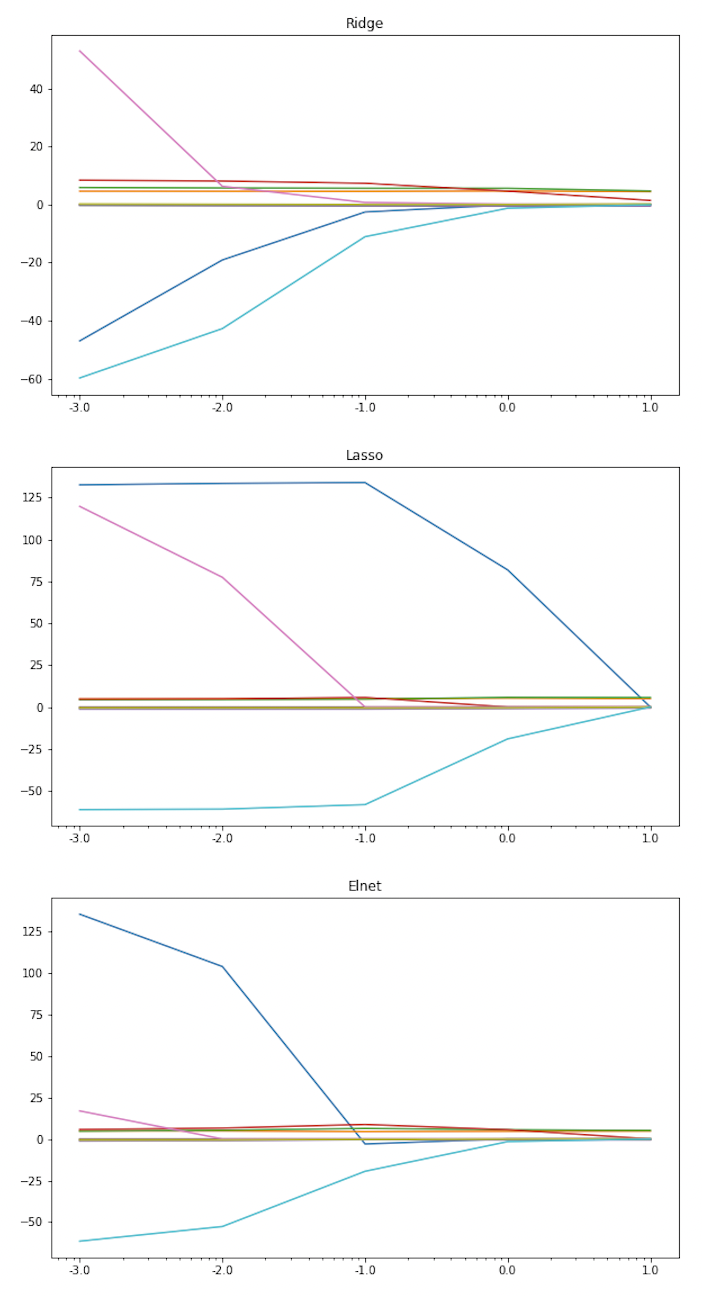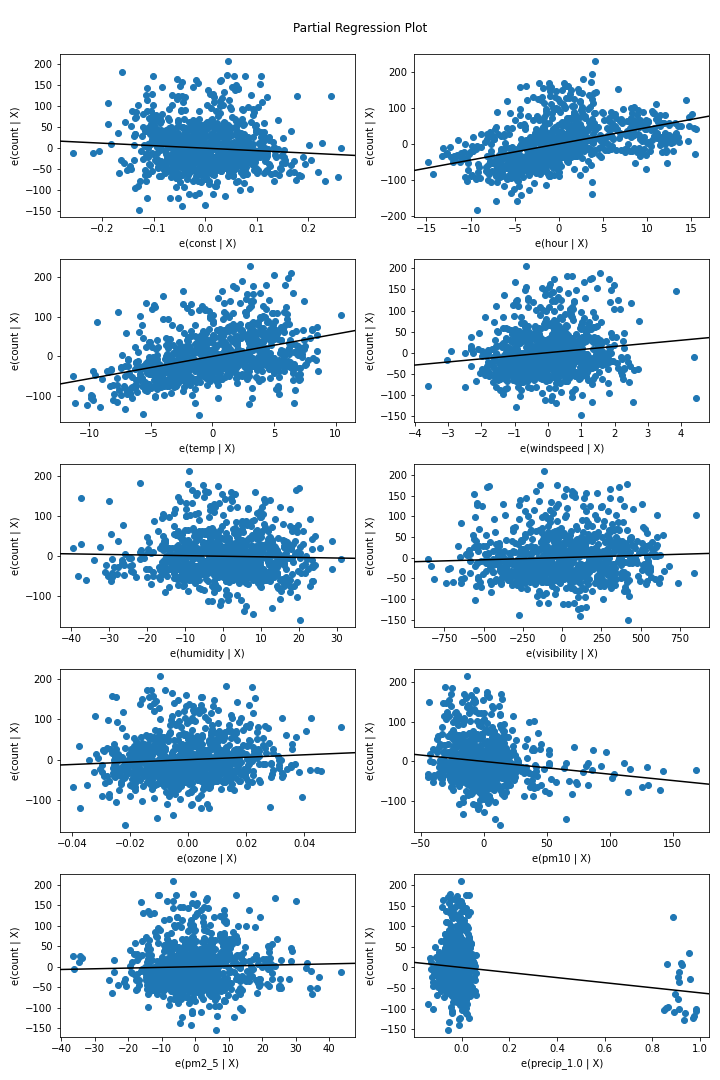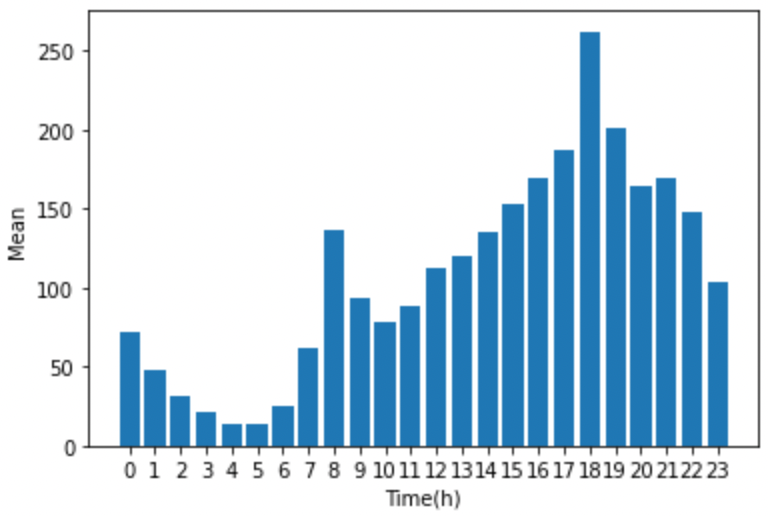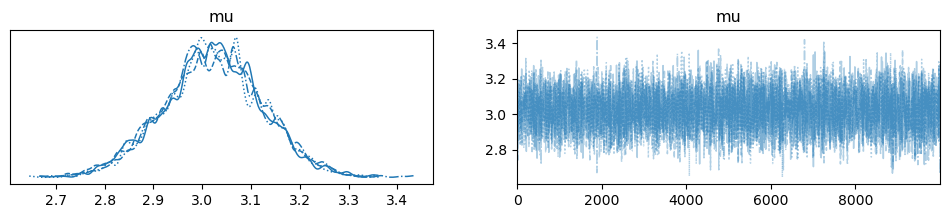
2024. 2. 13.Archive
PyMC 라이브러리를 활용한 베이지안 분석
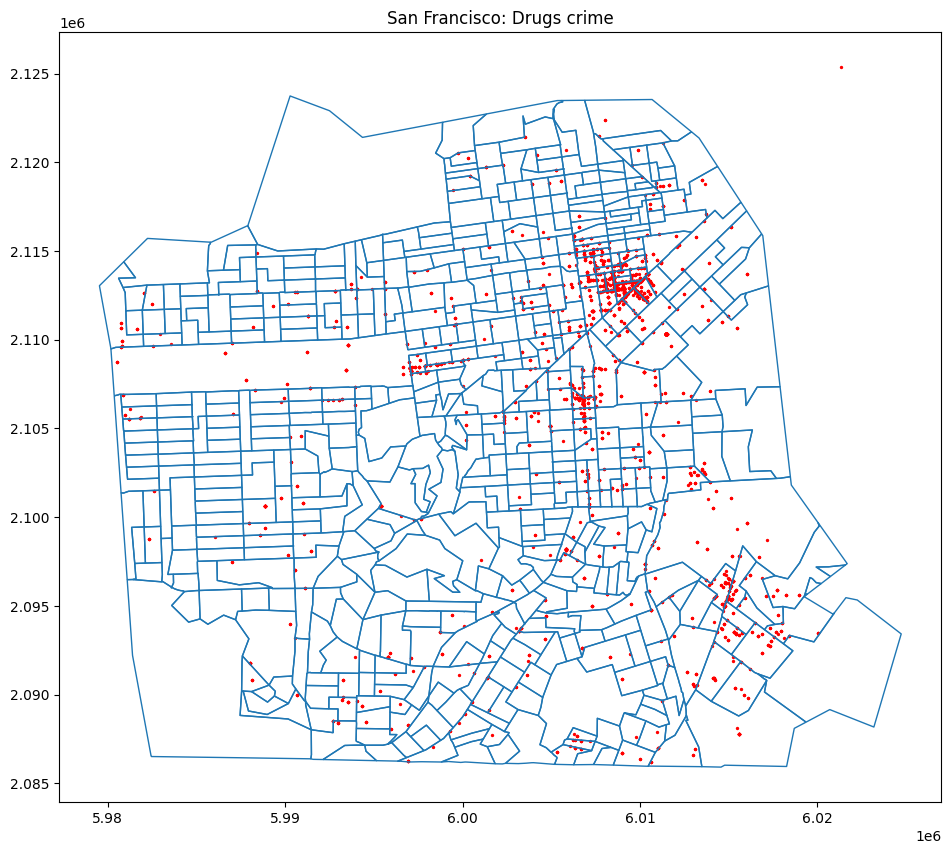
PyMC and Bayesian 이번 글에서는 Python에서 MCMC 기반의 베이지안 분석을 할 수 있도록 고안된 PyMC 라이브러리를 소개해보도록 하겠습니다. PyMC에서는 비교적 간단한 MCMC부터, Bayesian neural network BNN 까지 폭넓은 분석을 진행할 수 있습니다. 여기서는 선형회귀모형과 로지스틱 회귀모형, 그리고 BNN을 활용한 분류를 다루어보도록 하겠습...