AI 관련 개념정리
LLM, Vision 관련 자주 언급되는 개념 및 논문들을 통계학적인 시각에서 간략히 정리해보고 있습니다.
LLM-related concepts
Learning
In-Context Learning
Shot : 프롬프트에 포함되는 example case
- (zero-shot)
"""
한국어로 번역해 :
I am going to be the best AI model
"""
- (1-shot) : example 1개 포함
"""
Translate into Korean :
I am going to be the best AI model -> 나는 최고의 인공지능 모델이 될거야
Statistics is necessary for learning AI ->
"""
- In-context learning : few-shot learning에서와 같이 prompt 내부 케이스들(context)로부터 패턴을 학습하여 output을 도출
Chain-of-thought prompting(CoT)
수학 문제를 풀기 위해서는 step-by-step 형태의 사고 과정이 필요하며, 아래 예시와 같이 기존의 few-shot learning(Question -> 단순 Answer)로는 정답을 도출할 수 없는 문제를 해결하기 위해 정답을 도출하는 과정을 prompt에 포함하는 아이디어이다.
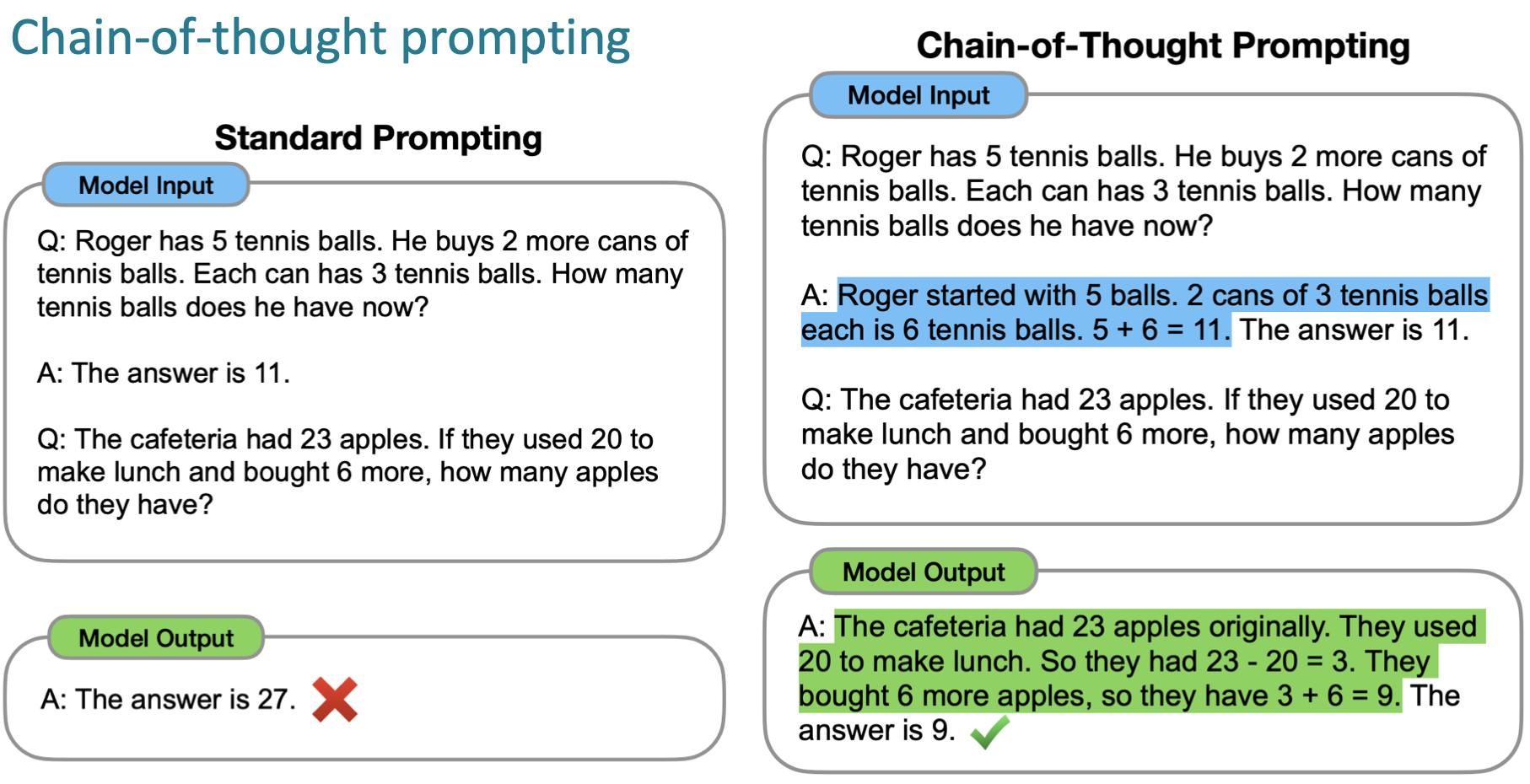
Zero-shot chain-of-thought prompting은, 위 예시에서 더 나아가 step별 task를 prompt로 제안하는 것이 아닌, LLM inference 결과로 대체한다. 다음과 같은 강점을 갖는다:
- Do not need few-shot example
- task-independent
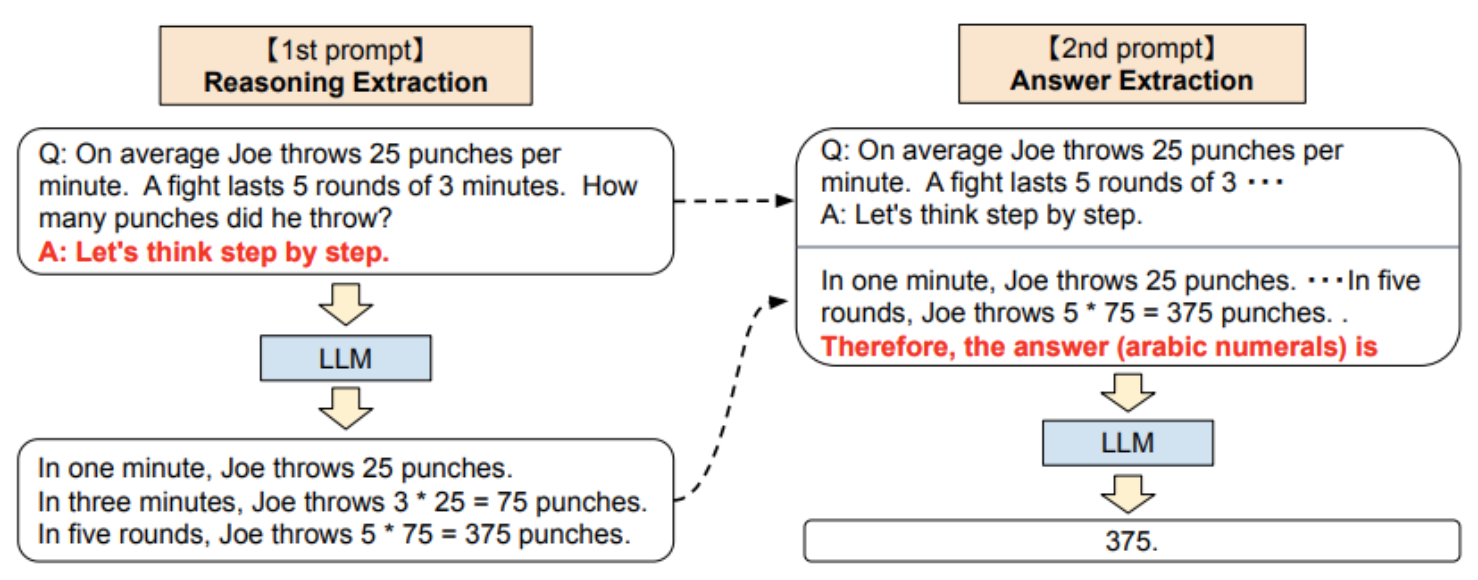
Kojima, Takeshi, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. “Large Language Models Are Zero-Shot Reasoners.” arXiv:2205.11916. Preprint, arXiv, January 29, 2023. https://doi.org/10.48550/arXiv.2205.11916.
Instruction tuning(Supervised Finetuning)
FLAN(Finetuned Language Models Are Zero-Shot Learners) : LM의 zero-shot learning 능력을 향상시키기 위해 제안
- Supervised finetuning이라는 명칭법에서 알 수 있듯, 파인튜닝 데이터로 task instruction과 output 쌍을 이용하여 학습
- Ouyang, Long, Jeff Wu, Xu Jiang, et al. “Training Language Models to Follow Instructions with Human Feedback.” arXiv:2203.02155. Preprint, arXiv, March 4, 2022. https://doi.org/10.48550/arXiv.2203.02155.
- Chung, Hyung Won, Le Hou, Shayne Longpre, et al. “Scaling Instruction-Finetuned Language Models.” arXiv.Org, October 20, 2022. https://arxiv.org/abs/2210.11416v5.
Temperature
- 모델의 창의성 X > 모델의 output 과정에서 확률적 선택을 얼마나 반영할 것인가를 조절하는 파라미터
- Temperature $t$에 대해, output 확률 분포 $P$는 logit $z$에 softmax를 적용하여 도출되며, softmax 내에서 $t$가 클수록 확률 분포가 평탄해짐
e.g.
$P(w_i = \text{“cat”} | w_{<i}) = 0.6, P(w_i = \text{“dog”} | w_{<i}) = 0.4$ 일 때,
- $t=0$ : argmax 선택 -> “cat” (No randomness)
- $t=0.5$ : “cat” 선택 확률 0.75, “dog” 선택 확률 0.25
- $t=1$ : “cat” 선택 확률 0.6, “dog” 선택 확률 0.4 …
인 식임
Embedding
Token Embedding
- Classical Token Embedding(ex. Word2Vec) : 고정된 embedding model(matrix)를 주어진 token vector에 곱해서 도출
-
Classical method는 동의어 등 맥락 반영 불가
-
Reality : embedding vector는 Last hidden state matrix의 mean vector로 도출됨(Mean pooling)
Positional Embedding(PE)
Classical PE : Transformer 모델에 위치 정보를 제공하기 위해 Token embedding에 더해지는 벡터
- Token embedding 이후 vector 추가 (Vaswani et al., 2017)
- ex. Sinusoidal PE
-
RoPE(Rotatory Positional Embedding) : 현재 De Facto standard (Su et al., 2023)
Transformer의 self-attention 메커니즘에 위치 정보를 통합하는 방법 (Input 단계에서 한번 더해지는 classical PE와 달리, attention score 계산 시점, 즉 모든 Transformer layer 내부에서 위치 정보를 반영)
-
원리
PE에서 $i$번째 position의 벡터 $\mathbf{x}_i$에 대해, query, key, value 벡터를
\[\mathbf{q}_i = f_q(\mathbf{x}_i, i),\quad \mathbf{k}_i = f_k(\mathbf{x}_i, i),\quad \mathbf{v}_i = f_v(\mathbf{x}_i, i)\]형태일때, query와 key의 내적이 distance-dependent하게 변형되도록 하는 것
\[\langle f_q(\mathbf{x}_m, m), f_k(\mathbf{x}_n, n) \rangle = g(\mathbf{x}_m, \mathbf{x}_n, m-n)\](2D case) 이는 다음과 같은 정의로부터 유도된다.
\[\begin{aligned} f_q(\mathbf{x}_m, m) &:= (W_q \mathbf{x}_m) e^{i \theta m} \\ f_k(\mathbf{x}_n, n) &:= (W_k \mathbf{x}_n) e^{i \theta n} \end{aligned}\]이때,
\[g(\mathbf{x}_m, \mathbf{x}_n, m-n) = \mathrm{Re}[(W_q \mathbf{x}_m)^{\top} (W_k \mathbf{x}_n) e^{i \theta (m-n)}]\]이므로, query와 key의 내적이 두 벡터의 위치 차이에 의존하게 된다. 이때, $e^{i \theta m}$는 벡터 $\mathbf{x}_m$를 2D 공간에서 $\theta m$만큼 회전시키는 연산이므로, RoPE는 각 벡터를 위치에 따라 회전시킨 후, query와 key를 계산하는 방법이라고 할 수 있다.
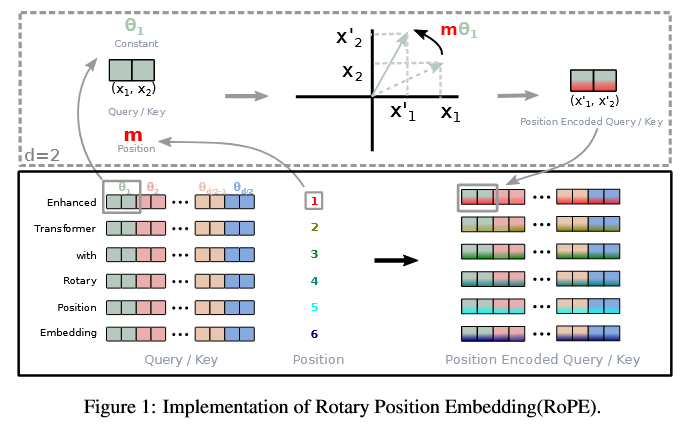
- Su, Jianlin, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv:2104.09864. Preprint, arXiv, November 8, 2023. https://doi.org/10.48550/arXiv.2104.09864.
PEFT
Low Intrinsic Dimension Hypothesis (Aghajanyan et al., 2020)
- $W_{0}\in \mathbb{R}^{d \times k}$ : Fixed, pre-trained weight matrix
- Full fine-tuning에서는 $W=W_{0}+ \Delta W$ 로 업데이트 하는데, LoRA에서는 update matrix $\Delta W$가 rank-deficicent하다고 가정
이때, forward pass는
\[\mathbf{h} = W \mathbf{x} = W_{0}\mathbf{x} + A(B\mathbf{x})\]이고 initialization은 $A=0, B \sim \mathcal{N}(0,\sigma^2)$ 로 설정
$B$는 입력 차원에서 저차원 잠재 공간으로의 투영(projection), $A$는 잠재 공간에서 출력 차원으로의 복원(reconstruction)을 담당
직관적으로, “Summarize legal contract”와 같은 구체적인 task에서는 “legal” 관련 정보만 추출하는 것이 중요할 수 있으므로, “coding, humor, literature” 등 다른 분야의 정보는 저차원 잠재 공간으로 투영(projection)하는 과정에서 제거될 수 있음
Implementation
class LoRALayer(nn.Module):
def __init__(self, input_dim, output_dim, rank=4, alpha=8):
super().__init__()
# 1. Pre-training된 Weight Matrix W0
self.w0 = nn.Linear(input_dim, output_dim, bias=False)
# 중요: W0는 고정(frozen)되어야 함
self.w0.weight.requires_grad = False
# 2. The LoRA Matrices (A, B)
self.lora_A = nn.Parameter(torch.randn(rank, input_dim))
self.lora_B = nn.Parameter(torch.zeros(output_dim, rank))
# Scaling factor (hyperparameter)
self.scaling = alpha / rank
def forward(self, x):
original_output = self.w0(x)
lora_output = (x @ self.lora_A.T) @ self.lora_B.T * self.scaling
return original_output + lora_output
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.1) # Only LoRA parameters will be updated
Agent
- Agent : LLM을 활용하여 여러 도구(tool)를 사용하여 문제를 해결하는 시스템
- (Yao et al., 2023) : ReAct (Reasoning + Acting) :
- LLM이 reasoning과 acting을 번갈아 수행하도록 설계
- Reasoning : 문제 해결을 위한 사고 과정 (ex. 질문 분석, 계획 수립)
- Acting : 외부 도구(tool)를 활용하여 실제 작업 수행 (ex. 검색, 계산)
- ReAct 프레임워크는 LLM이 reasoning과 acting을 반복적으로 수행하여 복잡한 문제를 해결할 수 있도록 함
Example Let’s trace an Agent answering: “Who is the CEO of the company that invented the iPhone, and what is their age raised to the 0.2 power?
“Step 1: Thought (Reasoning)LLM: “I need to find the company that invented the iPhone first. I should search for this.
“Step 2: Action (Tool Use)Agent: Calls GoogleSearch(“iPhone inventor company”)
Step 3: Observation (Feedback)Environment: Returns “Apple Inc.”
Step 4: ThoughtLLM: “Now I know the company is Apple. I need to find the current CEO of Apple.”
Step 5: ActionAgent: Calls GoogleSearch(“current CEO of Apple”)
Step 6: ObservationEnvironment: Returns “Tim Cook”.
Step 7: ThoughtLLM: “I need Tim Cook’s age. Then I will calculate the power.”
Step 8: ActionAgent: Calls GoogleSearch(“Tim Cook age”) $\to$ Returns “63”.Agent: Calls Calculator(63 ** 0.2)
Step 9: Final AnswerLLM: “The answer is 2.29.”
- Yao, Shunyu, Jeffrey Zhao, Dian Yu, et al. 2023. “ReAct: Synergizing Reasoning and Acting in Language Models.” arXiv:2210.03629. Preprint, arXiv, March 10. https://doi.org/10.48550/arXiv.2210.03629.
Reasoning
RLHF(Reinforcement Learning with Human Feedback)
3단계 phase로 보기
-
Supervised Fine-tuning (SFT) : 사람이 작성한 (instruction, output) 쌍을 이용하여 사전학습된 LLM을 미세조정 > Reference model $\pi_{SFT}$
-
Reward Modeling (RM)
-
데이터 수집 : 사람이 작성한 (instruction, output1, output2) 쌍을 이용하여, output1과 output2 중 어느 것이 더 나은지에 대한 피드백 수집 > ${\mathrm{prompt}, y_{\mathrm{win}}, y_{\mathrm{lose}}}$
-
보상 모델 학습 : Latent utility function $r_\phi(x,y) \in \mathbb{R}$이 있다고 가정. Bradley-Terry(BT) 모델을 활용하여 다음과 같이 선호도 확률 모델링
- 이때, $\sigma(\cdot)$는 sigmoid 함수이며, 보상 모델 파라미터 $\phi$는 다음과 같은 로그우도 최대화로 추정
- Reinforcement Learning (RL)
RAG(Retrieval-Augmented Generation)
Standard RAG
: 사전학습된 LLM이 외부 지식베이스(문서 집합)로부터 관련 정보를 검색하여 답변 생성에 활용하는 방법
\[P(y|x) \approx \sum_{d\in \mathrm{Top-K}(x)} P_\theta(y|x,d) \times P_{\mathrm{retrieval}}(d|x)\]Mechanism :
- Embedding : 입력 질문 $x$와 문서 집합 ${d_i}$를 임베딩 벡터로 변환
- Retrieval : 질문 임베딩과 문서 임베딩 간의 유사도를 계산하여 Top-K 문서 선택
- Generation : 선택된 문서들을 컨텍스트로 사용하여 LLM이 답변 생성
GraphRAG
문서들 간의 관계를 지식 그래프(Knowledge Graph, KG) $G=(V,E)$ 형태로 표현하여, RAG의 검색 및 생성 과정을 향상시키는 방법
Ontology
온톨로지란, 특정 도메인 내에서 개체(Entity)와 그들 간의 관계(Relation)를 체계적으로 정의한 구조화된 지식 표현 방식
DB에서 table schema와 유사하게, 온톨로지는 개체 유형, 속성, 관계 등을 사전에 정의하여 중복된 노드, 엣지 생성을 방지하고, 일관된 지식 표현을 가능하게 함
Graph Construction
- LLM을 이용한 텍스트 가공 및 tuple($head$, $relation$, $tail$) 추출
- Ex input) “Apple announced the M3 chip”
- Ex output) (Apple, ANNOUNCED, M3 chip)
- 동일한 노드는 하나의 entity로 병합 (e.g. Apple Inc. = Apple)
Data Structure : LPG(Labeled Property Graph)
- 각 node, edge에 key-value 형태의 속성(property) 추가
- ex. 노드
{Entity : "Apple Inc."}은{"Type" : "Company"}속성 가짐 - 각 엣지는 방향성 가짐(Directed Graph)
Retrieval
- Local Search : K-hop Traversal(BFS)
ex. 유저가 “Who is the CEO of the company that invented the iPhone?” 질문 시, $v_{iPhone}$ 찾기(시작 노드) > $v_{Apple}$ (1-hop 이웃 노드) > $v_{Tim Cook}$ (2-hop 이웃 노드)
- Global Search
- Map-Reduce over Communities
ex. “Summarize the advancements in AI over the past decade.” Level 2 Community들에 분산하여 “Is this cluster relevant to AI advancements?” 질문 수행 > 관련된 community들로부터의 결과를 LLM이 종합하여 답변 생성
- Edge, Darren, Ha Trinh, Newman Cheng, et al. 2025. “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” arXiv:2404.16130. Preprint, arXiv, February 19. https://doi.org/10.48550/arXiv.2404.16130.
최근에는 일반적으로 HybridRAG (Vector RAG + GraphRAG) 형태로 활용됨
Graph Algorithms
Approximate Nearest Neighbor (ANN) Search
-
Retrieval 단계에서 유사한 노드(문서)들을 빠르게 찾기 위해 사용
-
그래프 탐색을 시작할 때 전체 그래프를 탐색하지 않음. 대신 “Anchor node” 필요
Query $q$를 vector $\mathbf{v}_q$로 임베딩
ANN search (ex. HNSW) : 노드의 text attribute가 임베딩된 벡터와 유사한 노드들을 빠르게 검색
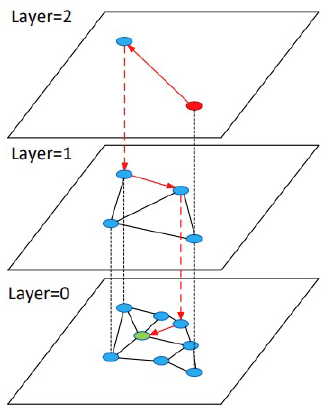 HNSW
HNSW
PageRank (and Personalized PageRank)
- Context Pruning & Prioritization : 그래프 내에서 중요한 노드(문서)들을 식별하여, Retrieval 단계에서 우선적으로 고려
- Subgraph를 retreieval한 경우, (ex. 50개 노드로 구성된 subgraph), 모든 노드와 엣지를 LLM에 제공하는 것은 비효율적일 수 있으므로, Scoring 기법으로 중요한 노드들을 선별
Standard PageRank
\[PR(v) = \alpha \sum_{u \in \mathrm{Pa}(v)} \frac{PR(u)}{|\mathrm{Ch}(u)|} + (1-\alpha) \frac{1}{N}\]- 여기서, $\mathrm{Pa}(v)$는 노드 $v$의 부모 노드 집합, $\mathrm{Ch}(u)$는 노드 $u$의 자식 노드 집합, $N$은 그래프 내 전체 노드 수, $\alpha$는 damping factor (일반적으로 0.85로 설정)
Leave a comment