Universal Approximation Theorem
딥러닝이 예측 문제에서 매우 높은 성능을 발휘하는 이유 중 하나는, 바로 딥러닝을 통해 근사한 함수가 보간interpolation에 가깝게 원래 함수를 근사한다는 것이다. 바꾸어 말하면, 어떠한 함수든 신경망으로 근사할 수 있다는 것인데, 이러한 이론적 배경을 Universal Approximation Theorem이라고 한다.
ReLU
ReLU 활성함수는 단순히 0 이하의 부분을 cut-off 하는 간단한 활성함수지만, 이러한 특성으로 인해 역전파 알고리즘 단계에서 그래디언트 계산이 쉽고, 그래디언트 폭주 등 문제가 적다는 점에서 현재 대표적으로 이용되는 활성함수이다. Universal Approximation Theorem은 비단 ReLU 함수에만 적용되는 것은 아니지만, ReLU 함수를 이용해 살펴보면 좀 더 직관적인 이해가 가능하다.
우선, 1개의 hidden layer 층을 갖는 간단한 신경망 구조를 생각하자. 그리고 다음과 같이 hidden layer에 세 개의 노드가 있다고 가정하자. 아래 그림과 같다.
f1(x)f2(x)f3(x)=0.25x+0.05=x=−0.5x+0.25
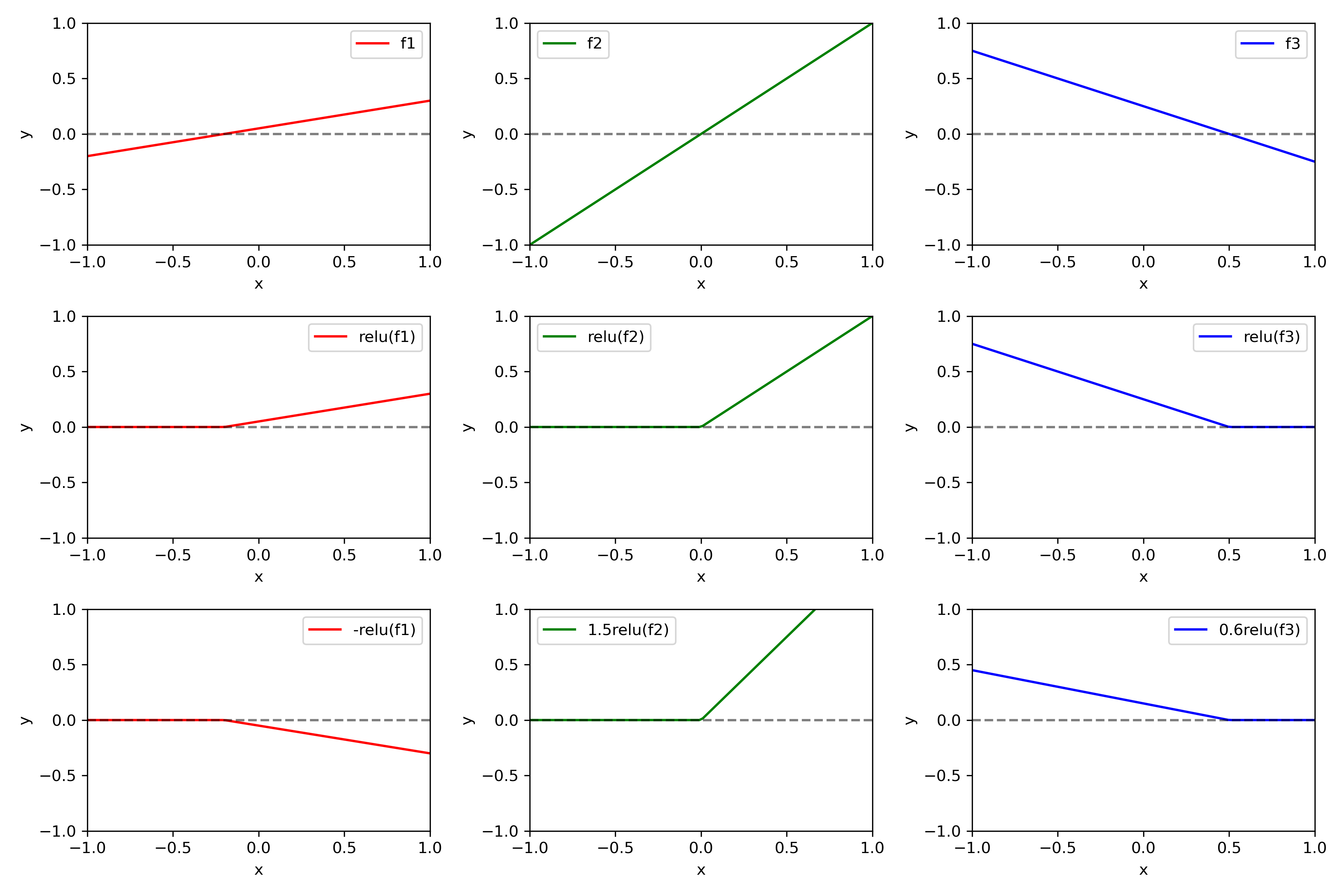
그렇다면 이들에 대해 ReLU함수를 취하고, 최종적으로 Output layer에 대해서는 다음과 같은 선형결합이 계산된다.
y=ϕ0+ϕ1ReLU(f1(x))+ϕ2ReLU(f2(x))+ϕ3ReLU(f3(x))
선형결합을 도식화하면, 다음과 같은 그래프를 얻을 수 있는데, 이는 마치 spline regression에서 매듭을 세개로 설정한 것과 같다. 즉, 은닉층의 각 노드가 매듭(수직 점선)에 대응된다. 이는 곧 은닉층의 노드 개수를 늘릴수록, 더 smooth한 함수를 만들 수 있다는 것이다. 이러한 아이디어를 이용하면, 임의의 함수를 아주 작은 간격의 선형함수들을 결합해 근사할 수 있다는 생각을 할 수 있는데, 이를 universal approximation theorem이라고 한다.
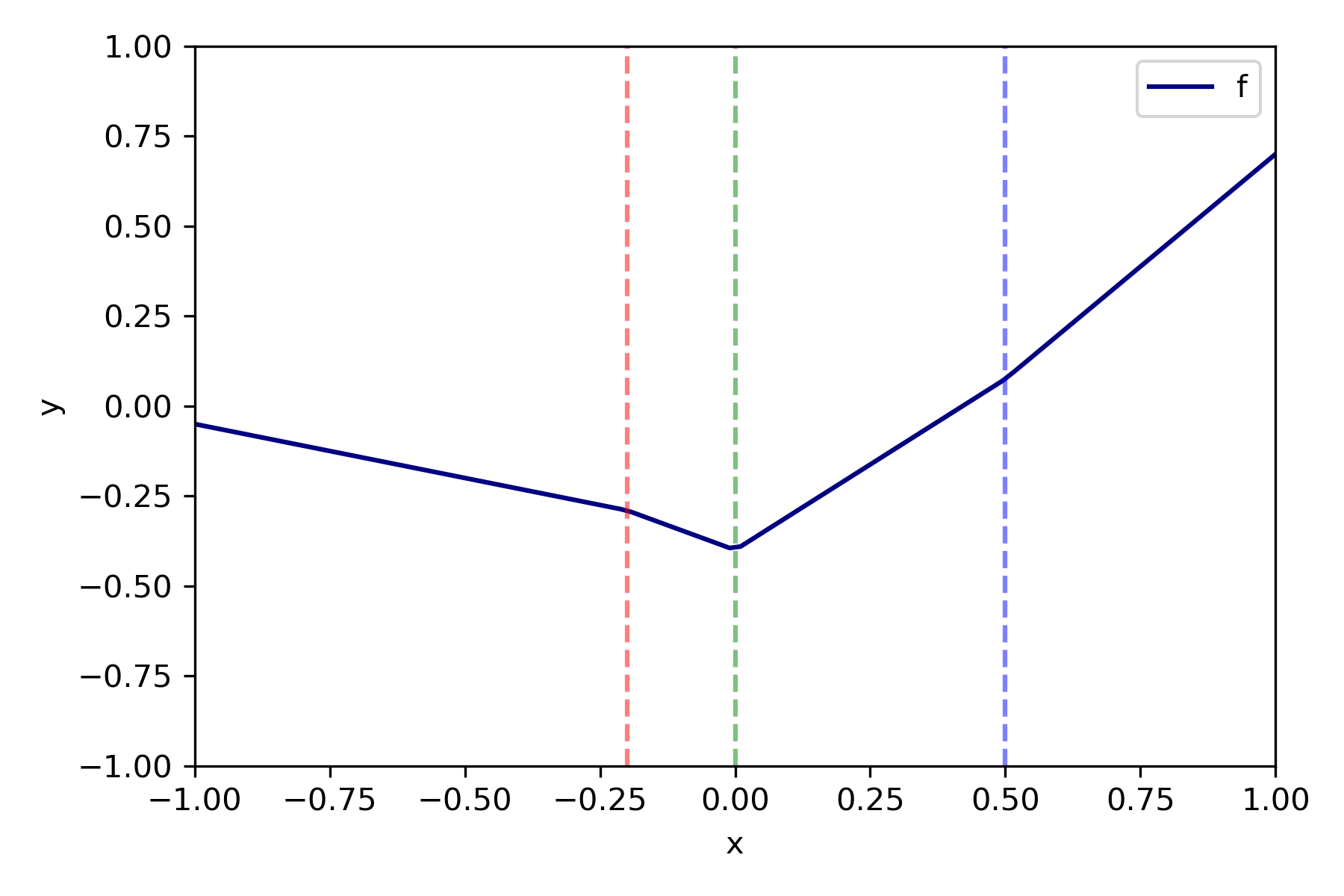
실제로, 완전연결 ReLU 신경망에 대해 다음과 같은 정리가 성립한다.
Theorem for Width-bounded ReLU
임의의 르벡적분가능한 f:Rn→R 과 임의의 양수 ϵ>0 에 대해, 너비width가 dm≤n+4 인 완전연결 ReLU 신경망 F가 존재하여 다음을 만족한다.
∫Rn∥f(x)−F(x)∥pdx<ϵ
즉, 다음이 성립한다는 것을 의미한다.
임의의 르벡적분가능한 함수에 대해, 미리 정해진 근사 정확도approximation accuracy를 갖춘 너비 n+4 의 ReLU 네트워크를 근사할 수 있다.
증명
위 정리의 증명은 임의의 르벡적분가능 함수 f를 L1 거리공간에서 근사하는 네트워크를 만드는 것이다. 증명의 순서는 다음과 같다.
- f 가 n차원 큐브에서 지시함수indicator function들의 유한 가중합weighted sum으로 나타낼 수 있다.
- ReLU 네트워크가 n차원 큐브에서 지시함수를 근사해낼 수 있다.
- ReLU 네트워크가 여러 부분구조의 합으로 나타난다.
1. 지시함수의 유한 가중합
입력값 벡터 x=(x1,…,xn) 이 주어졌을 때, f가 르벡적분가능하므로 임의의 ϵ>0 에 대해 다음을 만족하는 N>0 이 존재한다.
∫∪i=1n∣xi∣≥N∣f∣dx<2ϵ
다음을 정의하면,
E:=[−N,N]n
f1(x):={max{f,0}0x∈Ex∈/E
f2(x):={max{−f,0}0x∈Ex∈/E
다음이 성립한다.
∫Rn∣f−(f1−f2)∣dx<2ϵ
또한, 다음 두 집합을 정의하자.
VE1:VE2:={(x,y)∣x∈E,0<y<f1(x)}={(x,y)∣x∈E,0<y<f2(x)}
그러면 각 집합은 가측measurable집합이므로, 각각 유한개의 n+1 차원 큐브 Jj,i로 이루어진 르벡 덮개가 존재하여 다음을 만족한다.
μ(VEi△j⋃Jj,i)<8ϵ(1)
또한, 각 큐브 Jj,i가 다음과 같은 형태로 주어진다고 가정하자.
Jj,i=[a1,j,i,a1,j,i+b1,j,i]×⋯×[an+1,j,i,an+1,j,i+bn+1,j,i]
그러면, Jj,i는 n+1차원이므로, 다음과 같은 n차원 큐브 X들에 대한 지시함수에 대응된다.
Xj,i=[a1,j,i,a1,j,i+b1,j,i]×⋯×[an,j,i,an,j,i+bn,j,i]
이때 각 지시함수를 다음과 같이 정의하자.
ϕj,i(x)={10x∈Xj,ix∈/Xj,i
그럼 식 (1) 로부터 다음이 성립한다. 여기서 ni는 Jj,i 들의 개수이다.
∫E∣fi−j=1∑nibn+1,j,iϕj,i∣dx<8ϵ
즉, 이로부터 임의의 르벡적분가능함수 f를 nonnegative한 함수 f1,f2로 바꾸어 지시함수들의 유한합으로 근사할 수 있음을 확인했다.
2. ReLU Network
증명의 다음 과정은 ReLU network로 지시함수 ϕj,i 를 근사하는 것이다. 즉, 다음을 만족하는 함수 φj,i를 찾으면 된다.
∫Xj,i∣ϕj,i−φj,i∣dx<4(C+43ϵ)ϵ∫E∣ϕj,i∣dx
즉, 임의의 I∈{ϕj,i} 와 X=[a1,b1]×⋯×[an,bn] 에 대해
I={10x∈Xx∈/X
을 가정하면 네트워크 N을 구성하여 이로부터 다음의 함수 J를 생성한다. J를 생성한다는 것은 네트워크를 하나의 함수로 보고 이를 J(x) 꼴로 표기한다는 것이다.
∫E∣I−J∣dx<4C+3ϵϵi=1∏n(bi−ai)
네트워크를 구성하는 방법은 복잡해서 여기서는 생략하겠으나, 핵심 아이디어는 함수를 잘게 나누어 함수의 지지집합support set을 줄이는 것이다. 이때 잘게 나눈 함수를 얕은shallow ReLU network로 나타내는데, 이를 Single ReLU Unit(SRU) 이라고 하며 다음을 만족한다.
임의의 δ>0,k=1,2,…,n 에 대해 네트워크 Nk 는 다음 조건들을 만족한다. 여기서 함수 Ri,j,N 는 네트워크 N에서 i번째 레이어의 j번째 노드에 ReLU 활성함수를 적용한 함수를 의미한다. R0,N는 입력 레이어를 의미한다.
- Nk 의 각 레이어의 폭은 n+4이다.
- Nk의 깊이는 3이다.
- i=0,1,2,3,j=1,2,…,n 에 대해 Ri,j,Nk=(xi+N)+
- j=n+1,n+2에 대해 Ri,j,Nk 과 관련된 가중치들은 모두 0이다.
- 첫번째 레이어(입력 레이어를 제외한)의 n+3번째 노드 R1,n+3,Nk 는 다음을 만족한다.
-
0≤R1,n+3,Nk(x)≤1,∀x
-
R1,n+3,Nk(x)=0 if
(x1,…,xk−1)∈/[a1,b1]×⋯×[ak−1,bk−1]
-
R1,n+3,Nk(x)=1 if
(x1,…,xk−1)∈[a1+δ(b1−a1),b1−δ(b1−a1)]×⋯×[ak−1+δ(bk−1−ak−1),bk−1−δ(bk−1−ak−1)]
- 마지막 레이어의 n+3번째 노드 R4,n+3,Nk 는 다음을 만족한다.
-
0≤R4,n+3,Nk(x)≤1,∀x
-
R4,n+3,Nk(x)=0 if
(x1,…,xk−1)∈/[a1,b1]×⋯×[ak−1,bk−1]
-
R4,n+3,Nk(x)=1 if
(x1,…,xk−1)∈[a1+δ(b1−a1),b1−δ(b1−a1)]×⋯×[ak+δ(bk−ak),bk−δ(bk−ak)]
즉, SRU에서는 각 레이어의 처음 n+2개 노드들은 output이 일정한 memory element인 반면, 나머지 두 노드는 computation element으로 기능한다.
References
- Simon J.D. Prince, Understanding Deep Learning.
- Lu et al., The Expressive Power of Neural Networks: A View from the Width