Archive
A Neural Approach to Spatiotemporal data release with Differential Privacy
Intro - Most existing work on DP-publication of location data focuses on single snapshot releases (Cormode et al., 2012) - To release multiple snapshot, user-level privacy is required - Two key aspects : Bound sensiti...
Intro
- Most existing work on DP-publication of location data focuses on single snapshot releases (Cormode et al., 2012)
- To release multiple snapshot, user-level privacy is required
- Two key aspects : Bound sensitivity and Add noise, with denoising step
Preliminaries
Problem Formulation
Goal
Release high-resolution density information of dataset .
- Build a histogram over , where is determined spatial and temporal resolution parameter.
Queries
-
Range count queries
- Given the query range(max,min of lat, lon, time)
- Return : the number of user location in that satisfy this range
- Metric : relative error metric
- where is smoothing factor to avoid division by zero.
-
Nearest hotspot queries
- Given query location , density threshold , spatio-temporal extent
- Return : closest cell to within extents that contains at least locations.
- Metric : MAE between distance for distance penalty. Regret (deviation of the reported density of the found hotspot from given ) for hotspot density estimation error
- if the reported hotspot meets the density threshold .
-
Forecasting queries
- Given timeseries of spatial densities and forecasting horizon
- Return : The prediction of count of location reports for future timesteps.
- Metric : symmetric mean absolute percentage errors
where are the true counts from in the timesteps and are the predicted counts from a forecasting algorithm fitted to the historical data from .
Data
- Spatiotemporal data : have density patterns through both temporal and spatial axis. (e.g. weekday vs weekend pattern at commercial area) (Yang et al., n.d.)
- Distribution across users : power law distribution
VDRVAE-based Density Release
- Differentially private release of spatiotemporal data
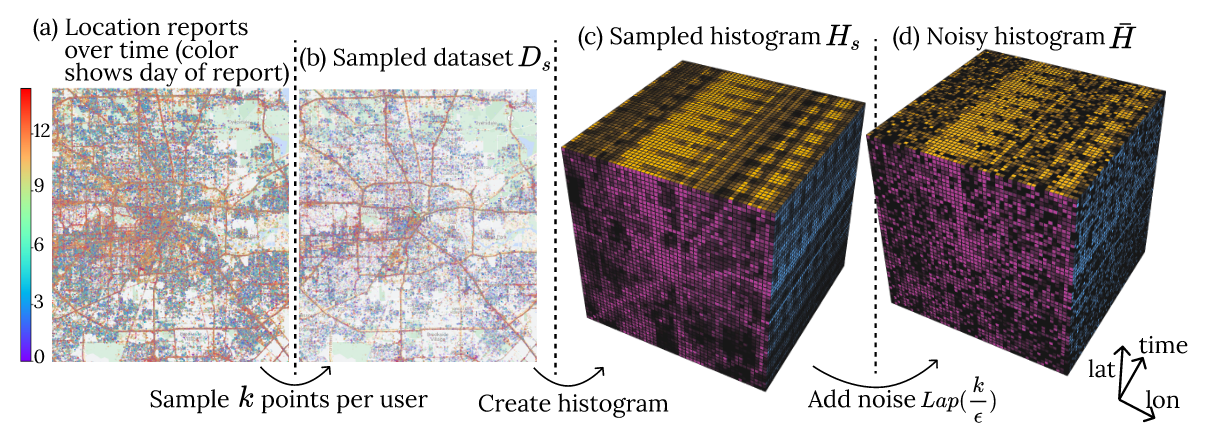
Data collection
- Goal is to create the -DP histogram (Figure (d)).
- Laplace mechanism with sensitivity i.e. the maximum number of points.
- Bound sensitivity by sampling a maximum of points per user.
Learned Denoising
- Spatiotemporal dataset are similar to video(seq. of images)
- Regularized representation learning > learns denoised representation without overfitting
- Multi-resolution learning can capture spatio-temporal patterns at different resolution
Design Principles
-
Denoising with regularized representation learning
: Derive a denoised histogram from VAE that minimizes reconstruction loss . By setting the dimensionality of representation lower than , the representation will capture the patterns in .
-
Multi-resolution Learning
: Prepare the training set with different resolution scales. Expect to improve denoising accuracy via MRL.
Algorithm
Model
- Given a noisy ST histogram where is a spatial histogram at -th timestamp.
- For regularized representation learning, use Convolutional VAE.
- : 2D histogram (any resolution) > representation
- : representation > 2D histogram
- Inference : Given , obtain (3D histogram).
VQ-VAE (Razavi et al., 2019)
- : codebook of different discrete encodings
- For training set , produces a set of representations .
- : regulariaztion loss. distance between representation and codebook
- : reconstruction loss
- Optimization becomes:
- Parameters
- : variability of the encoding space (representation power)
- : How much the encoder is forced to adhere to the codebook.
- Experiment :
Statistical Analysis
Let be the Bernoulli random variable indicates whether th point falls in a cell . Suppose the th point is sampled from . Let . The estimator is given by
Then, the bias and variance can be calculated as follows.
where is the total number of data points and is the total number of sampled data. Thus, the MSE is given by
By differentiating w.r.t. , we obtain
minimizes where is a data-dependent constant.
Theorem
The following VDR algorithm is -DP.
References
- Ahuja, R., Zeighami, S., Ghinita, G., & Shahabi, C. (2023). A Neural Approach to Spatio-Temporal Data Release with User-Level Differential Privacy. Proceedings of the ACM on Management of Data, 1(1), 1–25. https://doi.org/10.1145/3588701
- Razavi, A., Oord, A. van den, & Vinyals, O. (2019). Generating Diverse High-Fidelity Images with VQ-VAE-2 (arXiv:1906.00446). arXiv. https://doi.org/10.48550/arXiv.1906.00446
- Cormode, G., Procopiuc, C., Srivastava, D., Shen, E., & Yu, T. (2012). Differentially Private Spatial Decompositions. 2012 IEEE 28th International Conference on Data Engineering, 20–31. https://doi.org/10.1109/ICDE.2012.16