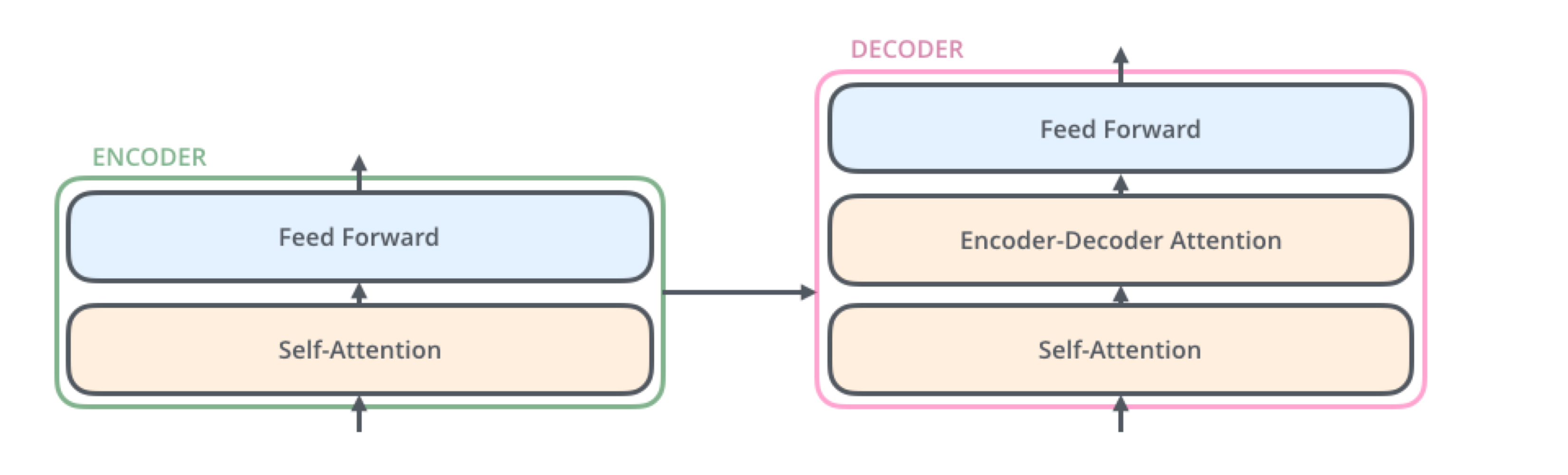
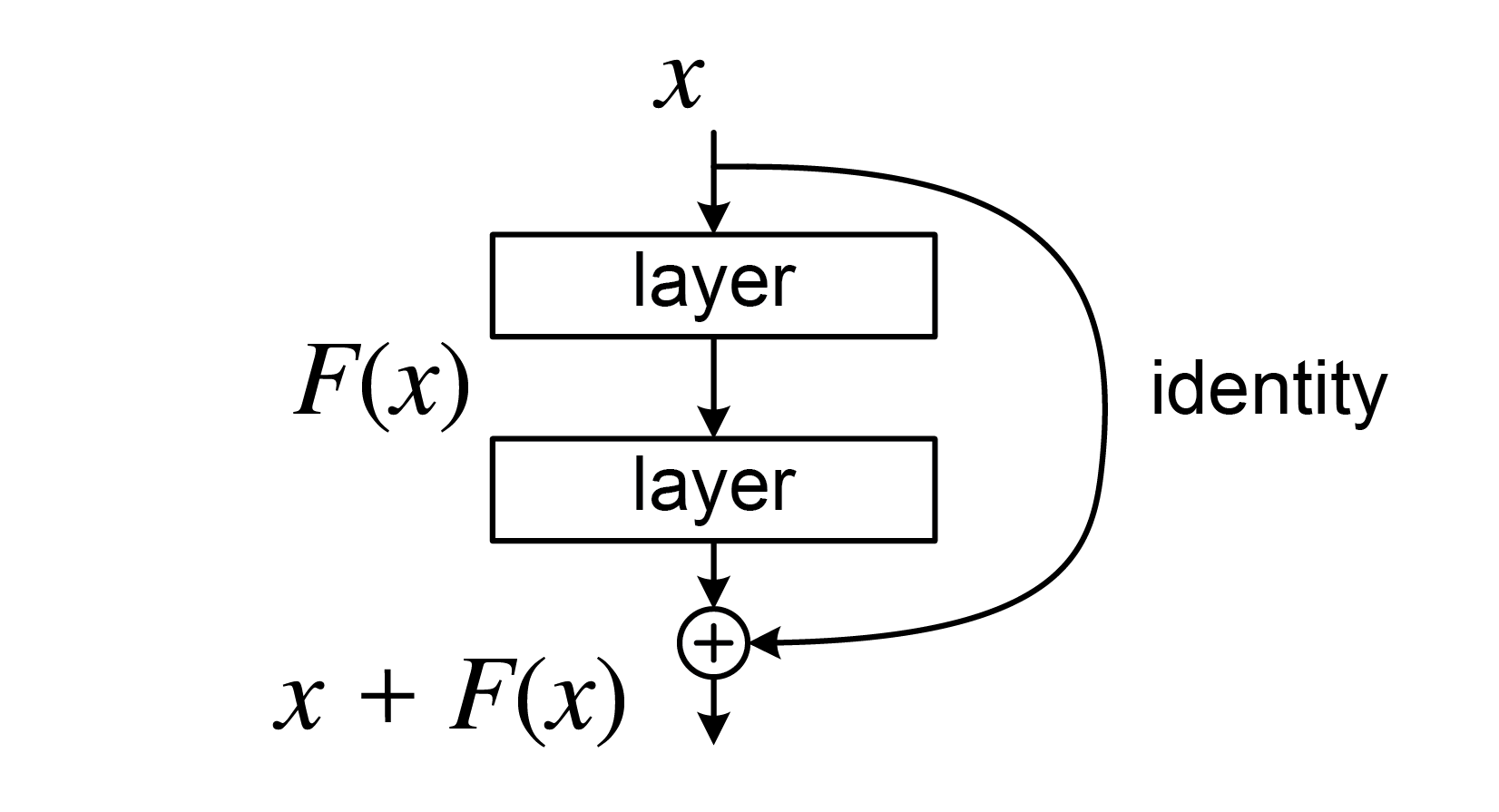
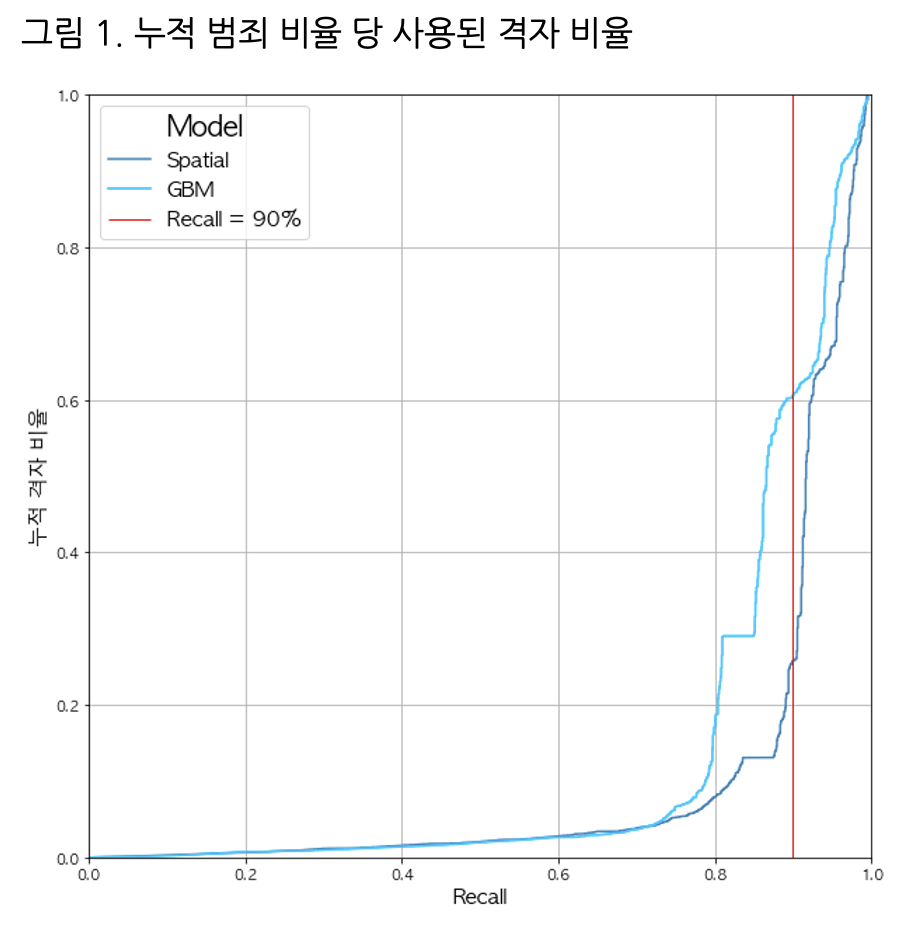
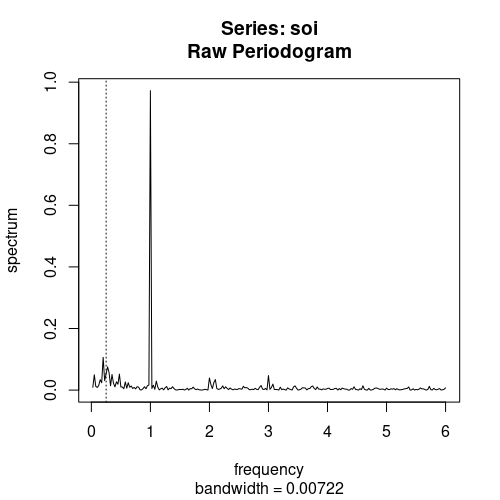
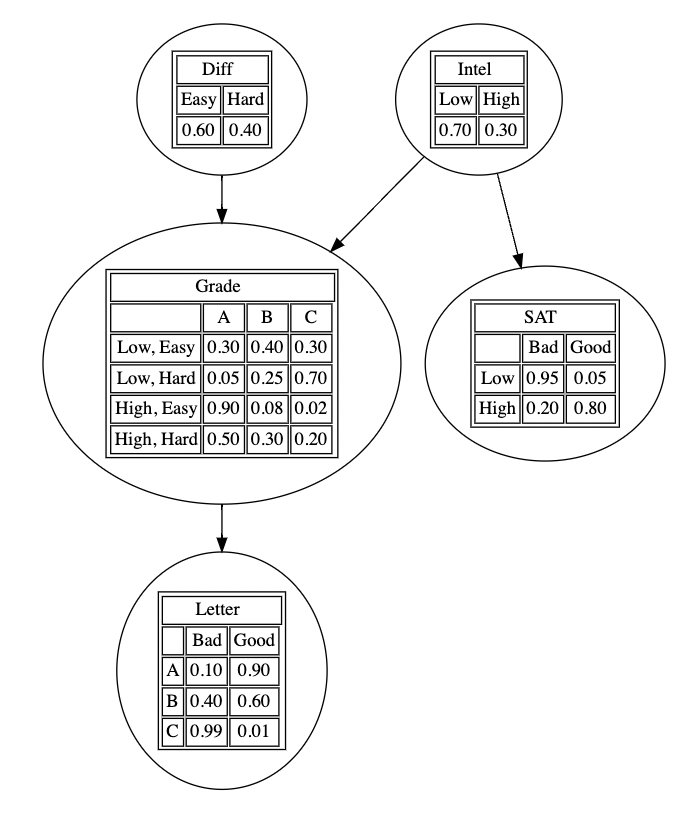
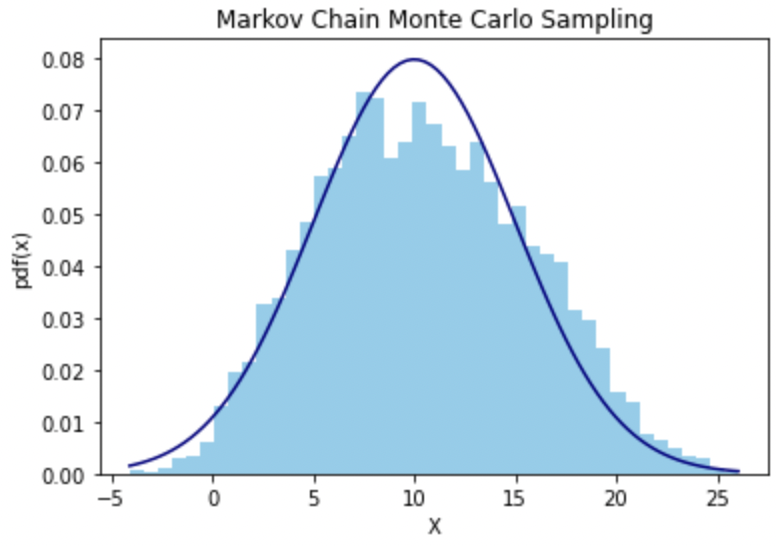
2026. 1. 20.Archive
Policy Optimization
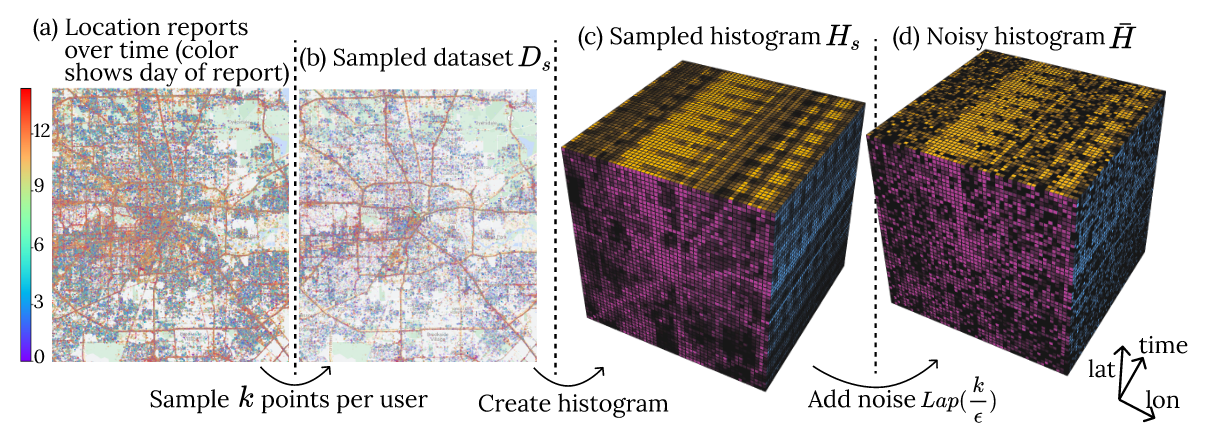
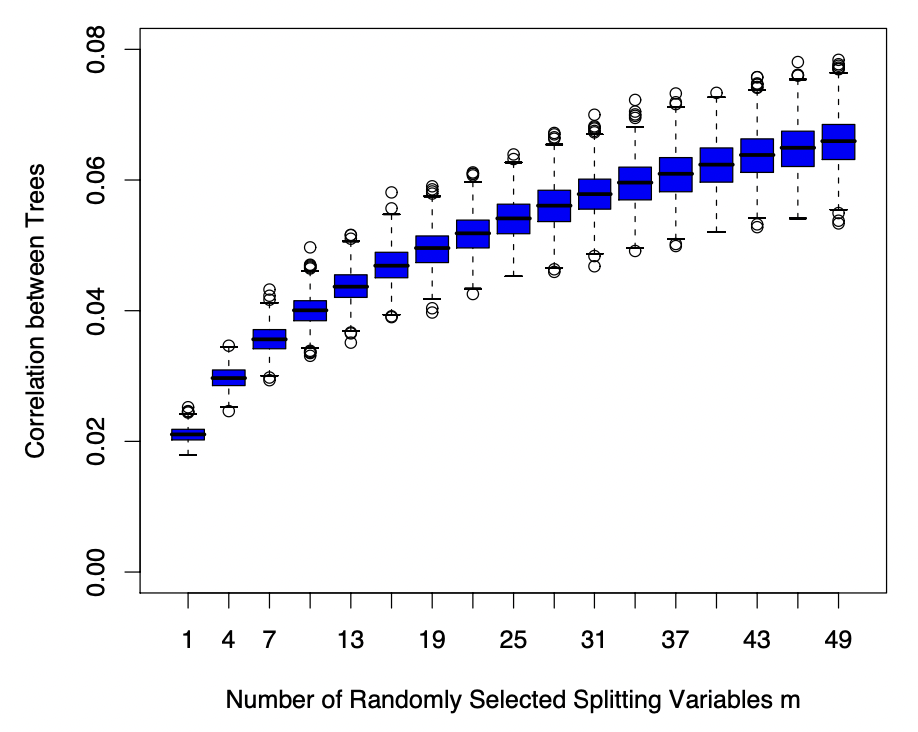
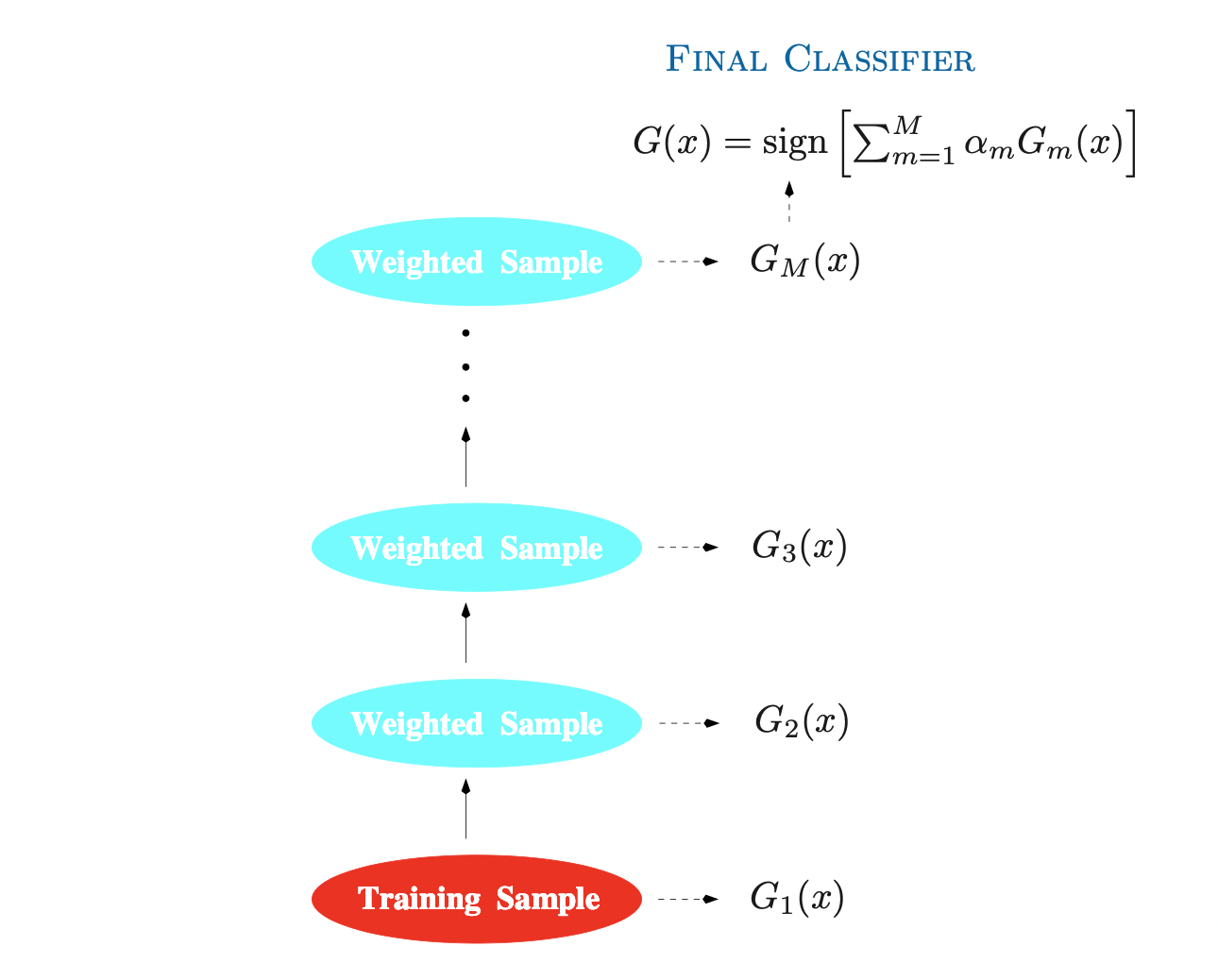
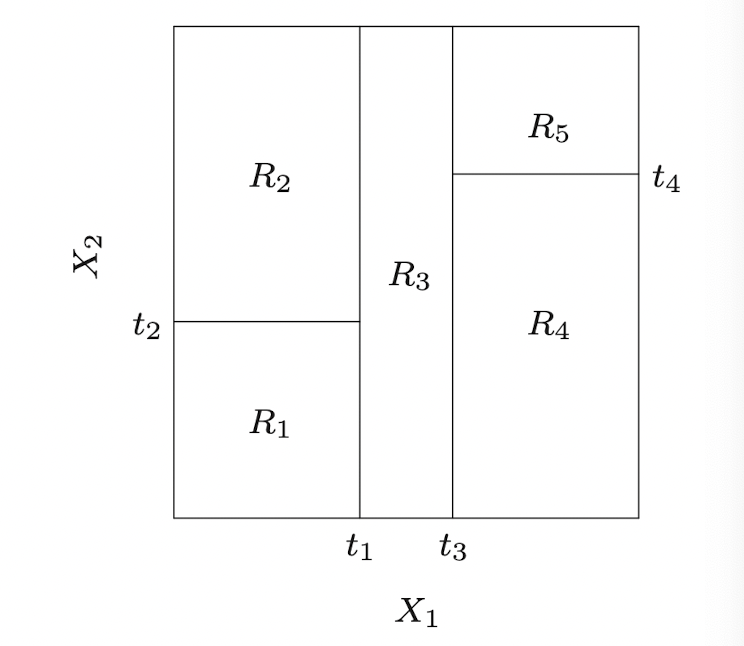
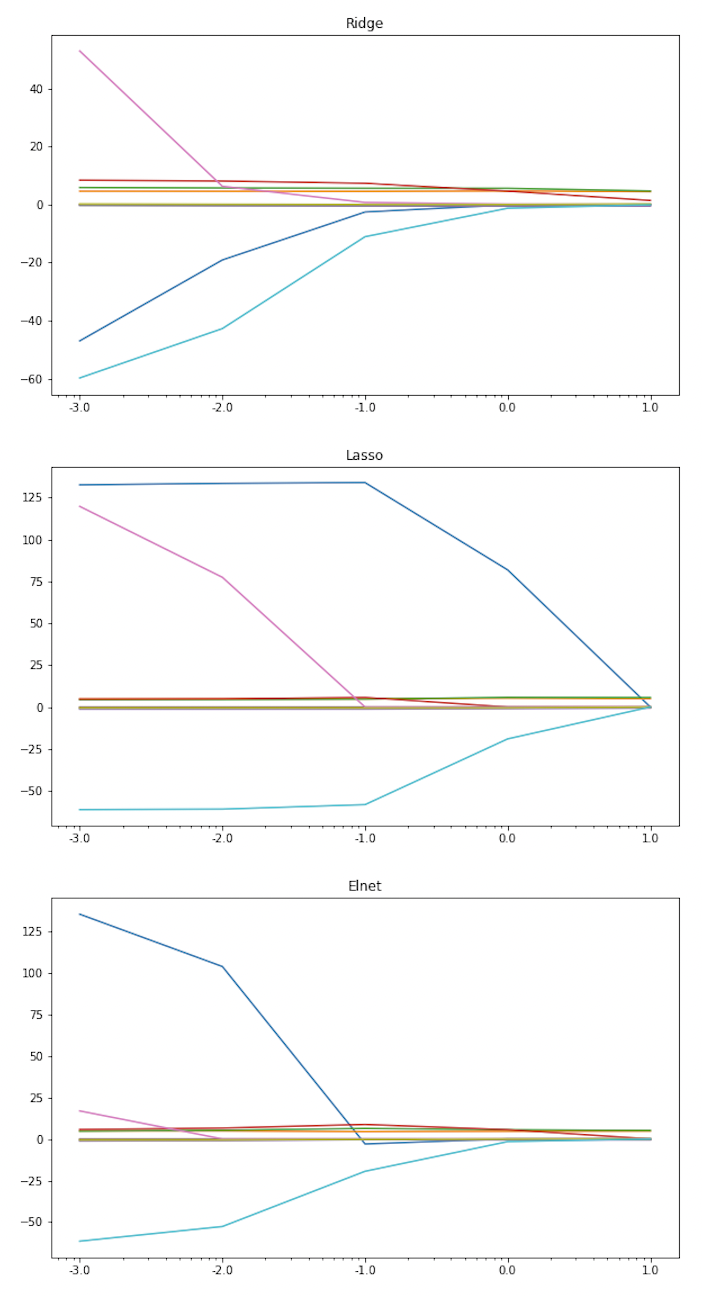
Setting 통계학적인 관점에서, 강화학습(RL)은 uncertainty 하에서 이루어지는 sequential decision making 혹은 dynamic optimization 이라고 할 수 있다. 일반적인 supervised learning 세팅에서는 관측 데이터 $(X,Y)$ 쌍들로부터 conditional distribution $\Pr(Y|X)$ 를 학습하는 것인 반면,...
- Reinforcement Learning
- Deep Learning