Support Vector Regression
이전 게시글에서 SVM의 작동 원리와 SVR, 즉 support vector regression이 SVM의 원리를 차용하여 생성되는 모델이라는 점에 대해 살펴보았다. 이번에는 paper *"A Tutorial on Support Vector Regression(2003)"*을 바탕으로 SVM이 회귀분석에 사용되는 경우만 특히 집중해서 살펴보고, 이와 더불어 사용되는 NuSVR 모델에 대해서도 간략히 다루어보도록 하자.
SVR
이전에 살펴본 내용에서 ϵ-insensitive error measure Vϵ(r) 을 이용한 방법을 다루었다. 이를 ϵ-SVR 이라고도 하며, primal (optimization) problem은 다음과 같이 주어진다[Vapnik, 1995].
w,b,ξ,ξ∗min21∥w∥2+Ci=1∑N(ξi+ξi∗)subject toyi−⟨w,ϕ(xi)⟩−b≤ϵ+ξi,⟨w,ϕ(xi)⟩+b−yi≤ϵ+ξi∗,ξi,ξi∗≥0,i=1,…,N(1)
Induction
함수 f(x)=⟨w,x⟩+b 를 추정하기 위해 Risk functional(위험 범함수)
R[f]=∫XL(f,x,y)dP(x,y)
을 최소화하는 함수 f 를 찾는 과정을 생각하자. 이때 Input space X에서의 확률분포 P(x,y) 는 알 수 없으므로, empirical risk를 사용하게 되고 이 과정에서 ϵ-insensitive loss function(아래 내용 참고)을 이용하여 다음과 같다.
Remp[f]:=N1i=1∑N∣y−f(xi)∣ϵ
Empirical risk를 이용해 다음과 같이 regularized risk functional
21∥w∥2+C⋅Remp[f]
을 최소화하는 f를 찾는 문제는 결국 식 (1)와 동일한 최적화문제로 귀결된다(ϵ 미만의 오차를 용인하는 것을 slack variable ξ 를 이용해 표현한 것이다. 아래 그림 참고).
여기서 상수 C>0 은 hyperplane f의 flatness와 ϵ 이상의 오차를 얼마만큼 용인(tolerate)할지에 대한 trade-off 이다. ξi,ξi∗ 는 margin과 관련된 penalize 변수이며, ϕ(x) 는 각 feature transformation을 의미한다. 제약조건의 앞선 두 식을 살펴보면, 실제 관측값 yi와 추정값 wTϕ(xi)+b 의 오차가 최소 ϵ 보다는 큰 관측 샘플들에 대해 penalize variable ξi 를 부과한다. 즉, 오차가 ϵ 보다 작은 관측값에 대해서는 penalizing이 이루어지지 않으며, 이는 이전 게시글에서 언급한 ϵ-insensitive과 일맥상통한다. ϵ-sensitive loss function은
∣ξ∣ϵ=max(0,∣ξ∣−ϵ)
으로 쓸 수 있으며, 실제 관측값 yi로부터 ϵ 만큼의 범위를 ϵ-tube 라고도 한다(아래 그림의 회색 영역).
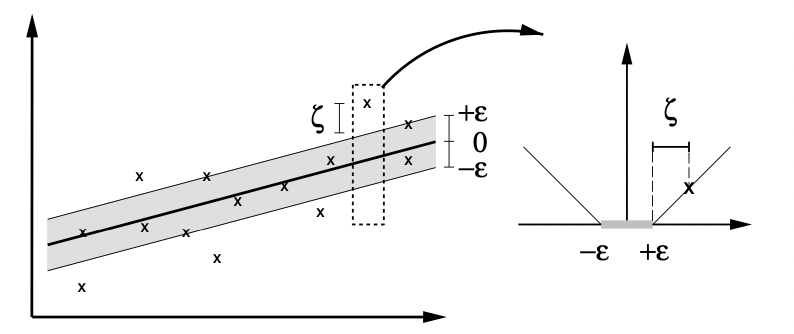
앞선 최적화문제 식 (1)은 dual formulation을 이용하여 쉽게 해결할 수 있는데, Lagrange multipliers 방법을 이용하여 다음과 같이 유도할 수 있다.
Dual Problem of SVR
우선 primal objective function을 다음과 같이 Lagrangrian L, Lagrange multipliers αi,αi∗,ηi,ηi∗ 를 이용해 다음과 같이 나타내도록 하자.
L:=21∥w∥2+Ci=1∑N(ξi+ξi∗)−i=1∑N(ηiξi+ηi∗ξi∗)−i=1∑Nαi(ϵ+ξi−yi+⟨w,xi⟩+b)−i=1∑Nαi∗(ϵ+ξi∗+yi−⟨w,xi⟩−b)(2)
편의상 αi(∗),ηi(∗) 가 각각 αi,αi∗와 ηi,ηi∗ 에 모두 대응된다고 하자. 그러면 dual variable로 주어지는 αi(∗),ηi(∗) 는 모두 0 이상의 값을 가져야 한다. 또한, primal problem(식 1)의 변수 (w,b,ξi,ξi∗) 에 대해 안장점 조건, 즉 각 변수들에 대한 L의 편미분계수가 0으로 소멸(vanish) 되어야 하므로
∂bL=i=1∑N(αi∗−αi)=0∂wL=w−i=1∑N(αi−αi∗)xi=0∂ξi(∗)L=C−αi(∗)−ηi(∗)(3)
와 같은 세 개의 조건을 얻는다. 위 세 조건 (3)를 primal objective function 식 (2)에 대입하여 정리하면 다음과 같은 dual optimization problem을 얻는다(함수 W(α,α∗) 의 최대화 문제).
W(α,α∗)=−21i,j=1∑N(αi−αi∗)(αj−αj∗)⟨xi,xj⟩−ϵi=1∑N(αi+αi∗)+i=1∑Nyi(αi−αi∗)subject toi=1∑N(αi−αi∗)=0andαi(∗)∈[0,C]
이 과정에서 ηi(∗) 는 조건 (3)의 세번째 식으로부터 소거되었음을 확인할 수 있다. 또한, 조건 (3)의 두번째 식으로부터
w=i∑(αi−αi∗)xi
를 얻을 수 있는데, 이를 이용해 hyperplane function f(x) 를
f(x)=i∑(αi−αi∗)⟨xi,x⟩+b(4)
와 같은 형태로 쓸 수 있다. 이를 Support Vector expansion 이라고 하는데, 이 과정에서 hyperplane의 parameter w가 오로지 관측 데이터 xi와 관련된 training pattern들의 선형결합으로 나타나는 사실을 확인할 수 있다. 즉 함수 f를 계산하는 과정은 Input space의 차원과 무관하게, support vector들의 개수에만 의존한다는 사실이다.
이러한 dual representation에서의 핵심은 식 (4)에서 특성공간의 내적 ⟨xi,x⟩=ϕ(xi)Tϕ(x) 대신 커널 함수 k(x,x′)를 적용하면(Kernel Trick) 기존의 hyperplane function f 대신
f(x)=i∑(αi−αi∗)k(xi,x)+b
의 형태를 사용할 수 있다. 커널함수의 조건에 관련된 자세한 정리들은 여기서 생략하도록 하겠다.
LinearSVR
Primal problem
w,b,ξ,ξ∗min21∥w∥2+Ci=1∑N(ξi+ξi∗)
에서 Loss 부분은 ∑i(ξi+ξi∗) 를 의미한다. 이때 classification 문제의 hinge loss와 유사한 epsilon-insensitive loss 를 이용하면 다음과 같은 primal problem
w,bmin21∥w∥2+Ci∑max(0,∣yi−⟨w,ϕ(xi)⟩+b∣−ϵ)
을 얻는데, 이를 최적화문제로 삼아 풀면 Linear Support Vector Regressor 모델을 얻을 수 있다.
NuSVR
NuSVR(Nu는 그리스 소문자 ν를 의미한다) 알고리즘은 앞서 살펴본 ϵ-SVR의 메커니즘과 유사하지만 ϵ 값을 사전에 설정하는 ϵ-SVR과 다르게 ϵ의 크기를 또 다른 상수 ν≥0를 이용해 제어한다. 우선 primal problem은 다음과 같이 주어진다.
minτ(w,ξ(∗),ϵ)=21∥w∥2+C⋅(νϵ+N1i=1∑N(ξi+ξi∗))subject to⟨w,xi⟩+b−yi≤ϵ+ξiyi−(⟨w,xi⟩+b)≤ϵ+ξi∗ξi(∗)≥0,ϵ≥0(5)
제약조건들에 대해 Lagrange multipliers αi(∗),ηi(∗),β≥0 을 설정하여 다음과 같은 Lagrangrian
L(w,b,α(∗),β,ξ(∗),ϵ,η(∗))=21∥w∥2+Cνϵ+NCi∑(ξi+ξi∗)−βϵ−i∑(ηiξi+ηi∗ξi∗)−i∑αi(ξi+yi−⟨w,xi⟩−b+ϵ)−i∑αi∗(ξi∗+⟨w,xi⟩+b−yi+ϵ)
을 얻을 수 있다. 또한, 식 (5)를 최적화하기 위해 primal variable에 대한 lagrangrian의 편미분계수를 0으로 하는 다음 방정식들을 구하자.
w=i∑(αi∗−αi)xiCν−i∑(αi+αi∗)−β=0i=1∑N(αi−αi∗)=0NC−αi(∗)−ηi(∗)=0
SVR에서와 마찬가지로, 위 네개의 식 중 첫번째 식을 SV expansion(Support Vector expansion)이라고 정의하며, 이때 식 (5)의 첫번째 및 두번째 제약조건을 등식으로(=) 만족하는 관측값(i)들에 대해서만 αi(∗) 값이 0이 아닌 값을 갖게 된다. 마찬가지로 이러한 관측값들을 support vector로 정의한다. 앞선 네 제약조건을 Lagrangrian L에 대입하면 새로운 optimization 문제를 얻는데, 이를 Wolfe dual problem이라고 한다. 이때, 최적화 문제의 내적을 커널 k(x,y):=⟨ϕ(x),ϕ(y)⟩ 로 대체하면 위의 dual problem을 다음과 같은 새로운 형태로 쓸 수 있으며, 이 과정에서 dual varaible β,ηi(∗)≥0 은 등장하지 않게 된다.
NuSVR Optimization Problem
maxW(α(∗))=∑i=1N(αi(∗)−αi)yi−21∑i,j=1N(αi∗−αi)(αj∗−αj)k(xi,xj)
&\alpha_i^{(\ast)}\in[0,{C\over N}] \
&\sum_{i=1}^N(\alpha_i+\alpha_i^{\ast}) \leq C\cdot\nu
\end{aligned}$$
위 NuSVR optimization 문제의 regression estimate는 다음과 같은 형태를 취하게 된다.
f(x)=i=1∑N(αi∗−αi)k(xi,x)+b
여기서 상수 b와 primal optimization function의 ϵ은 support vector 관측값들로부터 계산할 수 있게 된다.
NuSVR에서 ν의 역할에 대해서 살펴보도록 하자. 만일 ν>1 이면, primal function에서 Cνϵ 항의 최소화로 인해 ϵ=0 이 도출된다. 반면 ν≤1 인 경우 만일 데이터가 noise-free하고 low-capacity model에 의해 interpolate될 수 있는 경우(여기서 interpolation은 모델이 관측 데이터들의 점을 모두 지나는 경우를 의미한다) ϵ=0 인 경우가 발생할 수 있다. 그러나, 이는 plain L1-loss regression에 대응되므로, 이를 살펴보는 것은 큰 의미가 없게 된다.
다음 게시글에서는 NuSVR에서 parameter ν의 수학적 의미와 이론적 중요성에 대해 자세히 살펴보도록 하자.
References