적일 때, 일반적인 σ-필드는 F=2Ω이다.
Ω가 위상 공간일 때, F=B(Rd) (Borel σ-field)이다.
이 논문에서, Ω는 함수의 공간, 즉 무한 차원 벡터 공간으로 간주된다.
DP on Finite Dimensional Vector space
유한차원 벡터공간에서는 sensitivityΔ 가 유계이도록 할 수 있기 때문에, 이를 이용해 DP를 정의할 수 있다.
Lemma
모든 이웃 데이터셋 D∼D′에 대해 다음을 만족하는 집합 AD,D′∗∈F 이 존재한다고 하자.
S⊆AD,D′∗⇒PD(S)≤eϵPD′(S),∀S∈F(2)
이고
PD(AD,D′∗)≥1−δ
그러면 분포족 {PD}은 (ϵ,δ)-DP를 만족한다.
Remark
만일 (Ω,F)이 σ-finite인 지배측도 λ를 가지면, (2)의 충분조건을 만족시키기 위한 조건은 다음과 같다.
정부호 대칭행렬 M∈Rd×d에 대해, 벡터들의 모임 {vD:D∈D}⊂Rd이 다음을 만족하고
D∼D′supM−21(vD−vD′)2≤Δ
입력 데이터 D를 갖는 랜덤화된 알고리즘이 다음 출력을 생성한다고 하자.
v~D=vD+ϵc(δ)ΔZ,Z∼N(0,M)
그러면 해당 알고리즘은 다음 조건 하에서 (ϵ,δ)-DP를 만족한다.
c(δ)≥2logδ2.
여기서 Δ는 Mahalanobis 거리로 측청된 민감도라고 볼 수 있으며, M=I인 경우는 (McSherry & Mironov, 2009)에서 사용한 유클리드 거리를 나타낸다.
Implication
프라이버시를 보호한다는 관점에서, 상대방adversary이 알고 있는 데이터베이스를 DA라고 하자. 이때, DA=(d1,…dn−1) 이고, 프라이버시를 보호하는 데이터베이스를 D=(d1,…,dn)라고 하자. 이 경우 상대방은 DA∪{d}=D라고 생각할 수 있다. 이러한 상황에서 다음 명제가 성립한다.
Proposition
X∼PD이고 PD가 (ϵ,δ)-DP를 만족한다고 하자. 그러면 H=D=D0 vs V:D=D0의 유의수준 γ의 검정의 검정력은 γeϵ+δ 보다 작거나 같다.
해당 검정은 공간에서 가측집합이므로, DP의 제약 조건이 유지된다.
DP on the Function space
T=Rd에서의 함수 모임을 다음과 같이 고려하자.
fD:D∈D⊂RT
랜덤화된 메커니즘은 입력 D를 받아서 f~D∼PD를 출력한다. 여기서 PD는 D에 대응하는 RT에서 measurable한 분포이다.
Field of Cylinders
모든 유한 부분집합 S=(x1,…,xn) of T와 Borel 집합 B∈B(Rn)에 대해 함수의 cylinder 집합을 다음과 같이 정의하자.
여기서 S는 T의 가산 부분집합이다. 그러면, 가산 집합 S에 대해, cylinder 집합은 다음과 같은 형태를 가진다.
CS,B={f∈RT:f(xi)∈Bi,i=1,2,…}=i=1⋂∞C{xi},Bi
여기서 Bi∈B(R)이다. 또한, 이로부터 DP의 정의를 다음과 같이 쓸 수 있다.
PD(A)≤eϵPD′(A)+δ,∀A∈F
Gaussian Process Noise
Definition
T에 의해 인덱싱된 가우시안 프로세스Gaussian Process, GP는 각각의 유한 부분집합이 다변량 가우시안 분포를 갖는 확률변수들의 집합(process) {Xt:t∈T}이다. 가우시안 프로세스에서의 sample은 함수 T→R를 의미한다(sample function).
GP는 다음과 같은 mean function, covariance function으로 정의된다.
m(t)=EXt,K(s,t)=Cov(Xs,Xt)
즉, 유한부분집합으로 정의되는 분포는 다음과 같이 정의된다.
{Xt:t∈S}∼N(m(t),K)
이렇게 유한부분집합 S에 의해 정의되는 다변량 정규분포를 projection으로도 볼 수 있다.
Proposition
G∼GP(0,K) 이라고 하자. M은 Gram matrix를 의미하고, 집합 {fD:D∈D}은 입력 데이터베이스로 인덱싱된 함수들의 모임이라고 하자. 그러면 다음 함수의 releasing은
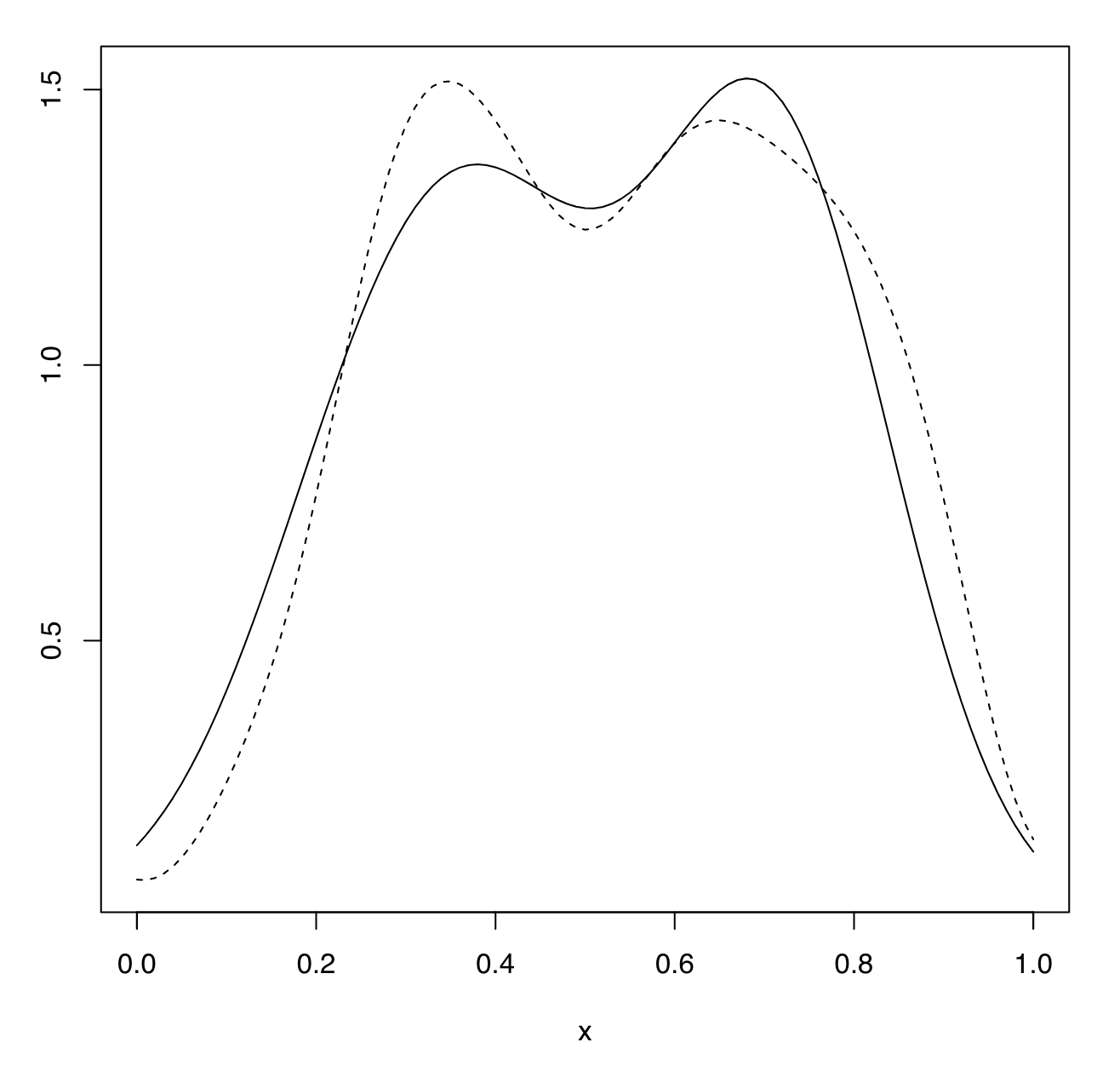
주목할 것은, rate of convergence 측면에서, 정확성이 손실되지 않았다는 것이다. 아래 그림은 DP가 적용되지 않은 경우와 적용된 경우를 비교한 것이다.
Non-private KDE(실선) vs Private KDE(점선)
Optimal bandwidth for DP
KDE에서 optimal bandwidth를 구하는 과정은 대개 LOOCVLeave-one-out-Cross-Validation를 사용한다.
다만, DP를 고려할 경우 T가 compact set이라는 가정이 필요하다.
이러한 가정이 없는 경우, 다음과 같은 rule of thumb을 사용할 수 있다.
h^=((d+1)n4)d+411.34IQRj
여기서 IQRj는 j번째 변수의 interquartile range이다.
References
Hall, R., Rinaldo, A., & Wasserman, L. (n.d.). Differential Privacy for Functions and Functional Data.
Billingsley, P. (1995). Probability and Measure. Wiley.
McSherry, F., & Mironov, I. (2009). Differentially private recommender systems: Building privacy into the Netflix Prize contenders. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 627–636. https://doi.org/10.1145/1557019.1557090