Markov Random Field
Markov Random Field Markov Random Field란, 공간자료 중 격자형(lattice) 자료를 모델링하기 위해 사용되는 모델이다. 격자형 자료란, 말그대로 (규칙적 혹은 불규칙적) 격자 단위에서 변수들의 값이 주어지는 것을 의미한다. 이때 데이터셋을 구성하는 각 격자는 정사각형이나 정육각형처럼 규칙적일 필요는 없지만, 격자들 간의 인접구조(neighborhood...
Tag
Posts collected under Statistics.
Markov Random Field Markov Random Field란, 공간자료 중 격자형(lattice) 자료를 모델링하기 위해 사용되는 모델이다. 격자형 자료란, 말그대로 (규칙적 혹은 불규칙적) 격자 단위에서 변수들의 값이 주어지는 것을 의미한다. 이때 데이터셋을 구성하는 각 격자는 정사각형이나 정육각형처럼 규칙적일 필요는 없지만, 격자들 간의 인접구조(neighborhood...
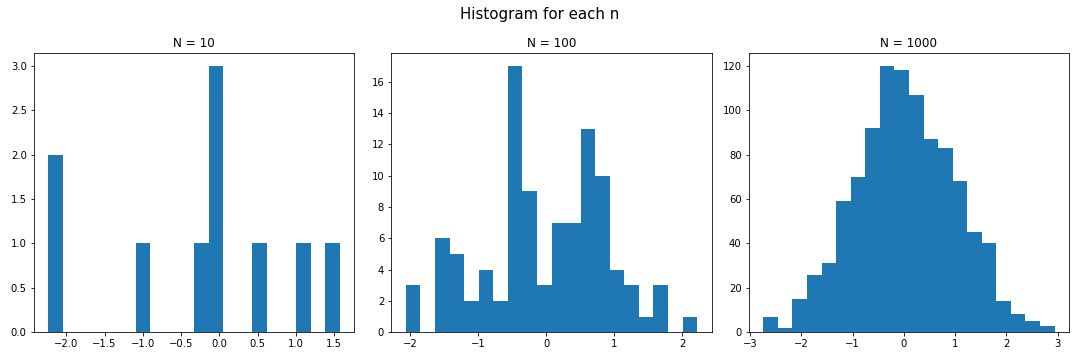
Generating random samples 이번 글에서는 주어진 확률분포로부터 랜덤 샘플들을 생성하는 방법에 대해 살펴보도록 하자. Simple method 만약 표본을 추출하고자 하는 대상 확률분포가 분포함수(cdf)로 주어지고, 그것의 역함수를 구할 수 있다면 다음 정리로부터 쉬운 표본추출이 가능하다. Theorem 만약 확률변수 $U$가 균등분포 $\mathrm{Unif}[0,...
Kolmogorov-Smirnov Test 일반적으로 데이터사이언스에서 데이터의 정규성을 검정하고자 할 때, 샘플 수가 적은 경우 Shapiro-Wilk 검정을 이용하고 그렇지 않은 경우 Kolmogorov-Smirnov(줄여서 ks) 검정을 이용한다고 알려져 있다. 사실 콜모고로프-스미르노프 검정은 정규성을 검정한다기 보다는 주어진 데이터로부터 얻은 경험적 분포(empirical di...
Complete Spatial Randomness As the first step to analyze spatial point pattern data, we need to check CSR, the complete spatial randomness. Preliminaries 1 Consider a point process $N$, as a random counting measure on...
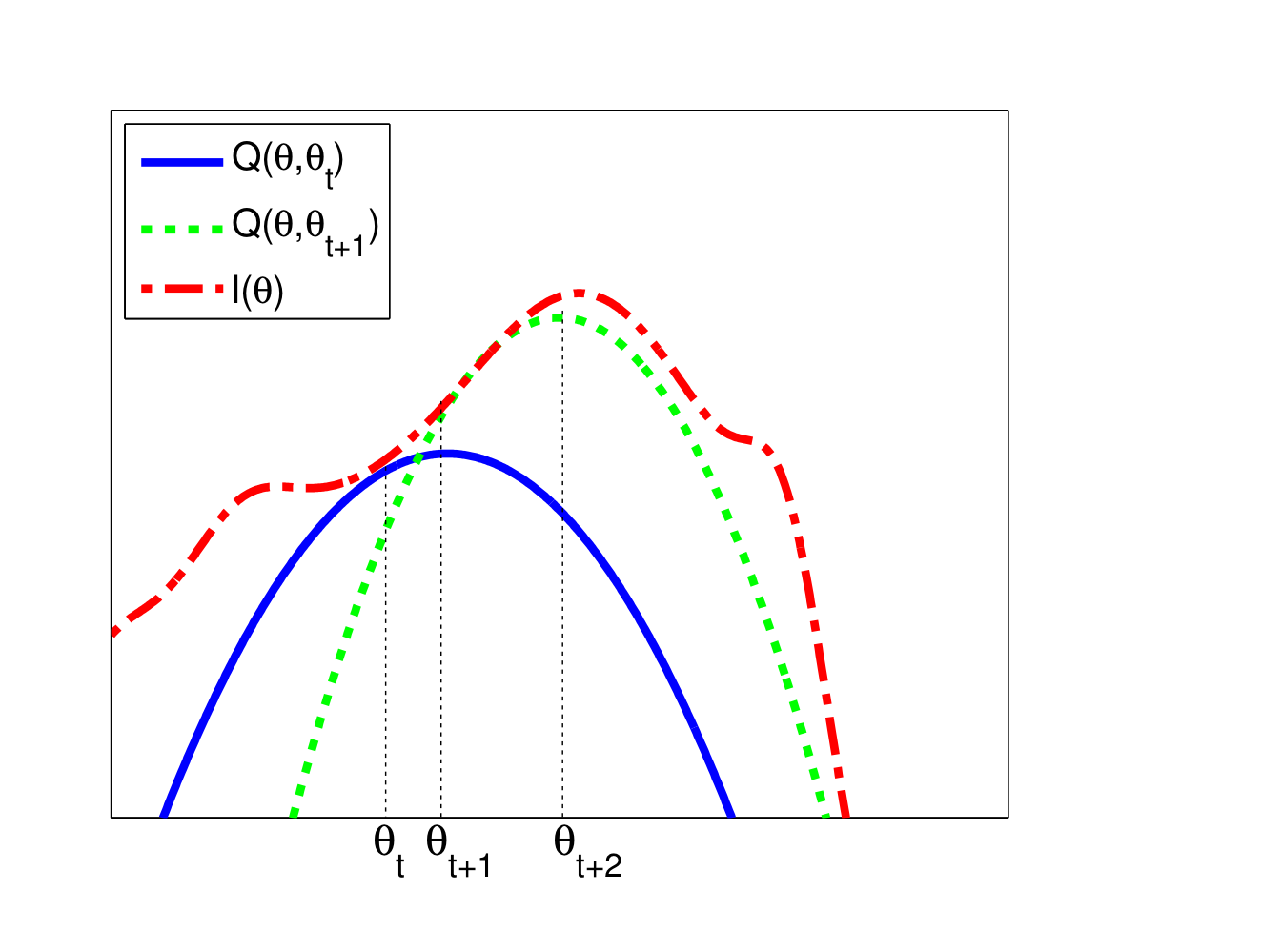
MM algorithm은 EM algorithm의 일반화된 버전으로 이해하면 되는데, MM은 maximization 관점에서 minorize-maximize를 나타낸다. MM algorithm은 최대화하고자 하는 목적함수 $l(\theta)$ 에 대한 lower bound function(surrogate function) $Q(\theta,\theta^{t})$ 를 찾고 이를 maxi...
일반화 선형모형(GLM)은 일반적인 선형모형(Linear Model, 반응변수와 설명변수의 관계가 선형이고 오차항의 분포가 normal인 모형)을 확장한 모형이다. 확장 방식은 반응변수와 설명변수의 관계를 nonlinear(ex. Exponential form)하게 바꾸거나, 혹은 오차항의 분포를 정규분포가 아닌 다른 분포로 가정하는 것이다. GLM을 정의하기 위해서는 세 가지 요소가...
이번 포스트에서는 통계학의 추정, 검정 등에서 중요하게 사용되는 통계량의 충분성에 대해 정리하고자 한다. 확률공간 $(\Omega,\mathcal{F},P)$ 을 이용해 random experiment를 정의할 때, 우리는 확률측도 $P$를 population이라고 정의하기도 한다. 이때 random sample이란, 주어진 population $P$로부터 데이터를 생성하는 random...
Conditional Expectations Measure Theory를 기반으로 한 조건부 기댓값 및 조건부 확률을 정의해보도록 하자. 일반적으로 measure를 다루지 않는 통계학에서는 조건부 확률을 먼저 정의하고, 이후에 조건부 기댓값을 조건부 확률을 이용해 정의하는데 measure를 이용하면 좀 더 엄밀한 정의가 가능하다. 또한, 측도를 기반으로 한 새로운 조건부 기댓값의 정의와...
Stationarity 우리말로 정상성이라고 정의하는 Stationarity는 시계열 분석을 수행하기 위해 가정해야 하는 가장 중요한 도구이다. 회귀분석에 비유하자면, 회귀모형의 오차항(흔히 $\epsilon$으로 나타나는)이 정규성을 가진다고 가정하는 것과 비슷하다. 가장 단순한 (단변량) 시계열은 다음과 같이 시간 $t$에 대해 변화하는 확률변수의 sequence로 정의된다. $$...
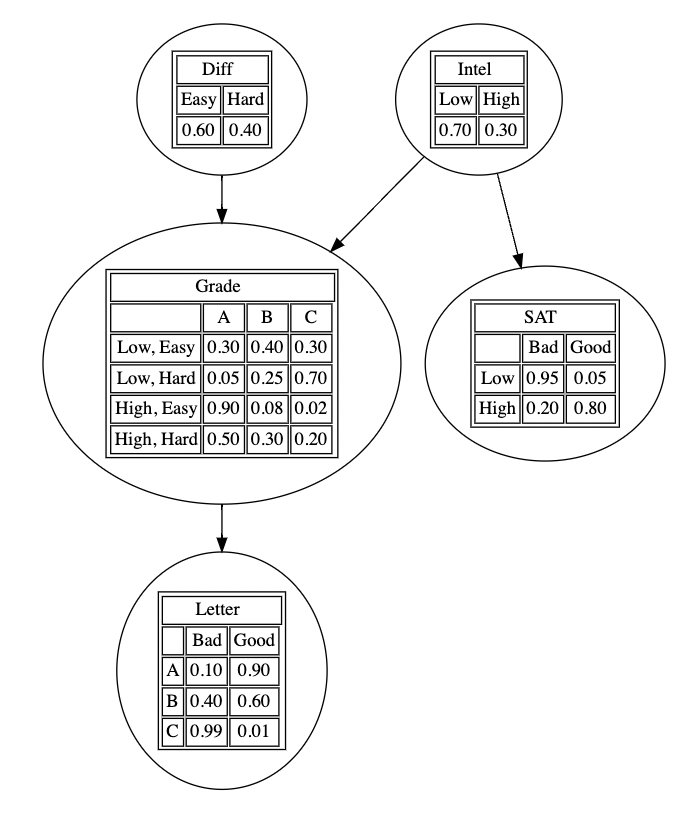
Probabilistic Graphical Models 이전에 graph의 markov property/)을 살펴보며 markov property 하에서(parent 노드가 주어질 때 다른 노드들과의 조건부 독립성) graphical model을 다음과 같은 markov chain 형태로 나타낼 수 있음을 알았다. $$ p(\mathbf x{1:V}) = \prod{i=1}^Vp{\th...
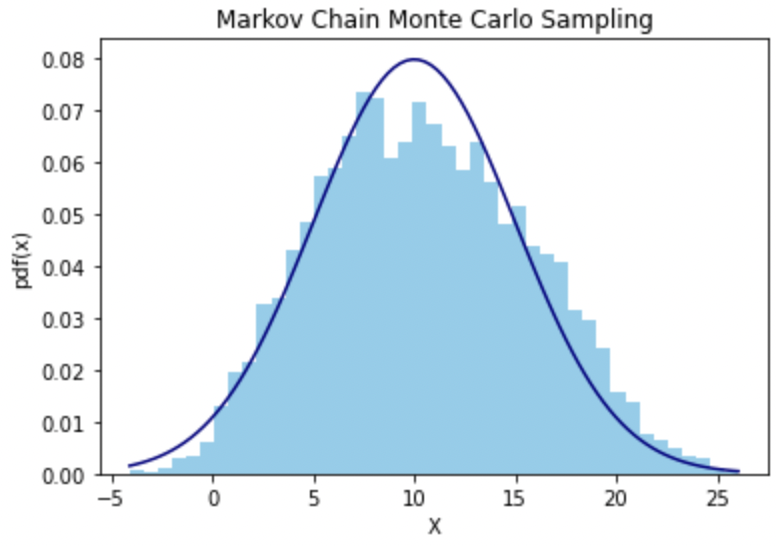
Markov Chain Monte Carlo MCMC라고도 하는 Markov Chain Monte Carlo 기법은 확률분포에서 샘플을 추출하는 여러 종류의 알고리즘을 일컫는다. 다양한 머신러닝 이론들이 등장하며, 기존 통계학에서 다룰 수 없을 정도의 수만-수백만 개의 변수 및 파라미터를 사용하는 모델들 역시 등장했고, 특히 신경망과 같은 모델들은 너무나도 널리 사용되고 있다. 하지만...
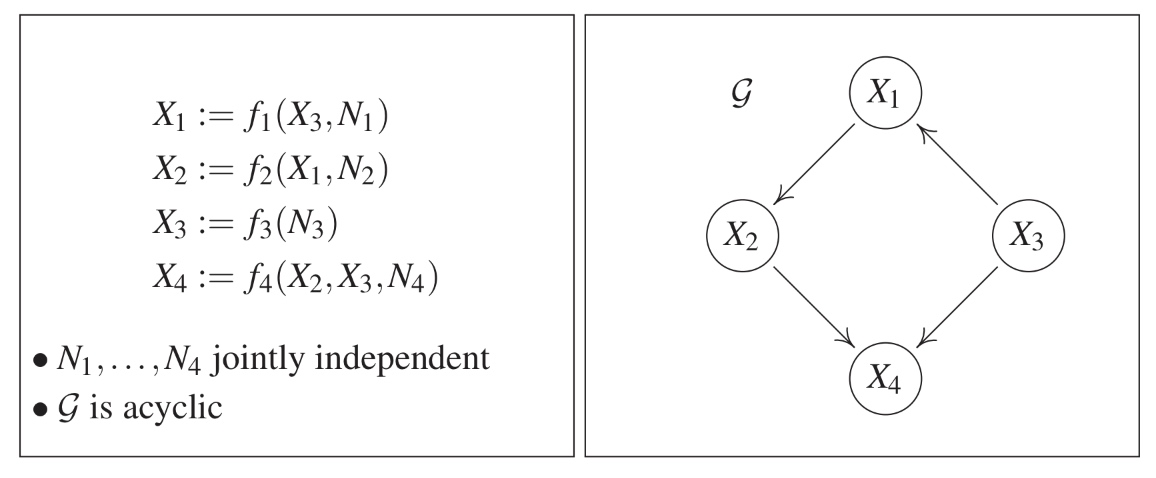
Multivariate Causal Models 이전까지는 변수가 2개인 SCM, 즉 원인-결과의 SCM을 살펴보았었다. 이제부터는 변수가 여러개인(multivariate) causal model들에 대해 살펴보도록 하자. 우선, cause-effect 모델도 포함되지만 다변량 causal model은 일반적으로 그래프(graph)의 형태로 표현된다. Graph의 정의 그래프란, 확률변...
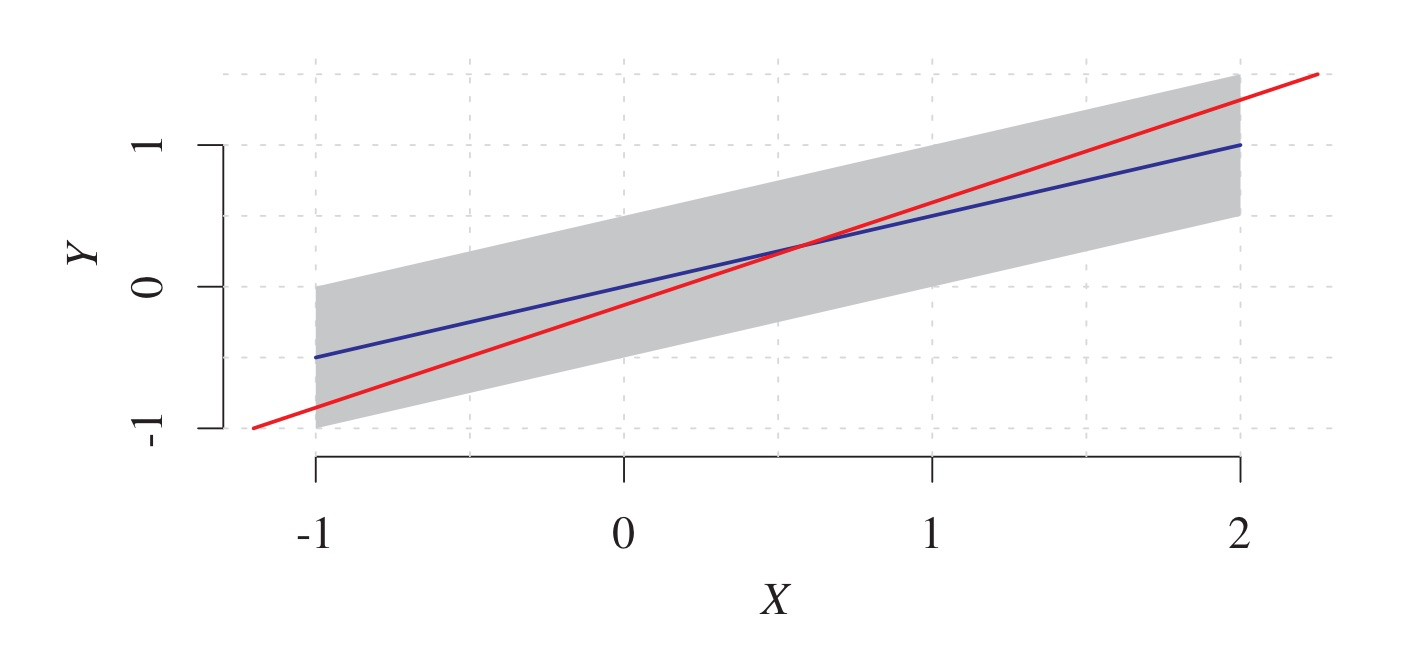
Learning Cause-Effect Models (2) 이번 게시글에서는 저번/)에 이어 다른 Cause-Effect 모델들과 이들의 식별가능성에 대해 계속 살펴보도록 하자. Post-nonlinear Models Post-nonlinear model은 이전에 살펴본 Nonlinear ANM의 일반화된 모델이다. 결합분포 $P{X,Y}$가 X에서 Y로의 post-nonlinear m...
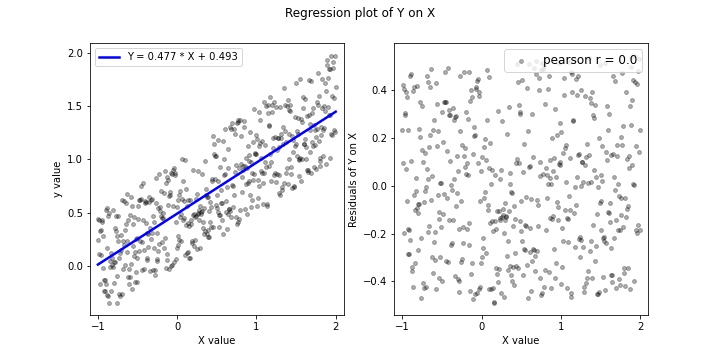
Learning Cause-Effect Models 통계적 학습이론(Statistical Learning)의 관점에서 살펴보면, 가장 간단한 케이스인 cause-effect model을 학습하는 것 조차 어려움이 존재한다. Statistical Learning은 소위 주어진 관측값 $(X,Y){i=1\ldots,N}$ 들로부터(observation) $X,Y$의 joint distrib...
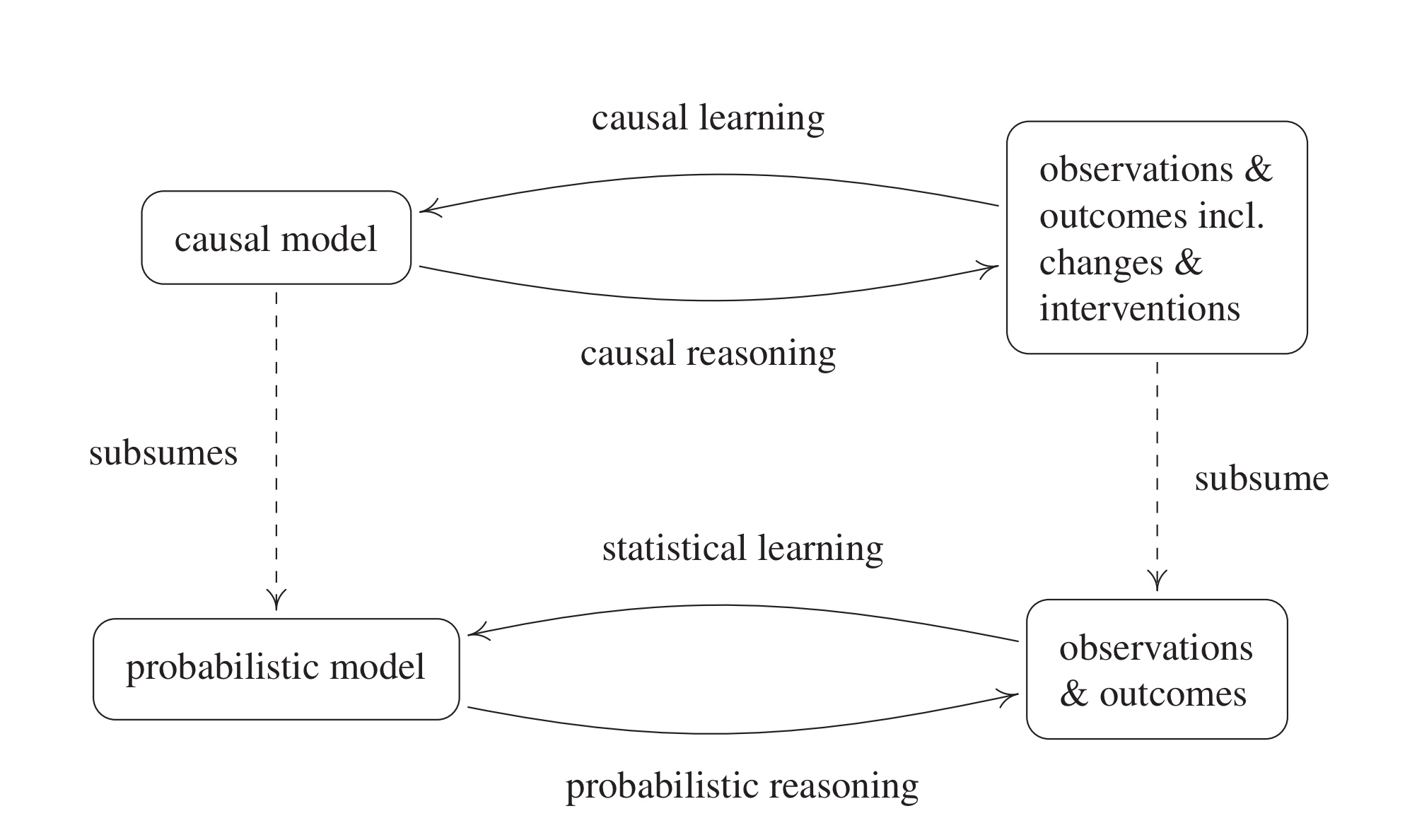
Causal Inference Causal Inference, 즉 인과관계추론은 통계학의 한 분야로 사회과학 등 다양한 분야에 응용될 수 있는 영역이다. 2021년 노벨경제학상이 인과관계추론 분야에서 수상되며 전통적인 방법론이었으면서도, 최근 통계학의 중요한 분야로 떠오르는 추세이다. 기존의 선형모형론부터 최근의 데이터사이언스 기법들은 대개 input data와 target variab...
Cause-Effect Model Structural Causal Model 줄여서 SCM이라고 하는 Structural Causal Model은 인과관계모델을 구조화한 표현이다. 여기서는 우선 원인(C)과 결과(E) 두 변수로 구성된 Cause-Effect 모델만을 다루고, 이에 대한 SCM을 다음과 같이 정의한다. Def. $C\to E$에 대한 SCM $\mathfrak C$는 두...
Bootstrap Methods Bootstrap 방법은 정확도(accuracy)를 측정하기 위해 사용되는 일반적인 방법이다. Cross-validation과 마찬가지로 bootstrap은 (conditional) test error $\text{Err}\mathcal T$ 를 추정하기 위해 사용되지만, 일반적으로 기대예측오차 $\text {Err}$ 만을 잘 추정해낸다. 정의 크기가...