research paper
Bias and Uncertainty in LLM-as-a-Judge Estimation
Introduction
최근 LLM 평가에서 LLM-as-a-JudgeLaaJ는 거의 기본 도구처럼 사용되고 있습니다. 사람이 모든 답변을 채점하기에는 비용이 크기 때문에, 또 다른 LLM에게 "이 답변이 맞는가?", "두 답변 중 어느 것이 더 좋은가?"를 묻고 그 결과를 모델 성능의 proxy로 사용하는 방식입니다.
하지만 통계학적인 관점에서 보면, LLM judge가 반환하는 값은 모델의 성능 그 자체가 아닙니다. 조금 더 정확히 말하면, judge는 우리가 알고 싶은 latent outcome을 noisy하게 관측하는 측정 도구measurement device에 가깝습니다. 따라서 judge의 출력값을 그대로 평균내면, 우리가 원하는 accuracy가 아니라 judge의 오차가 섞인 quantity를 추정하게 됩니다.
이번 글은 James Fiedler의 2026년 arXiv 논문 Bias and Uncertainty in LLM-as-a-Judge Estimation을 바탕으로, LLM-as-a-Judge 평가를 measurement error, bias correction, calibration instability 관점에서 정리한 글입니다.
핵심 아이디어는 간단합니다.
LLM judge를 classifier로 보면, judge score는 sensitivity와 specificity를 가진 noisy label이다.
이 관점으로 들어가면, LLM 평가에서 왜 단순 평균이 biased estimate가 되는지, bias correction이 왜 항상 안전하지 않은지, 그리고 model comparison에서 왜 sign reversal이 생길 수 있는지 꽤 선명하게 볼 수 있습니다.
LLM Judge as a Measurement Device
가장 단순한 binary evaluation setting을 생각하겠습니다. 어떤 모델의 답변이 실제로 맞았는지 여부를
라고 하고, LLM judge가 내린 판정을
라고 하겠습니다. 여기서 우리가 알고 싶은 값은 true accuracy
입니다. 그러나 실제 evaluation pipeline에서 관측하기 쉬운 값은 의 평균입니다. 즉,
를 보게 됩니다.
만일 judge가 완벽하다면 이므로 입니다. 그러나 judge가 imperfect classifier라면 두 값은 달라집니다. 이때 judge의 성능을 다음 두 값으로 표현할 수 있습니다.
그러면 judge가 positive label을 낼 확률은 다음과 같이 분해됩니다.
이 식이 논문의 출발점입니다. LLM judge의 평균 score는 를 직접 추정하는 것이 아니라, 가 judge의 sensitivity/specificity에 의해 변형된 값 를 추정합니다. 즉, raw judge score를 accuracy처럼 해석하려면 암묵적으로 이라고 가정하는 셈입니다.
Rogan-Gladen Correction
위 식을 에 대해 풀면 다음과 같은 보정 추정량을 얻을 수 있습니다.
실제로는 을 알 수 없으므로 sample estimate를 사용합니다.
이것이 논문에서 다루는 Rogan-Gladen estimator입니다. 원래는 diagnostic test의 misclassification bias를 보정하는 데 사용되는 고전적인 estimator인데, 여기서는 LLM judge를 diagnostic test처럼 보고 가져온 셈입니다.
중요한 것은 분모입니다.
이 값은 Youden's J라고 불리며, binary diagnostic test의 품질을 나타내는 지표입니다. 이면 완벽한 judge이고, 이면 positive와 negative를 구분하지 못하는 judge입니다. 보정식에서 가 분모에 있기 때문에, 가 작아질수록 보정은 불안정해집니다.
직관적으로도 그렇습니다. judge가 잘 구분하지 못하면 raw score 에는 true accuracy 에 대한 signal이 약하게만 남습니다. 이 약한 signal을 다시 scale로 되돌리려면 만큼 확대해야 합니다. 따라서 judge quality가 낮을수록 correction은 noise와 calibration error도 함께 키우게 됩니다.
Model Comparison and Shared Calibration
단일 모델의 accuracy를 추정하는 것보다 더 자주 하는 일은 두 모델을 비교하는 것입니다. 예를 들어 모델 A와 모델 B의 true accuracy 차이를
라고 합시다. LLM leaderboard나 ablation study에서 실제로 궁금한 것은 대개 이 값입니다.
문제는 calibration입니다. 을 추정하려면 사람이 라벨링한 calibration set이 필요합니다. 비용을 줄이기 위해 한 모델에서 얻은 calibration 정보를 다른 모델에도 공유하고 싶은 유혹이 생깁니다. 논문에서는 이를 shared calibration이라고 부릅니다.
하지만 shared calibration이 성립하려면 강한 가정이 필요합니다. 같은 judge가 모델 A의 답변을 평가할 때와 모델 B의 답변을 평가할 때 동일한 sensitivity/specificity를 가져야 합니다. 즉,
이어야 합니다.
현실적으로는 이 가정이 쉽게 깨질 수 있습니다. 어떤 모델의 답변은 장황하지만 맞는 경우가 많고, 다른 모델의 답변은 짧지만 애매할 수 있습니다. 혹은 특정 모델이 judge가 선호하는 문체를 더 잘 따를 수도 있습니다. 이 경우 judge error는 model-dependent해집니다.
논문은 이 차이를 진단하기 위해 를 봅니다.
만약 가 0에서 멀다면, shared calibration assumption을 믿기 어렵습니다. 더 중요한 점은 이 calibration mismatch가 단순히 작은 오차로 남는 것이 아니라, 앞서 본 correction에 의해 비교 추정량에서 크게 증폭될 수 있다는 것입니다.
Simulation Result
아래 그림은 논문의 Figure 1을 공식 PDF에서 crop한 것입니다. judge quality 와 cross-model calibration instability 가 바뀔 때, 여러 estimator의 coverage와 bias가 어떻게 변하는지를 보여줍니다.
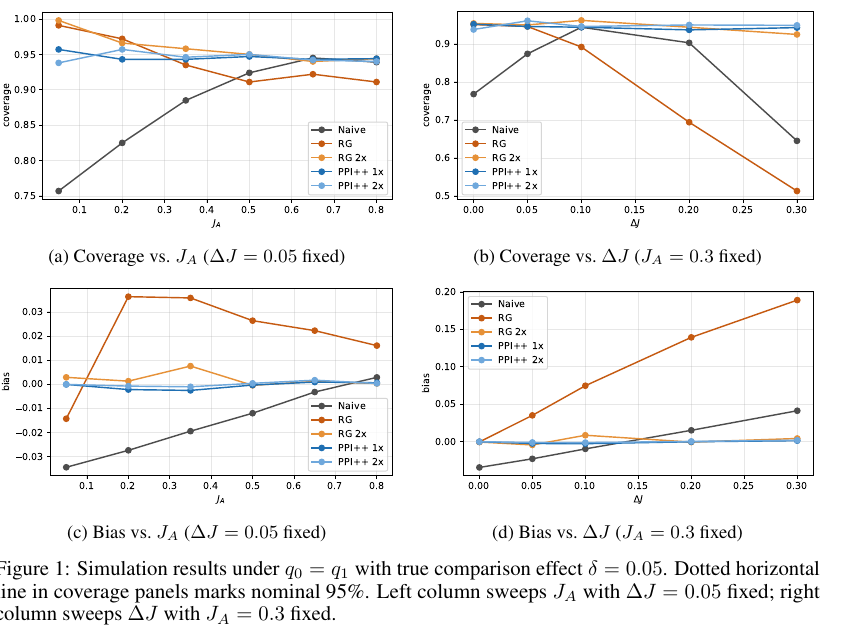
Source: Fiedler (2026), arXiv:2605.06939, Figure 1, captured/cropped from the official arXiv PDF.
왼쪽 column은 로 고정하고 judge quality 를 바꾼 경우입니다. 오른쪽 column은 으로 고정하고 를 바꾼 경우입니다.
여기서 눈여겨볼 점은 세 가지입니다.
첫째, naive estimator는 대부분의 경우 biased합니다. 이는 앞에서 본 measurement equation
때문입니다. judge가 완벽하지 않으면 raw score는 true accuracy scale에 있지 않습니다.
둘째, RG estimator는 bias correction을 하지만 항상 안정적이지 않습니다. 특히 가 커질수록 RG의 bias가 빠르게 커집니다. shared calibration에서 생긴 mismatch가 에 의해 증폭되기 때문입니다.
셋째, PPI++ 계열 estimator는 simulation에서는 상대적으로 안정적으로 보입니다. 다만 논문의 메시지는 "PPI++를 쓰면 된다"가 아닙니다. 더 정확히는, estimator를 바꾸는 것만으로는 충분하지 않고 judge quality와 calibration stability를 먼저 확인해야 한다는 것입니다.
MMLU-Pro Case Study
논문은 실제 데이터 예시로 MMLU-Pro를 사용합니다. 비교 대상 base model은 Gemma 3 12B와 Qwen 2.5 7B이고, judge model로는 Mistral Large와 Gemma 4 31B를 사용합니다. Subject는 math와 biology를 중심으로 봅니다.
아래 그림은 논문의 Figure 2입니다. 각 panel은 estimator별 accuracy estimate와 95% bootstrap confidence interval을 보여줍니다. 점선은 test set에서 계산한 true accuracy입니다.
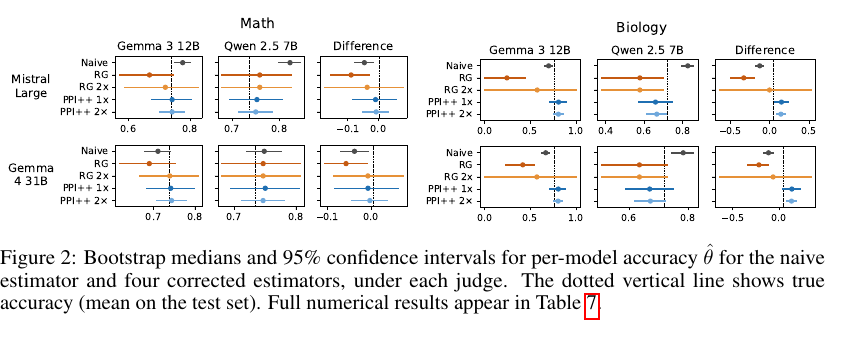
Source: Fiedler (2026), arXiv:2605.06939, Figure 2, captured/cropped from the official arXiv PDF.
Math에서는 두 base model의 true accuracy가 거의 비슷합니다. 이런 near-tie 상황에서는 작은 bias도 비교 결론을 쉽게 흔들 수 있습니다. 그림을 보면 naive estimator는 두 모델 모두에서 true accuracy와 꽤 떨어져 있고, RG estimator도 shared calibration의 영향으로 불안정한 모습을 보입니다.
Biology는 더 심각합니다. 논문에 따르면 이 subject에서는 judge quality가 낮고, 특히 Gemma 3에 대한 judge behavior와 Qwen 2.5에 대한 judge behavior가 다릅니다. 이때 naive estimator와 shared-calibration RG estimator는 비교 방향 자체를 틀리게 만들 수 있습니다. 논문에서는 이를 sign-reversal failure로 설명합니다.
이 부분이 개인적으로 가장 흥미롭습니다. 우리는 보통 confidence interval이 0을 제외하면 "차이가 있다"고 말하고 싶어합니다. 그런데 estimator 자체가 잘못 calibration되어 있으면, confidence interval은 좁고 확신에 차 있어도 틀린 방향을 가리킬 수 있습니다. 즉, uncertainty quantification은 estimator의 target이 올바를 때 의미가 있습니다.
Bootstrap Uncertainty
논문은 confidence interval을 만들 때 bootstrap을 사용합니다. 단순히 test examples만 resampling하는 것이 아니라, evaluation design에 맞게 calibration uncertainty와 test uncertainty를 반영합니다.
이 점도 중요합니다. LLM-as-a-Judge evaluation에서는 불확실성의 원천이 하나가 아닙니다.
- test set이 유한하기 때문에 생기는 sampling uncertainty
- calibration set이 유한하기 때문에 생기는 uncertainty
- model comparison에서 같은 item을 두 모델이 함께 푸는 paired structure
- judge가 model-dependent하게 오차를 내는 calibration instability
따라서 단순히 "judge score의 표준오차"만 계산하면 중요한 불확실성을 놓칠 수 있습니다. 특히 bias-corrected estimator에서는 calibration set의 불확실성이 분모 를 통해 크게 반영될 수 있습니다.
Practical Lesson
이 논문을 읽고 나면 LLM-as-a-Judge 평가를 다음과 같이 보는 것이 자연스럽습니다.
즉, judge를 하나 고르고 평균 점수를 내는 것으로 끝나는 문제가 아닙니다. 최소한 다음을 확인해야 합니다.
- Raw judge score인지, bias-corrected estimate인지 구분해야 합니다.
- Judge quality를 나타내는 를 보고해야 합니다.
- Model comparison에서는 를 확인해야 합니다.
- Shared calibration을 사용했다면 그 가정을 정당화해야 합니다.
- Confidence interval은 calibration uncertainty까지 포함해야 합니다.
특히 LLM evaluation 연구에서 "A가 B보다 좋다"는 결론은 단일 모델의 accuracy estimate보다 더 조심해야 합니다. 두 모델에 대한 judge error가 서로 다르면, 각 모델의 bias가 비교 과정에서 한 방향으로 누적될 수 있기 때문입니다.
Research Direction
이 논문은 LLM evaluation을 통계적 추론 문제로 다루는 좋은 출발점입니다. 개인적으로는 다음 방향과 잘 연결된다고 생각합니다.
첫째, RAG evaluation입니다. Retrieval relevance, faithfulness, answer correctness는 서로 다른 judge error를 가질 수 있습니다. 따라서 하나의 LLM judge를 여러 평가 축에 공통으로 사용하는 경우, 각 축마다 와 calibration stability를 따로 봐야 합니다.
둘째, causal inference입니다. LLM judge score를 noisy proxy outcome으로 보면, human label은 gold-standard calibration sample이 됩니다. 이때 measurement error가 있는 outcome으로 treatment effect를 추정하는 문제와 연결할 수 있습니다.
셋째, Bayesian optimization입니다. LLM judge를 preference oracle로 사용해 prompt나 model을 최적화하는 경우, judge quality가 낮으면 acquisition function 자체가 잘못된 signal을 따라갈 수 있습니다. Preferential Bayesian optimization에서 judge uncertainty를 명시적으로 넣는 방향이 자연스럽습니다.
넷째, spatial/geospatial evaluation입니다. VLM이나 geospatial LLM의 답변을 judge가 평가할 때, 지역이나 object density에 따라 judge error가 달라질 수 있습니다. 이 경우 처럼 위치에 따라 변하는 calibration diagnostic을 생각해볼 수 있습니다.
References
- James Fiedler, "Bias and Uncertainty in LLM-as-a-Judge Estimation", arXiv preprint, 2026.
- arXiv: 2605.06939
- PDF: https://arxiv.org/pdf/2605.06939
- DOI: 10.48550/arXiv.2605.06939
- Suggested tags:
llm-meets-statistics,daily-paper,llm-evaluation,statistical-inference,uncertainty - Reference manager collection:
Recent Trends