최근 Mamba (Gu & Dao, 2024)의 등장으로 상태공간모형(State-Space Model, 이하 SSM)은 Transformer 를 대체할 수 있는 아키텍처의 후보로 여겨지고 있습니다. 이번 글에서는 보다 일반적인 상태공간모형과, 이를 딥러닝에 적용한 S4, HiPPO 등의 아키텍쳐에 대해 다루어보도록 하겠습니다.
State Space Model
Revisit: State Space Model in Time Series Analysis
통계학에서 다루는 상태공간모형 (State-Space Model, 이하 SSM)은 일반적인 SSM을 불연속적인 Markov chain 으로 변환한 것으로, 관측가능한 데이터 y t , x t \mathbf{y}_{t}, \mathbf{x}_{t} y t , x t h t \mathbf{h}_{t} h t
{ h t = Φ h t − 1 + γ x t + w t y t = A t h t + Γ x t + v t \begin{cases}
\mathbf{h}_{t} = \Phi\mathbf{h}_{t-1}+\gamma \mathbf{x}_{t}+w_{t}\\
\mathbf{y}_{t} = A_{t}\mathbf{h}_{t}+\Gamma\mathbf{x}_{t}+ v_{t}
\end{cases} { h t = Φ h t − 1 + γ x t + w t y t = A t h t + Γ x t + v t 이때 noise vector w t , v t w_{t}, v_{t} w t , v t N p ( 0 , Q ) , N q ( 0 , R ) N_{p}(0,Q), N_q(0,R) N p ( 0 , Q ) , N q ( 0 , R ) 정규성 가정 (Gaussian assumption)은 상태공간모형에서 매우 중요합니다. 이렇게 주어지는 상태공간모형은 Kalman Filter 로 hidden state를 추정할 수 있습니다.
시퀀스로 주어지는 hidden state h t \mathbf{h}_t h t RNN Recurrent Neural Network 과 유사한 구조를 가지고 있습니다 (Elman network).
h t = σ h ( W h x t + U h h t − 1 + b h ) y t = σ y ( W y h t + b y ) \begin{aligned}
\mathbf{h}_t &= \sigma_h(\mathbf{W}_h\mathbf{x}_t + \mathbf{U}_h\mathbf{h}_{t-1} + \mathbf{b}_h)\\
\mathbf{y}_t &= \sigma_y(\mathbf{W}_y\mathbf{h}_t + \mathbf{b}_y)
\end{aligned} h t y t = σ h ( W h x t + U h h t − 1 + b h ) = σ y ( W y h t + b y ) State Space Model
SSM representation. Source: [wikipedia](https://en.wikipedia.org/wiki/State-space_representation)
앞서 다룬 시계열 데이터 분석에서의 SSM은 discrete-time 상태공간모형입니다. 일반적인 형태의 상태공간모형은 continuous-time SSM 으로, 이는 다음과 같이 미분방정식 형태로 주어집니다.
{ x ˙ ( t ) = A x ( t ) + B u ( t ) y ( t ) = C x ( t ) + D u ( t ) \begin{cases}
\dot{\mathbf{x}}(t) = A\mathbf{x}(t) + B\mathbf{u}(t)\\
\mathbf{y}(t) = C\mathbf{x}(t) + D\mathbf{u}(t)
\end{cases} { x ˙ ( t ) = A x ( t ) + B u ( t ) y ( t ) = C x ( t ) + D u ( t ) 이때, x ( t ) \mathbf{x}(t) x ( t ) u ( t ) \mathbf{u}(t) u ( t ) y ( t ) \mathbf{y}(t) y ( t )
딥러닝 모델들에서 다루는 SSM은 두번째 식인 output의 출력 과정을 간단하게 변형한 형태로 주어집니다.
{ x ˙ ( t ) = A x ( t ) + B u ( t ) y ( t ) = C x ( t ) \begin{cases}
\dot{\mathbf{x}}(t) = \mathbf{A}\mathbf{x}(t) + \mathbf{B}\mathbf{u}(t)\\
\mathbf{y}(t) = \mathbf{C}\mathbf{x}(t)
\end{cases} { x ˙ ( t ) = Ax ( t ) + Bu ( t ) y ( t ) = Cx ( t ) 위 미분방정식의 해는 variation of parameters 를 사용하여 다음과 같이 계산됩니다.
x ( t ) = e A t x ( 0 ) + ∫ 0 t e A ( t − τ ) B u ( τ ) d τ \mathbf{x}(t) = e^{At}\mathbf{x}(0) + \int_{0}^{t}e^{A(t-\tau)}\mathbf{B}\mathbf{u}(\tau)d\tau x ( t ) = e A t x ( 0 ) + ∫ 0 t e A ( t − τ ) Bu ( τ ) d τ Discretization
실제로 위 SSM을 딥러닝 모델로 구현할 때에는, continuous-time SSM을 discrete-time SSM으로 변환하여 사용해야 합니다. 이러한 과정을 discretization 이라고 하는데 (아래 그림 참고), 이를 통해 continuous-time SSM을 RNN과 같은 구조로 변환하여 사용할 수 있습니다.
Source: https://hazyresearch.stanford.edu/blog/2022-01-14-s4-3
임의의 t ≥ 0 , Δ t > 0 t\ge 0, \Delta t >0 t ≥ 0 , Δ t > 0
x ˙ ( t ) = A x ( t ) + B u ( t ) \dot{\mathbf{x}}(t) = A\mathbf{x}(t) + B\mathbf{u}(t) x ˙ ( t ) = A x ( t ) + B u ( t ) 의 해는 다음을 만족합니다.
x ( t + Δ t ) = x ( t ) + ∫ t t + Δ t A x ( τ ) d τ + ∫ t t + Δ t B u ( τ ) d τ \mathbf{x}(t+\Delta t) = \mathbf{x}(t) + \int_{t}^{t+\Delta t}A\mathbf{x}(\tau)d\tau + \int_{t}^{t+\Delta t}B\mathbf{u}(\tau)d\tau x ( t + Δ t ) = x ( t ) + ∫ t t + Δ t A x ( τ ) d τ + ∫ t t + Δ t B u ( τ ) d τ 이때 적분을 근사하기 위해 다음과 같은 방법들이 사용됩니다.
Forward Euler discretization:
x ( t + Δ t ) ≈ ( I + Δ t A ) x ( t ) + Δ t B u ( t ) \mathbf{x}(t+\Delta t) \approx (I+\Delta tA)\mathbf{x}(t) + \Delta tB\mathbf{u}(t) x ( t + Δ t ) ≈ ( I + Δ t A ) x ( t ) + Δ tB u ( t )
Backward Euler discretization:
x ( t + Δ t ) ≈ ( I − Δ t A ) − 1 x ( t ) + Δ t ( I − Δ t A ) − 1 B u ( t ) \mathbf{x}(t+\Delta t) \approx (I-\Delta tA)^{-1}\mathbf{x}(t) + \Delta t(I-\Delta tA)^{-1}B\mathbf{u}(t) x ( t + Δ t ) ≈ ( I − Δ t A ) − 1 x ( t ) + Δ t ( I − Δ t A ) − 1 B u ( t )
Bilinear discretization:
x ( t + Δ t ) ≈ ( I − Δ t 2 A ) − 1 ( I + Δ t 2 A ) x ( t ) + Δ t ( I − Δ t 2 A ) − 1 B u ( t ) \mathbf{x}(t+\Delta t) \approx \left(I-\frac{\Delta t}{2}A\right)^{-1}\left(I+\frac{\Delta t}{2}A\right)\mathbf{x}(t) + \Delta t\left(I-\frac{\Delta t}{2}A\right)^{-1}B\mathbf{u}(t) x ( t + Δ t ) ≈ ( I − 2 Δ t A ) − 1 ( I + 2 Δ t A ) x ( t ) + Δ t ( I − 2 Δ t A ) − 1 B u ( t )
Generalized bilinear discretization: For α ∈ ( 0 , 1 ) \alpha\in(0,1) α ∈ ( 0 , 1 )
x ( t + Δ t ) ≈ ( I − α Δ t A ) − 1 ( I + ( 1 − α ) Δ t A ) x ( t ) + Δ t ( I − α Δ t A ) − 1 B u ( t ) \mathbf{x}(t+\Delta t) \approx \left(I-\alpha\Delta tA\right)^{-1}\left(I+(1-\alpha)\Delta tA\right)\mathbf{x}(t) + \Delta t\left(I-\alpha\Delta tA\right)^{-1}B\mathbf{u}(t) x ( t + Δ t ) ≈ ( I − α Δ t A ) − 1 ( I + ( 1 − α ) Δ t A ) x ( t ) + Δ t ( I − α Δ t A ) − 1 B u ( t )
HiPPO
우선 현재 사용되는 SSM 모델의 근간이 되는 HiPPO (Gu et al., 2020) 에 대해 알아보도록 하겠습니다. HiPPO는 High-order Polynomial Projection Operator 의 약자로, RNN의 단점을 극복하기 위해 제안된 모델입니다.
현재 사용되는 언어 모델의 de facto standard 는 Transformer 입니다. Transformer의 등장 이전에는 RNN(Recurrent Neural Network)이 그 역할을 수행하였는데, RNN은 데이터를 순차적으로 처리하는 특성상 병렬화가 어렵다는 단점이 있었습니다.
또한, LSTM 과 같은 RNN 구조는 sequence 정보를 보존하긴 하지만, 긴 시퀀스에 대한 정보를 잘 보존하지 못한다는 단점이 있습니다. 다만, RNN 구조는 시퀀스 생성에서는 계산 비용 측면에서 transformer에 비해 큰 장점을 갖습니다. Generation cost가 시퀀스 길이에 선형적으로 증가하기 때문입니다 (O ( n ) O(n) O ( n )
HiPPO는 이러한 RNN의 장점을 유지하면서, 시퀀스 정보에 대한 기억(memory) 문제를 해결하기 위해 제안된 구조입니다.
Memory Units
Memory 문제를 해결하기 위해, HiPPO는 memory units 라는 개념을 이용합니다. 이는 Voelker et al. (2019) 에서 제안된 것으로, memory unit c ( t ) c(t) c ( t ) f ≤ t = { f ( τ ) } τ ∈ [ 0 , t ] f_{\le t}=\{f(\tau)\}_{\tau\in[0,t]} f ≤ t = { f ( τ ) } τ ∈ [ 0 , t ] c ( t ) c(t) c ( t ) c l c_l c l
c ( t ) ↦ f ^ ≤ t c(t) \mapsto \hat{f}_{\le t} c ( t ) ↦ f ^ ≤ t 가 존재하여 f ^ ≤ t ≈ f ≤ t \hat{f}_{\le t} \approx f_{\le t} f ^ ≤ t ≈ f ≤ t HiPPO 에서는 c ( t ) ∈ R N c(t)\in \mathbb{R}^N c ( t ) ∈ R N g g g f ≤ t f_{\le t} f ≤ t
g ( t ) ( x ) = ∑ i = 0 N − 1 c i ( t ) P i ( t ) ( x ) g^{(t)}(x) = \sum_{i=0}^{N-1}c_i(t)P_i^{(t)}(x) g ( t ) ( x ) = i = 0 ∑ N − 1 c i ( t ) P i ( t ) ( x ) 이때, basis function P i ( t ) ( x ) P_i^{(t)}(x) P i ( t ) ( x ) t t t i i i [ 0 , t ] [0,t] [ 0 , t ] μ ( t ) \mu^{(t)} μ ( t )
∥ f ≤ t − g ( t ) ∥ μ ( t ) \Vert f_{\le t} - g^{(t)} \Vert_{\mu^{(t)}} ∥ f ≤ t − g ( t ) ∥ μ ( t ) 를 최소화하는 c ( t ) c(t) c ( t ) c i ( t ) c_i(t) c i ( t )
c i ( t ) = ⟨ f , P i ( t ) ⟩ μ ( t ) = ∫ 0 t f ( x ) P i ( t ) ( x ) d μ ( t ) ( x ) = ∫ 0 t f ( x ) P i ( t ) ( x ) ω ( t , x ) d x \begin{aligned}
c_i(t) &= \langle f, P_i^{(t)} \rangle_{\mu^{(t)}} \\
&= \int_0^t f(x)P_i^{(t)}(x)d\mu^{(t)}(x) \\
&= \int_0^t f(x)P_i^{(t)}(x) \omega(t,x) dx
\end{aligned} c i ( t ) = ⟨ f , P i ( t ) ⟩ μ ( t ) = ∫ 0 t f ( x ) P i ( t ) ( x ) d μ ( t ) ( x ) = ∫ 0 t f ( x ) P i ( t ) ( x ) ω ( t , x ) d x 여기서 ω ( t , x ) \omega(t,x) ω ( t , x ) μ ( t ) \mu^{(t)} μ ( t )
매 step t t t c ( t ) c(t) c ( t ) c ( t ) c(t) c ( t ) ODE 를 따른다는 것을 보였습니다.
c ˙ ( t ) = A ( t ) c ( t ) + B ( t ) f ( t ) \dot{c}(t) = \mathbf{A}(t)c(t) + \mathbf{B}(t)f(t) c ˙ ( t ) = A ( t ) c ( t ) + B ( t ) f ( t ) 이때, A ( t ) , B ( t ) \mathbf{A}(t), \mathbf{B}(t) A ( t ) , B ( t ) N × N , N × 1 N\times N, N\times 1 N × N , N × 1 μ ( t ) \mu^{(t)} μ ( t )
HiPPO-LegT
첫 번째 경우는 최근 τ \tau τ
ω ( t , x ) = 1 τ 1 [ t − τ , t ] ( x ) \omega(t,x) = \frac{1}{\tau}\mathbf{1}_{[t-\tau,t]}(x) ω ( t , x ) = τ 1 1 [ t − τ , t ] ( x ) 와 다음과 같이 정의되는 Legendre polynomial basis
P 0 ( x ) = 1 P 1 ( x ) = x ( 1 − x 2 ) P n ′ ′ ( x ) − 2 x P n ′ ( x ) + n ( n + 1 ) P n ( x ) = 0 \begin{aligned}
&P_0(x) = 1\\
&P_1(x) = x\\
&(1-x^2)P_n''(x) - 2xP_n'(x) + n(n+1)P_n(x) = 0
\end{aligned} P 0 ( x ) = 1 P 1 ( x ) = x ( 1 − x 2 ) P n ′′ ( x ) − 2 x P n ′ ( x ) + n ( n + 1 ) P n ( x ) = 0 를 사용한 경우로, Translated Legendre Measure 라고 부릅니다. 이때, memory unit에 대한 ODE는 다음과 같습니다.
c ˙ ( t ) = − 1 τ A c ( t ) + 1 τ B f ( t ) , c ( 0 ) = 0 A n k = ( 2 n + 1 ) 1 2 ( 2 k + 1 ) 1 2 { 1 if k ≤ n ( − 1 ) n − k if k ≥ n B n = ( 2 n + 1 ) 1 2 \begin{aligned}
&\dot{c}(t) = -\frac{1}{\tau}Ac(t) + \frac{1}{\tau}Bf(t),\quad c(0) = 0\\
&A_{nk} = (2n+1)^{\frac{1}{2}}(2k+1)^{\frac{1}{2}}\begin{cases}
1 & \text{if } k\le n\\
(-1)^{n-k} & \text{if } k \ge n
\end{cases}\\
&B_n = (2n+1)^{\frac{1}{2}}
\end{aligned} c ˙ ( t ) = − τ 1 A c ( t ) + τ 1 B f ( t ) , c ( 0 ) = 0 A nk = ( 2 n + 1 ) 2 1 ( 2 k + 1 ) 2 1 { 1 ( − 1 ) n − k if k ≤ n if k ≥ n B n = ( 2 n + 1 ) 2 1 Uniform measure를 사용한다는 것은, 이전 시점들에 대해 동일한 가중치를 부여한다는 것을 의미합니다 (아래 그림의 왼쪽).
Source: Gu et al. (2020)
HiPPO-LagT
Translated Laguerre measure 는 Laguerre polynomial basis와 exponential weight function을 사용하는 경우입니다. 이때, weight function은 다음과 같이 주어집니다.
ω ( t , x ) = ( t − x ) α e − ( t − x ) I ( − ∞ , t ) ( x ) \omega(t,x) = (t-x)^\alpha e^{-(t-x)} \mathbb{I}_{(-\infty,t)}(x) ω ( t , x ) = ( t − x ) α e − ( t − x ) I ( − ∞ , t ) ( x ) 이는 최근 시점들에 대해 더 높은 가중치를 부여하는 것으로 볼 수 있습니다 (위 그림의 가운데 참고). 이때, memory unit에 대한 ODE는 다음과 같습니다.
c ˙ ( t ) = − A c ( t ) + B f ( t ) , c ( 0 ) = 0 A n k = { 1 if n ≥ k 0 if n < k B n = 1 \begin{aligned}
\dot{c}(t) &= -Ac(t) + Bf(t),\quad c(0) = 0\\
A_{nk} &= \begin{cases}
1 & \text{if } n \ge k\\
0 & \text{if } n < k
\end{cases}\\
B_n &= 1
\end{aligned} c ˙ ( t ) A nk B n = − A c ( t ) + B f ( t ) , c ( 0 ) = 0 = { 1 0 if n ≥ k if n < k = 1 HiPPO-LegS
마지막으로, Scaled Legendre measure 는 이전까지의 전 시점에 대해 uniform weight을 부여하는 측도입니다.
ω ( t , x ) = 1 t I [ 0 , t ] ( x ) \omega(t,x) = \frac{1}{t} \mathbb{I}_{[0,t]}(x) ω ( t , x ) = t 1 I [ 0 , t ] ( x ) 이에 대한 memory unit ODE는 다음과 같습니다.
c ˙ ( t ) = − 1 t A c ( t ) + 1 t B f ( t ) , c ( 0 ) = 0 A n k = { ( 2 n + 1 ) 1 2 ( 2 k + 1 ) 1 2 if n > k n + 1 if n = k 0 if n < k B n = ( 2 n + 1 ) 1 2 \begin{aligned}
\dot{c}(t) &= -\frac{1}{t}Ac(t) + \frac{1}{t}Bf(t),\quad c(0) = 0\\
A_{nk} &= \begin{cases}
(2n+1)^{\frac{1}{2}}(2k+1)^{\frac{1}{2}} & \text{if } n>k\\
n+1 & \text{if } n = k\\
0 & \text{if } n < k
\end{cases}\\
B_n &= (2n+1)^{\frac{1}{2}}
\end{aligned} c ˙ ( t ) A nk B n = − t 1 A c ( t ) + t 1 B f ( t ) , c ( 0 ) = 0 = ⎩ ⎨ ⎧ ( 2 n + 1 ) 2 1 ( 2 k + 1 ) 2 1 n + 1 0 if n > k if n = k if n < k = ( 2 n + 1 ) 2 1 Discrete-time SSM
Memory-unit ODE를 풀기 위해, 위 ODE를 discrete-time으로 변환하여 사용합니다. 예를 들어 Hippo-LegS (scaled Legendre measure)에 대해 forward Euler discretization을 사용하면 다음과 같이 주어집니다.
c ( ( k + 1 ) Δ t ) − c ( k Δ t ) = − Δ t Δ t k A c ( k Δ t ) + Δ t Δ t k B f k c ( ( k + 1 ) Δ t ) = ( I − 1 k A ) c ( k Δ t ) + 1 k B f k ≜ A ˉ k c k + B ˉ k f k (1) \begin{aligned}
c((k+1)\Delta t) - c(k\Delta t) &= -\frac{\Delta t}{\Delta tk}Ac(k\Delta t) + \frac{\Delta t}{\Delta tk}Bf_k\\
c((k+1)\Delta t) &= (I-\frac{1}{k}A) c(k\Delta t) + \frac{1}{k}Bf_k \\
&\triangleq \bar A_k c_k + \bar B_k f_k
\end{aligned}
\tag{1} c (( k + 1 ) Δ t ) − c ( k Δ t ) c (( k + 1 ) Δ t ) = − Δ t k Δ t A c ( k Δ t ) + Δ t k Δ t B f k = ( I − k 1 A ) c ( k Δ t ) + k 1 B f k ≜ A ˉ k c k + B ˉ k f k ( 1 ) 이러한 방식으로 SSM을 RNN과 유사한 구조로 변환하여 사용할 수 있습니다. 그러나 이 역시 RNN과 마찬가지로 병렬 연산이 불가능하기 때문에, 이를 해결하고자 S4 모델에서는 convolution representation을 사용합니다.
LSSL and S4
Linear State-Space Layer
앞선 내용들에서는 memory unit을 기반으로 상태공간모형을 정의하였고, 이를 discretize할 경우 식 ( 1 ) (1) ( 1 ) { u ( t ) } t ∈ [ 0 , T ] \{u(t)\}_{t\in[0,T]} { u ( t ) } t ∈ [ 0 , T ] { y ( t ) } t ∈ [ 0 , T ] \{y(t)\}_{t\in[0,T]} { y ( t ) } t ∈ [ 0 , T ] seq2seq 형태의 레이어를 구성할 수 있습니다. 이러한 레이어를 Linear State-Space Layer LSSL 이라고 부릅니다.
x ˙ ( t ) = A x ( t ) + B u ( t ) ∈ R n y ( t ) = C x ( t ) ∈ R (LSSL) \begin{align}
\dot x(t) &= Ax(t) + Bu(t) \in \mathbb{R}^{n}\\
y(t) &= Cx(t) \in \mathbb{R}
\end{align}
\tag{LSSL} x ˙ ( t ) y ( t ) = A x ( t ) + B u ( t ) ∈ R n = C x ( t ) ∈ R ( LSSL ) 위 미분방정식을 초기값 조건 x ( 0 ) = 0 ∈ R n x(0)=\mathbf{0}\in \mathbb{R}^{n} x ( 0 ) = 0 ∈ R n
y ( t ) = ∫ − ∞ ∞ K ( t − s ) u ( s ) d s = ( K ∗ u ) ( t ) y(t) = \int_{-\infty}^{\infty}K(t-s)u(s)ds = (K\ast u)(t) y ( t ) = ∫ − ∞ ∞ K ( t − s ) u ( s ) d s = ( K ∗ u ) ( t ) 를 얻게 되고, 여기서 K , u K,u K , u
K ( t ) = { C e t A B for t ≥ 0 0 otherwise u ( t ) = { u ( t ) ≥ 0 for t ≥ 0 0 otherwise \begin{aligned}
K(t) &= \begin{cases}
Ce^{tA}B&\text{for } t \ge 0\\
0 & \text{otherwise}
\end{cases}\\
u(t) &= \begin{cases}
u(t)\ge 0 & \text{for }t \ge 0\\
0&\text{otherwise}
\end{cases}
\end{aligned} K ( t ) u ( t ) = { C e t A B 0 for t ≥ 0 otherwise = { u ( t ) ≥ 0 0 for t ≥ 0 otherwise 이렇게 정의되는 seq2seq layer를 continuous-time LSSL 이라고 합니다.
Initialization
위와 같이 정의되는 ( L S S L ) (\mathrm{LSSL}) ( LSSL ) A A A
A n k = { ( 2 n + 1 ) 1 2 ( 2 k + 1 ) 1 2 if n > k n + 1 if n = k 0 if n < k A_{nk}= \begin{cases}
(2n+1)^{\frac{1}{2}}(2k+1)^{\frac{1}{2}} & \text{if } n>k\\
n+1 & \text{if } n = k\\
0 & \text{if } n < k
\end{cases} A nk = ⎩ ⎨ ⎧ ( 2 n + 1 ) 2 1 ( 2 k + 1 ) 2 1 n + 1 0 if n > k if n = k if n < k 이때 중요한 점은, 행렬 A A A time-invariant 하다는 것입니다. 이는 time-varying 한 행렬 A ( t ) A(t) A ( t ) B B B
Discrete-time LSSL
HiPPO에서 살펴본 것과 마찬가지로 위 ( L S S L ) (\mathrm{LSSL}) ( LSSL )
{ x k = A ˉ x k − 1 + B ˉ u k y k = C x k (2) \begin{cases}
x_k = \bar A x_{k-1} + \bar B u_k \\
y_k = C x_k
\end{cases}
\tag{2} { x k = A ˉ x k − 1 + B ˉ u k y k = C x k ( 2 ) 식 ( 1 ) (1) ( 1 )
여기서 x − 1 = 0 x_{-1}=0 x − 1 = 0
y k = C A ˉ k B ˉ u 0 + C A ˉ k − 1 B ˉ u 1 + ⋯ + C A ˉ B ˉ u k − 1 + C B ˉ u k y = K ‾ ∗ u \begin{aligned}
y_k &= C \bar A^k \bar B u_0 + C \bar A^{k-1} \bar B u_1 + \cdots + C \bar A \bar B u_{k-1} + C \bar B u_k \\
y &= \overline{\mathbf{K}} \ast u
\end{aligned} y k y = C A ˉ k B ˉ u 0 + C A ˉ k − 1 B ˉ u 1 + ⋯ + C A ˉ B ˉ u k − 1 + C B ˉ u k = K ∗ u 이때, K ‾ \overline{\mathbf{K}} K
K ‾ ≜ K L ( A ˉ , B ˉ , C ) : = ( C B ˉ C A ˉ B ˉ ⋯ C A ˉ L − 1 B ˉ ) \begin{aligned}
\overline{\mathbf{K}} &\triangleq \mathcal{K}_L(\bar A, \bar B, C) \\
&:= \begin{pmatrix}
C \bar B & C \bar A \bar B & \cdots & C \bar A^{L-1} \bar B
\end{pmatrix}
\end{aligned} K ≜ K L ( A ˉ , B ˉ , C ) := ( C B ˉ C A ˉ B ˉ ⋯ C A ˉ L − 1 B ˉ ) 즉, SSM의 연산과정은 하나의 convolution 연산으로 표현할 수 있고 이로 인해 FFT와 같은 효율적인 연산이 가능해집니다. 이렇게 정의되는 K ‾ \overline{\mathbf{K}} K SSM convolution kernel 이라고 부릅니다.
S4 Model
Discretized SSM (식 ( 2 ) (2) ( 2 ) L L L O ( N 2 L ) O(N^2L) O ( N 2 L ) O ( N L ) O(NL) O ( N L ) A A A
Theorem
앞서 제시된 HiPPO ODE (그 종류에 관계 없이)에서의 행렬 A A A
A = V Λ V ∗ − P Q ⊤ = V ( Λ − ( V ∗ P ) ( V ∗ Q ) ∗ ) V ∗ A = V\Lambda V^\ast - PQ^\top = V(\Lambda - (V^\ast P)(V^\ast Q)^\ast)V^\ast A = V Λ V ∗ − P Q ⊤ = V ( Λ − ( V ∗ P ) ( V ∗ Q ) ∗ ) V ∗ 여기서 V V V Λ \Lambda Λ P , Q P,Q P , Q r r r Normal Plus Low-Rank (NPLR) 이라고 합니다.
그러나 위 정리를 이용해도 A A A
S4 Algorithm
SSM generating function(SSMGF) 을 길이 L L L
C ~ ← ( I − A ˉ L ) ∗ C ˉ \tilde C \leftarrow \left(\mathbf{I}- \bar A^{L}\right)^{\ast}\bar C C ~ ← ( I − A ˉ L ) ∗ C ˉ 여기서 SSM generating function은 다음과 같은 다항전개 형태를 말합니다.
∑ k = 0 ∞ K ‾ k z k \sum_{k=0}^{\infty} \overline{\mathbf{K}}_k z^k k = 0 ∑ ∞ K k z k (z z z 단위근 : z = e 2 π i / L z = e^{2\pi i/L} z = e 2 π i / L
Black-box Cauchy kernel
[ k 00 ( ω ) k 01 ( ω ) k 10 ( ω ) k 11 ( ω ) ] ← [ C ~ Q ] ∗ ( 2 Δ ⋅ 1 − ω 1 + ω − Λ ) − 1 [ B P ] \begin{bmatrix}
k_{00}(\omega) & k_{01}(\omega) \\
k_{10}(\omega) & k_{11}(\omega)
\end{bmatrix}
\leftarrow \begin{bmatrix}
\tilde C & Q
\end{bmatrix}^\ast \left(\frac{2}{\Delta}\cdot \frac{1-\omega}{1+\omega}-\Lambda\right)^{-1} \begin{bmatrix}
B & P
\end{bmatrix} [ k 00 ( ω ) k 10 ( ω ) k 01 ( ω ) k 11 ( ω ) ] ← [ C ~ Q ] ∗ ( Δ 2 ⋅ 1 + ω 1 − ω − Λ ) − 1 [ B P ]
Woodbury identity
K ^ ← 2 1 + ω [ k 00 ( ω ) − k 01 ( ω ) ( 1 + k 11 ( ω ) ) − 1 k 10 ( ω ) ] \hat{\mathbf{K}} \leftarrow \frac{2}{1+\omega}[k_{00}(\omega) - k_{01}(\omega)(1+k_{11}(\omega))^{-1}k_{10}(\omega)] K ^ ← 1 + ω 2 [ k 00 ( ω ) − k 01 ( ω ) ( 1 + k 11 ( ω ) ) − 1 k 10 ( ω )]
Evaluate SSMGF at z ∈ Ω L z \in \Omega_L z ∈ Ω L
K ^ k = { K ^ ( ω ) : ω = exp ( 2 π i k / L ) } \hat{\mathbf{K}}_k = \{\hat{\mathbf{K}}(\omega): \omega = \exp(2\pi i k/L)\} K ^ k = { K ^ ( ω ) : ω = exp ( 2 π ik / L )}
Inverse FFT
K ‾ = IFFT ( K ^ ) \overline{\mathbf{K}} = \text{IFFT}(\hat{\mathbf{K}}) K = IFFT ( K ^ )
위와 같이 S4 모델은 Linear State-Space Layer를 효율적으로 계산하기 위한 방법을 제시하고 있습니다. 파라미터 수, 계산 비용 등에서 기존의 Attention mechanism을 사용하는 Transformer 아키텍쳐에 비해 효율적인 구조를 가지고 있다는 것이 S4의 장점입니다. (아래 표 참고)
Source: Gu et al. (2022)
여기서 L L L B B B H H H
References
Hugging Face blog : https://huggingface.co/blog/lbourdois/get-on-the-ssm-train
https://hazyresearch.stanford.edu/blog/2022-01-14-s4-3 Gu, A., Goel, K., & Ré, C. (2022). Efficiently Modeling Long Sequences with Structured State Spaces (arXiv:2111.00396). arXiv. https://doi.org/10.48550/arXiv.2111.00396
Gu, A., & Dao, T. (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces (arXiv:2312.00752). arXiv. https://doi.org/10.48550/arXiv.2312.00752
Gu, A., Dao, T., Ermon, S., Rudra, A., & Re, C. (2020). HiPPO: Recurrent Memory with Optimal Polynomial Projections (arXiv:2008.07669). arXiv. https://doi.org/10.48550/arXiv.2008.07669
Voelker, A., Kajić, I., & Eliasmith, C. (2019). Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks. Advances in Neural Information Processing Systems , 32 . https://proceedings.neurips.cc/paper/2019/hash/952285b9b7e7a1be5aa7849f32ffff05-Abstract.html
A. Gu et al. , “Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers.” arXiv, Oct. 26, 2021. doi: 10.48550/arXiv.2110.13985 .
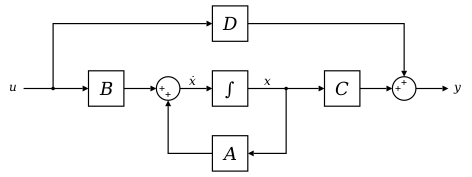 SSM representation. Source: [wikipedia](https://en.wikipedia.org/wiki/State-space_representation)
SSM representation. Source: [wikipedia](https://en.wikipedia.org/wiki/State-space_representation)
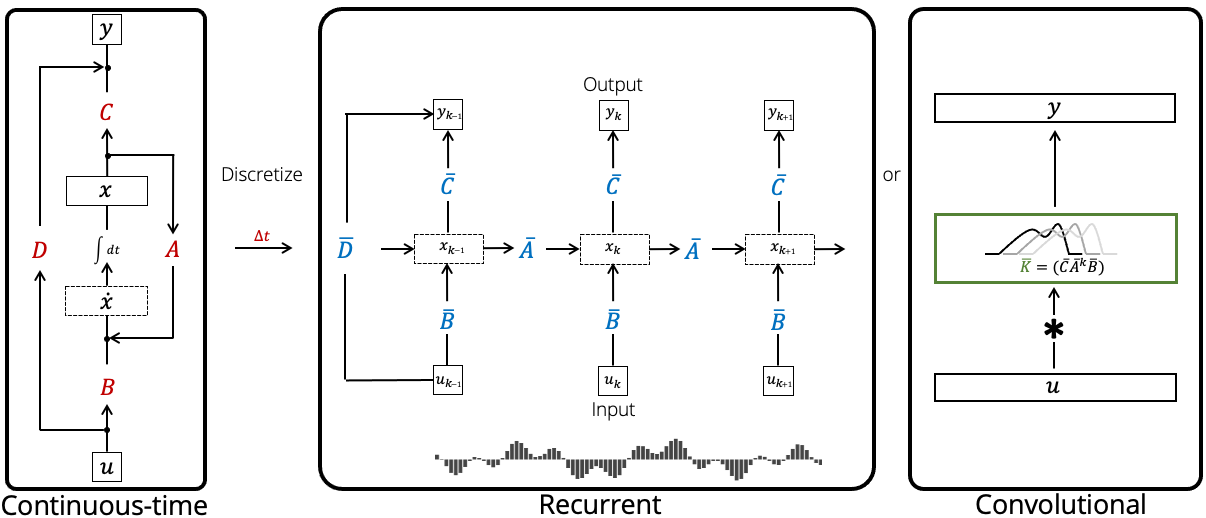 Source: https://hazyresearch.stanford.edu/blog/2022-01-14-s4-3
Source: https://hazyresearch.stanford.edu/blog/2022-01-14-s4-3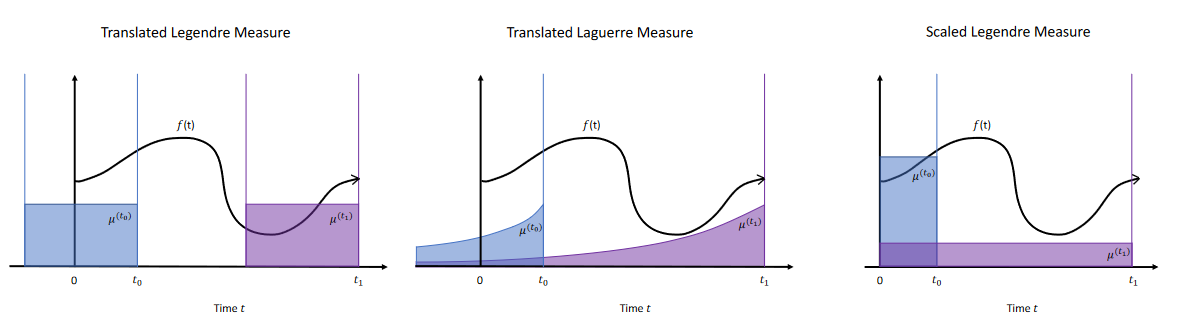 Source: Gu et al. (2020)
Source: Gu et al. (2020) Source: Gu et al. (2022)
Source: Gu et al. (2022)