2026. 5. 26.research paper
A Sober Look at LLMs for Material Discovery: Are They Actually Good for Bayesian Optimization Over Molecules?
LLM을 분자 탐색용 Bayesian optimization surrogate로 쓸 때 필요한 확률적 불확실성 관점 정리
- llm-meets-statistics
- daily-paper
LLM을 분자 탐색용 Bayesian optimization surrogate로 쓸 때 필요한 확률적 불확실성 관점 정리
LLM-as-a-judge를 사람 annotator 대체 가능성에 대한 통계적 검정 문제로 읽는 논문 정리
LLM conformal uncertainty를 exchangeability 검정과 conformal p-value 관점에서 읽는 논문 정리
시계열 foundation model을 conformal prediction의 calibration 자원 배분 문제로 읽는 논문 정리
LLM-as-a-Judge 평가를 측정오차, 보정추정량, Youden's J 관점에서 이해하는 논문 정리
Setting 통계학적인 관점에서, 강화학습(RL)은 uncertainty 하에서 이루어지는 sequential decision making 혹은 dynamic optimization 이라고 할 수 있다. 일반적인 supervised learning 세팅에서는 관측 데이터 $(X,Y)$ 쌍들로부터 conditional distribution $\Pr(Y|X)$ 를 학습하는 것인 반면,...
LLM, Vision 관련 자주 언급되는 개념 및 논문들을 통계학적인 시각에서 간략히 정리해보고 있습니다. LLM-related concepts Learning In-Context Learning Shot : 프롬프트에 포함되는 example case - (zero-shot) - (1-shot) : example 1개 포함 - In-context learning : few-shot le...
저번 글에 이어, 이번 글에서도 공간 데이터의 인과추론에 대해 다루고자 합니다. 이번 글에서는 공간통계와 단짝이라고도 할 수 있는 베이지안 방법론을 기반으로 한 Spatial causal inference in the presence of unmeasured confounding and interference 논문을 소개합니다. 이 논문에서는 공간 인과 그래프 spatial causal...
이전 글에서는 처치변수와 결과변수가 모두 점 패턴인 경우에 대한 인과추론 방법론을 소개했습니다. 이번 글에서는 처치변수는 점 패턴으로 주어지지만 결과변수가 격자형으로 주어지는 areal data에 대한 인과추론 방법론을 소개합니다. 사실 많은 사회적 변수들이 areal data로 수집되는 경우가 많기 때문에 (ex. 행정구역별 통계, 격자별 인구 등) 이 논문에서 제안하는 방법론은 매우...
최근 공간 데이터에 대한 인과추론에 대해 관심을 가지고 여러 논문을 살펴보는 중인데, 기존 인과추론(Rubin의 인과 모델) 프레임워크는 SUTVA Stable Unit Treatment Value Assumption 가정을 기반으로 하는데, 이 중 No interference라는 가정이 공간 데이터에서는 성립하지 않는 경우가 많습니다. 예를 들어, 특정 지역에 대한 처치가 인근 지역에...
이번 글에서는 추천 시스템 중 협업 필터링 collaborative filtering 에 대한 내용을 개괄적으로 살펴보도록 하겠습니다. 우선, 협업 필터링이란 사용자가 평가하지 않은 항목에 대한 반응을 예측하는 것을 목표로 하여 각 사용자 혹은 항목 간의 유사도를 측정하여 이루어집니다. 협업 필터링은 크게 다음 두 가지로 분류할 수 있습니다. - 메모리 기반 필터링 Memory-base...
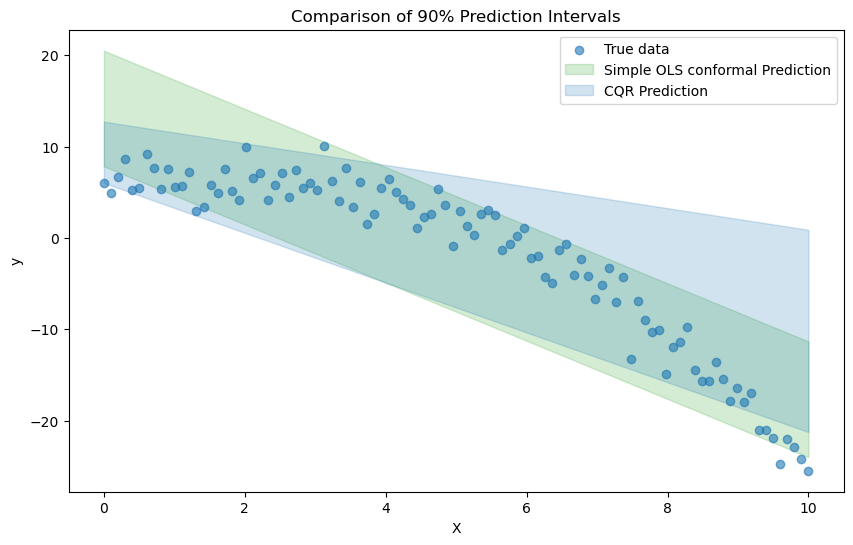
Conformal Prediction Introduction 일반적으로 통계학에서는 선형모형과 같은 모델을 설정하고, 이를 바탕으로 설명변수와 예측변수 간의 관계를 분석한다. 나아가, 학습한 모델을 바탕으로 새로운 데이터 $x^\ast$가 주어졌을 때, 이에 대한 예측값 $\hat{y}^\ast$를 계산한다. 예를 들어, 데이터 $X=(x1, x2, \cdots, x{n}), Y=(y{...
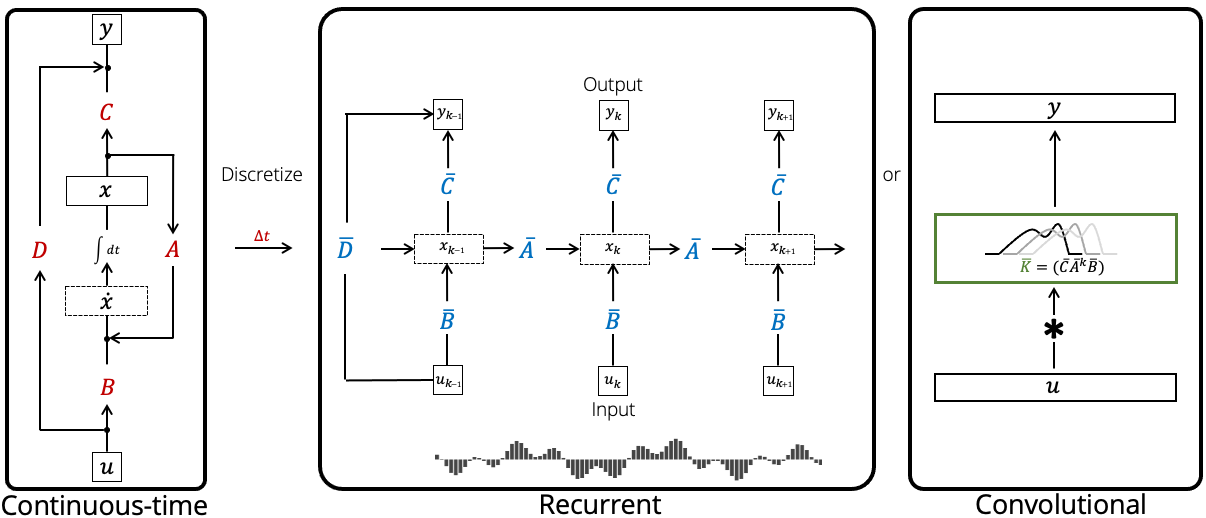
최근 Mamba (Gu & Dao, 2024)의 등장으로 상태공간모형(State-Space Model, 이하 SSM)은 Transformer를 대체할 수 있는 아키텍처의 후보로 여겨지고 있습니다. 이번 글에서는 보다 일반적인 상태공간모형과, 이를 딥러닝에 적용한 S4, HiPPO 등의 아키텍쳐에 대해 다루어보도록 하겠습니다. State Space Model Revisit: State S...
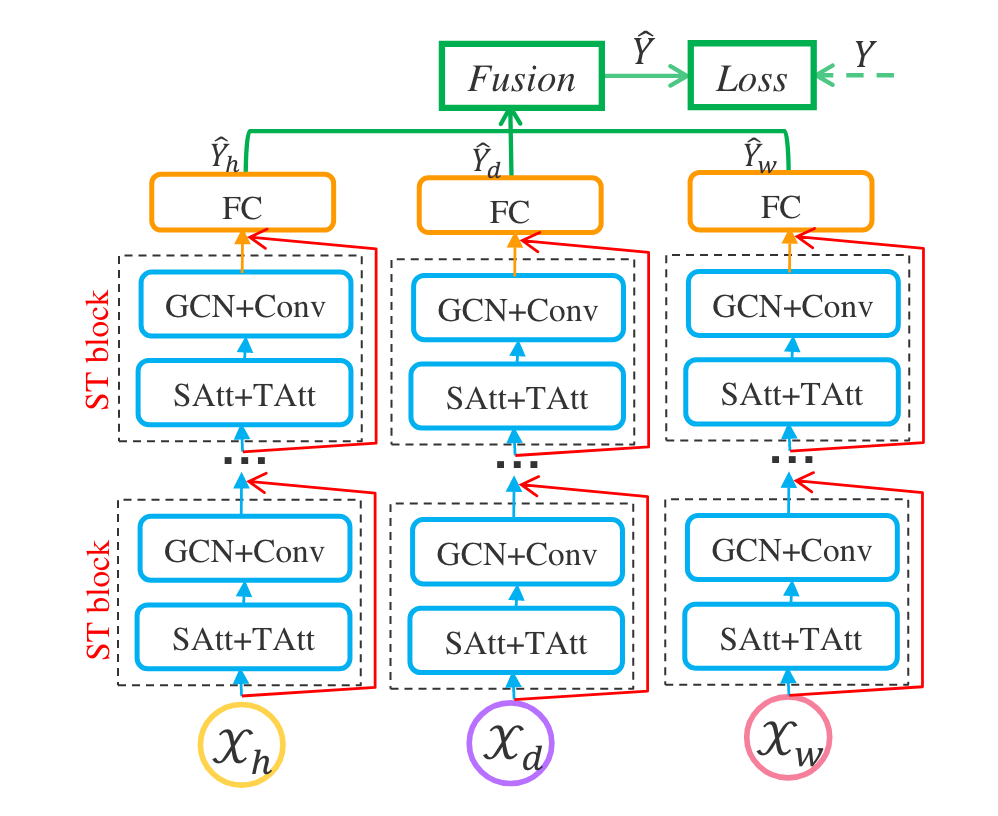
Graph Convolutional Network는 Graph Neural Network의 가장 대표적인 모델 중 하나입니다. Graph Neural Network는 그래프 구조를 이용하여 노드의 특성을 업데이트하는 방법으로, 최근에는 다양한 분야에 적용되고 있습니다. 이번 글에서는 Graph Convolutional Network (GCN) 과 이를 시공간 데이터에 적용한 Spatio...
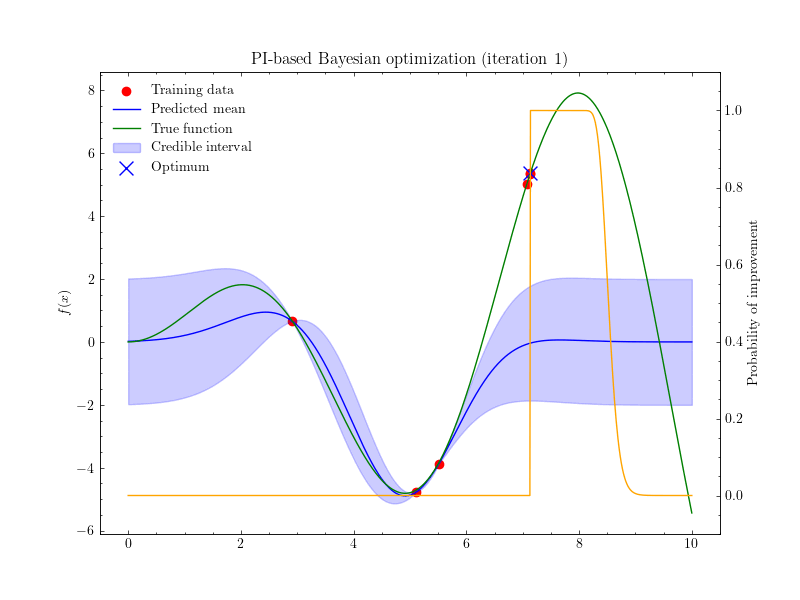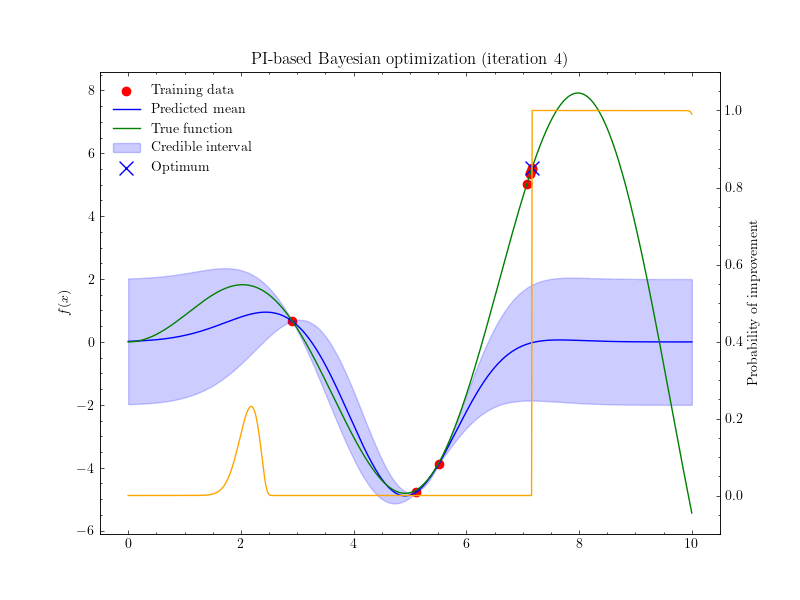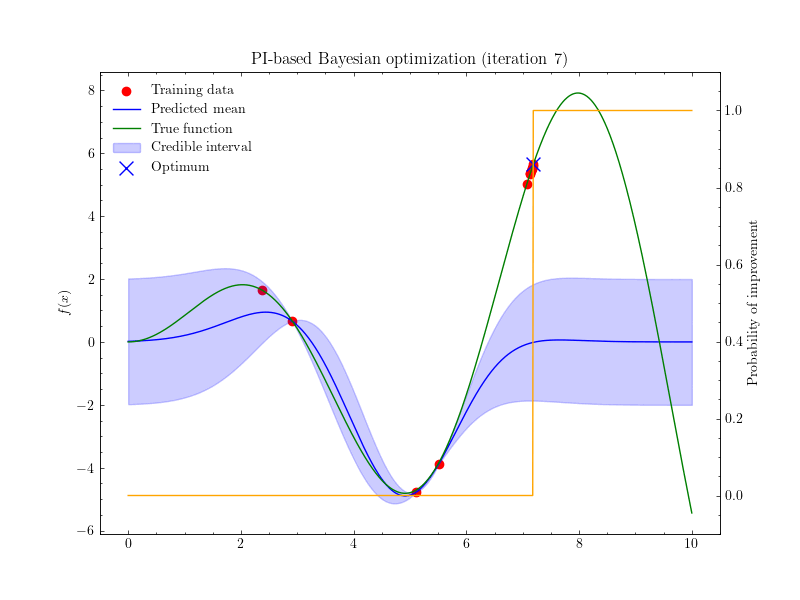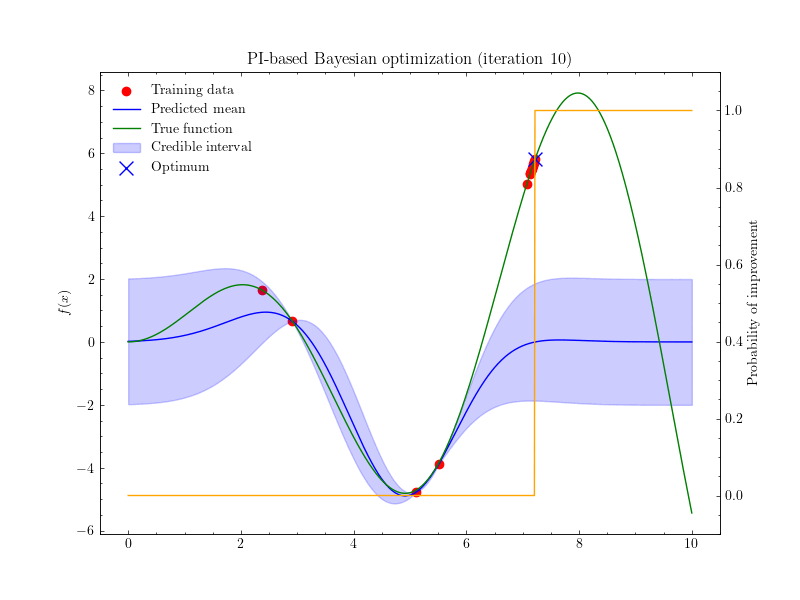
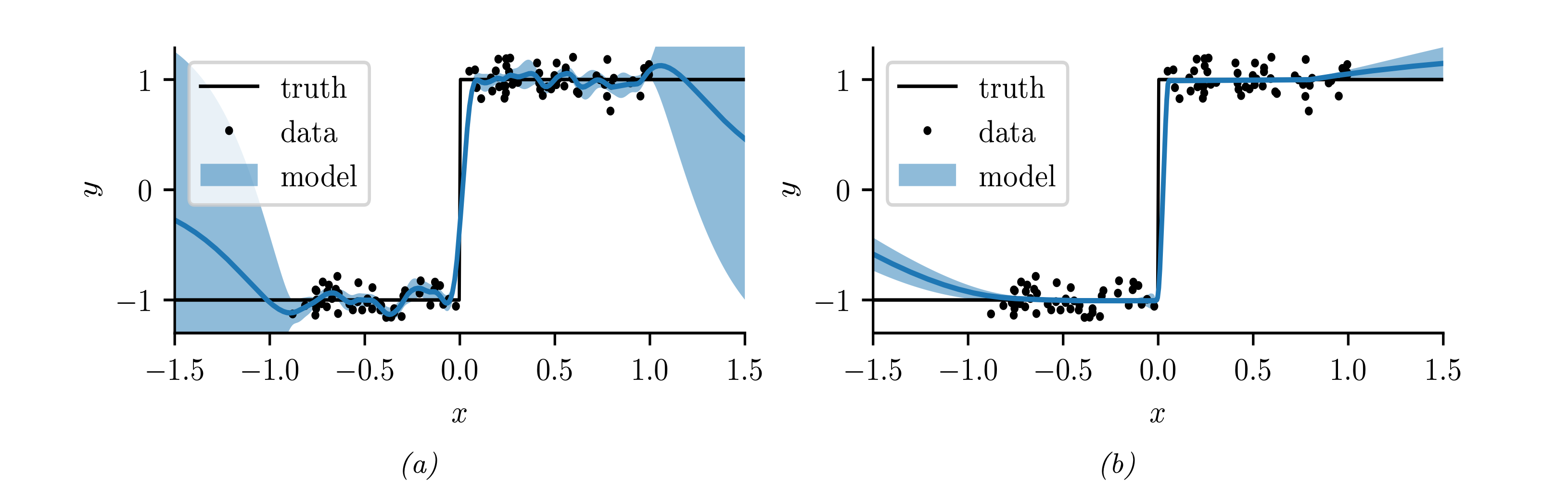
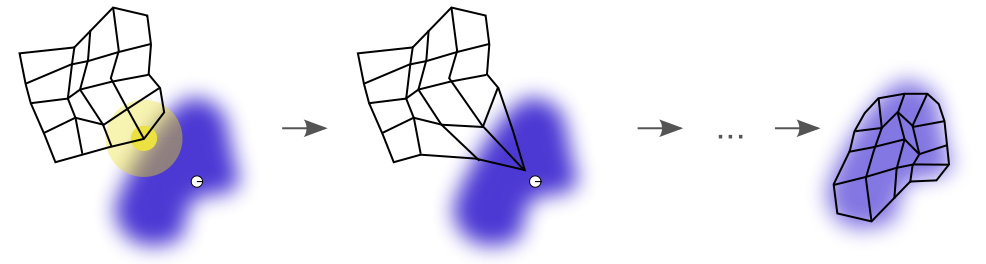
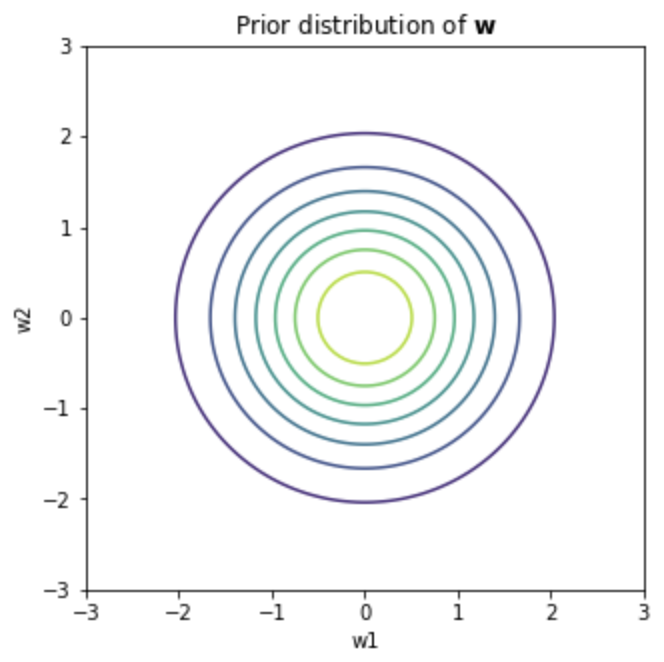
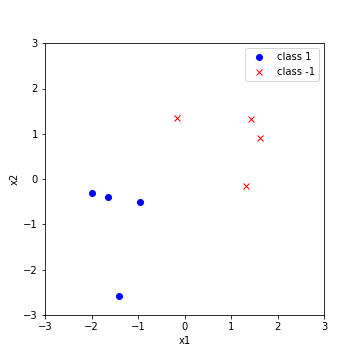
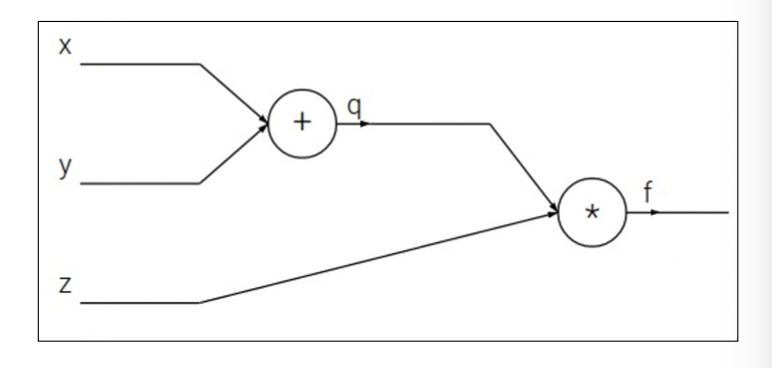
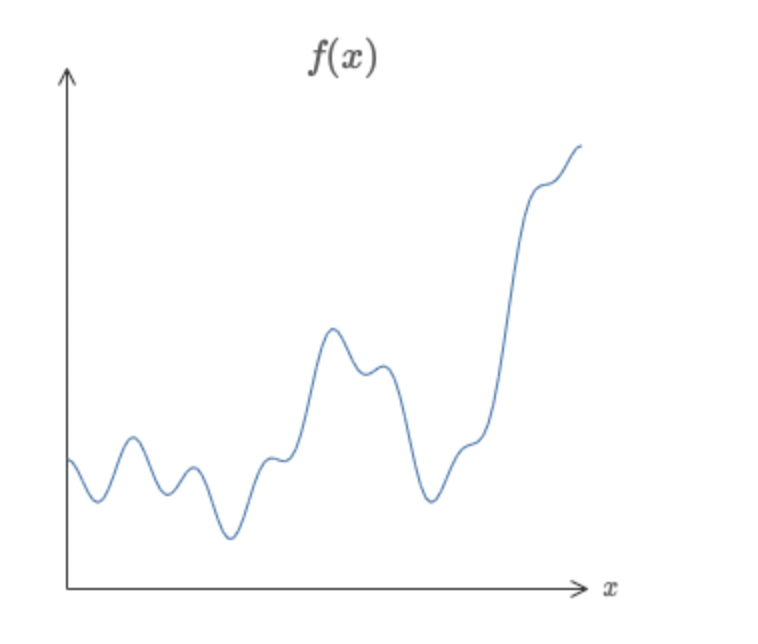
Introduction 베이지안 최적화 Bayesian Optimization, BayesOpt 는 함수의 최적화 문제를 해결하는 방법 중 하나, 목적함수 $f:\mathcal{X}\to\mathbb{R}$ 를 계산하는 비용이 클 때 사용할 수 있는 방법입니다. 함수의 계산비용이 클 경우 그래디언트를 계산하는 것 역시 큰 비용이 들기 때문에, 베이지안 최적화에서는 그래디언트 기반의 최적...
Introduction 이번 글에서는 eigenfunctions 고유함수 와 이를 기반으로 하는 커널 방법론들의 해석에 대해 다루어보도록 하겠습니다. 고유함수의 개념은 데이터를 분석하는 과정에서는 요구되지 않을 수 있습니다. 다만, 많은 머신러닝 방법론, 그 중에서도 Gaussian Process 기반 방법론들의 이해에 중요한 부분을 차지한다고 생각합니다. 기본적인 아이디어는 행렬의 고...
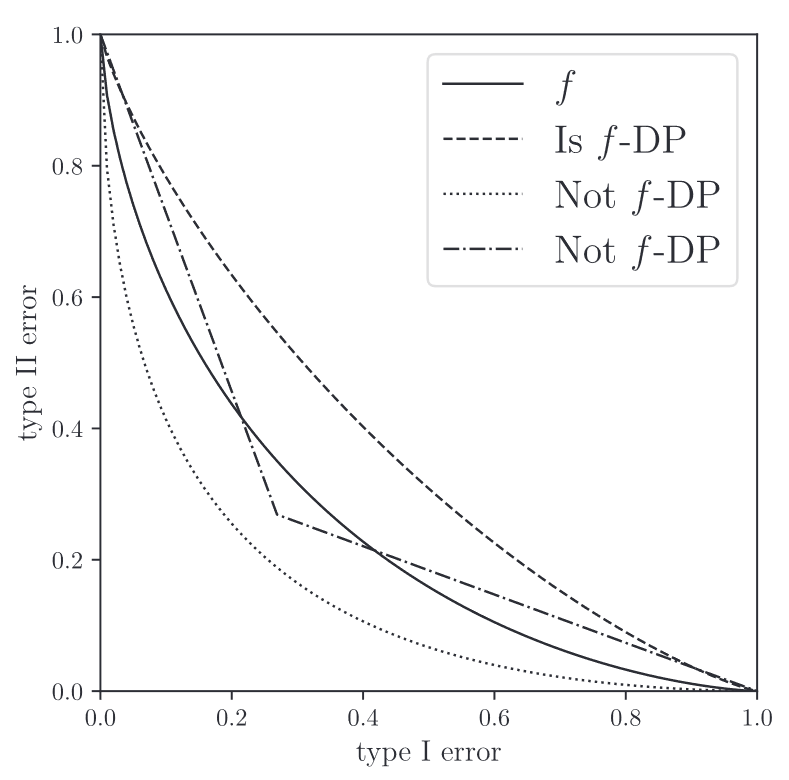
Introduction 이번 포스트에서는 Gaussian Differential Privacy (Dong et al., 2022) 논문을 리뷰하며 Gaussian differential privacy에 대해 살펴보도록 하겠습니다. DP는 $(\epsilon, \delta)$-DP 외에도 여러 relaxation가 존재합니다. Gaussian DP는 2022년 JRSSB에 위 논문으로부터...
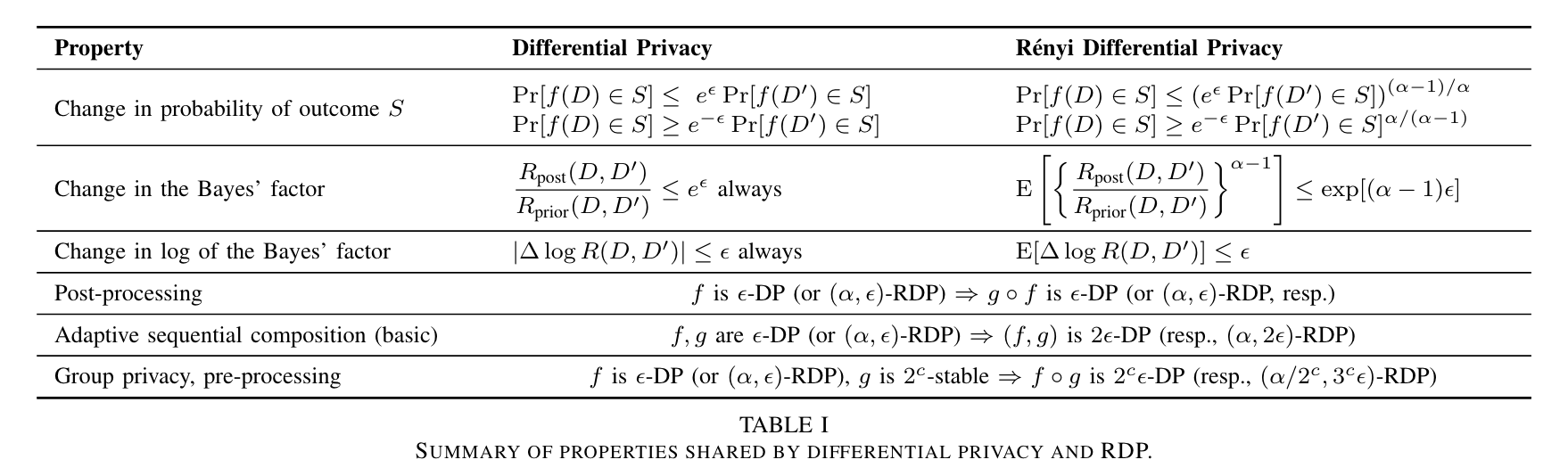
Rényi Differential Privacy Differential privacy는 초기 Dwork의 논문에서 $\epsilon$-DP, $(\epsilon,\delta)$-DP 형태로 제안되었습니다. 이후 CDP concentrated DP 등 다양한 형태의 변형이 등장하였고, 최근에는 가설검정 형태에 기반한 Gaussian DP (혹은 $f$-DP)의 개념도 등장하였습니다. 이러...
최근 딥러닝 관련 연구동향을 살펴보던 중, 일반적으로 널리 사용되던 MLP Multi-Layer Perceptron 를 대체할 수 있는 모델이 등장했다는 소식을 접했습니다. KAN Kolmogorov-Arnold Network 가 바로 그것인데 (Liu et al., 2024), 아직 저널이나 컨퍼런스에 발표되지는 않은 논문이지만 큰 화제를 모으고 있기도 합니다. 이번 글에서는 KAN의...

Variational Inference with DP 이번 글에서는 다음 두 논문 - Jälkö, J. et al., (2017). Differentially Private Variational Inference for Non-conjugate Models - Wang, Y. et al., (2015). Privacy for Free: Posterior Sampling and Stoch...
Cox Process Point Pattern 데이터를 모델링하는 일반적인 방법은 intensity function을 추정하는 것이다. 이때, intensity function이 $\lambda(x)=2\exp(-x)$ 와 같은 함수 형태로 주어질 수도 있지만, 이러한 함수를 직접 추정하는 것 대신 함수의 형태에 대해서도 추가적인 랜덤성을 가정하는 것이 가능하다. 이러한 방법을 Cox...

Stochastic Differential Equation DDPM 등의 Diffusion 모델은 확률미분방정식 Stochastic differential equation, SDE 의 형태로부터 구할 수 있다. 비록 SDE 기반의 diffusion 모델은 DDPM 등의 모델보다 뒤늦게 제안되었지만, SDE의 한 종류로 볼 수 있다. 이번 글에서는 diffusion 모델들의 근간이 되는...
Point Pattern on Linear Network 선형 네트워크 Linear Network 란 선분 line segment 들의 집합으로 구성되는 그래프 형태의 구조를 의미한다. 대표적으로 도시의 도로교통망이나 생태 분야에서 다루는 하천 네트워크 등이 이에 해당된다. 이번 글에서는 선형 네트워크 구조에서 주어지는 공간 점 과정에 대해 , intensity/density 추정이 어...
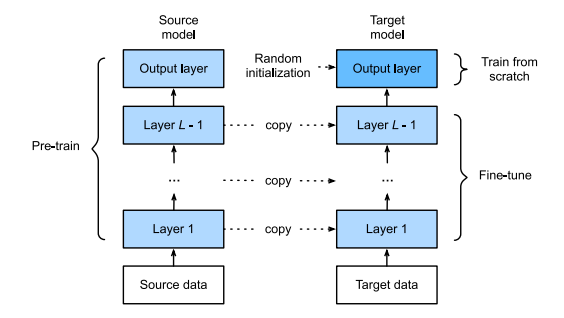
파인 튜닝 Fine Tuning 이란 개념은 LLM의 등장과 함께 더욱 주목받게 된 개념이다. 이전까지는 한번 모델을 학습시키고 나면, 해당 모델의 파라미터를 고정시키고 새로운 데이터 $\mathbf x'$에 대해 예측을 수행하는 방식이 일반적이었다. 그러나, 모델의 규모가 매우 커지면서(특히 Transformer의 등장 이후) 파라미터 수가 기하급수적으로 증가하였고 이로 인해 새로운...
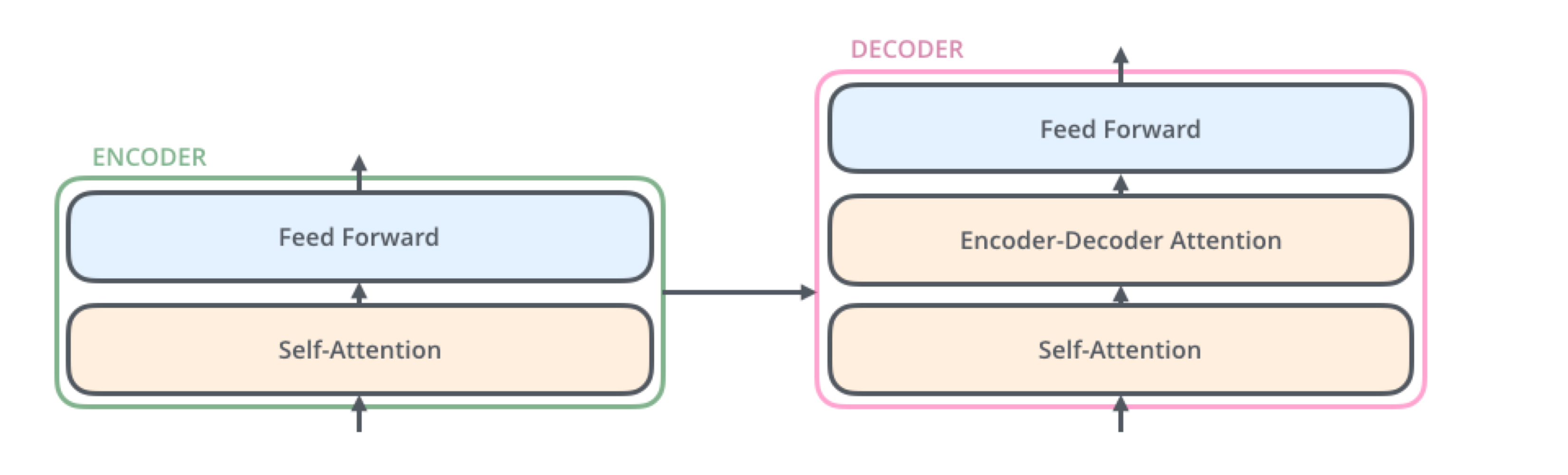
Transformer (Updated on 2024-04-12) 트랜스포머 Transformer 는 자연어 처리 분야에서 최근 주를 이루고 있는 딥러닝 모델이다. 이전까지는 LSTM 등의 순환신경망을 주로 이용했지만, sequence-to-sequence function approximation에서 대형 트랜스포머들이 좋은 성능을 보이는 것이 알려지며 주요 모델로 자리잡게 되었다. 트랜...
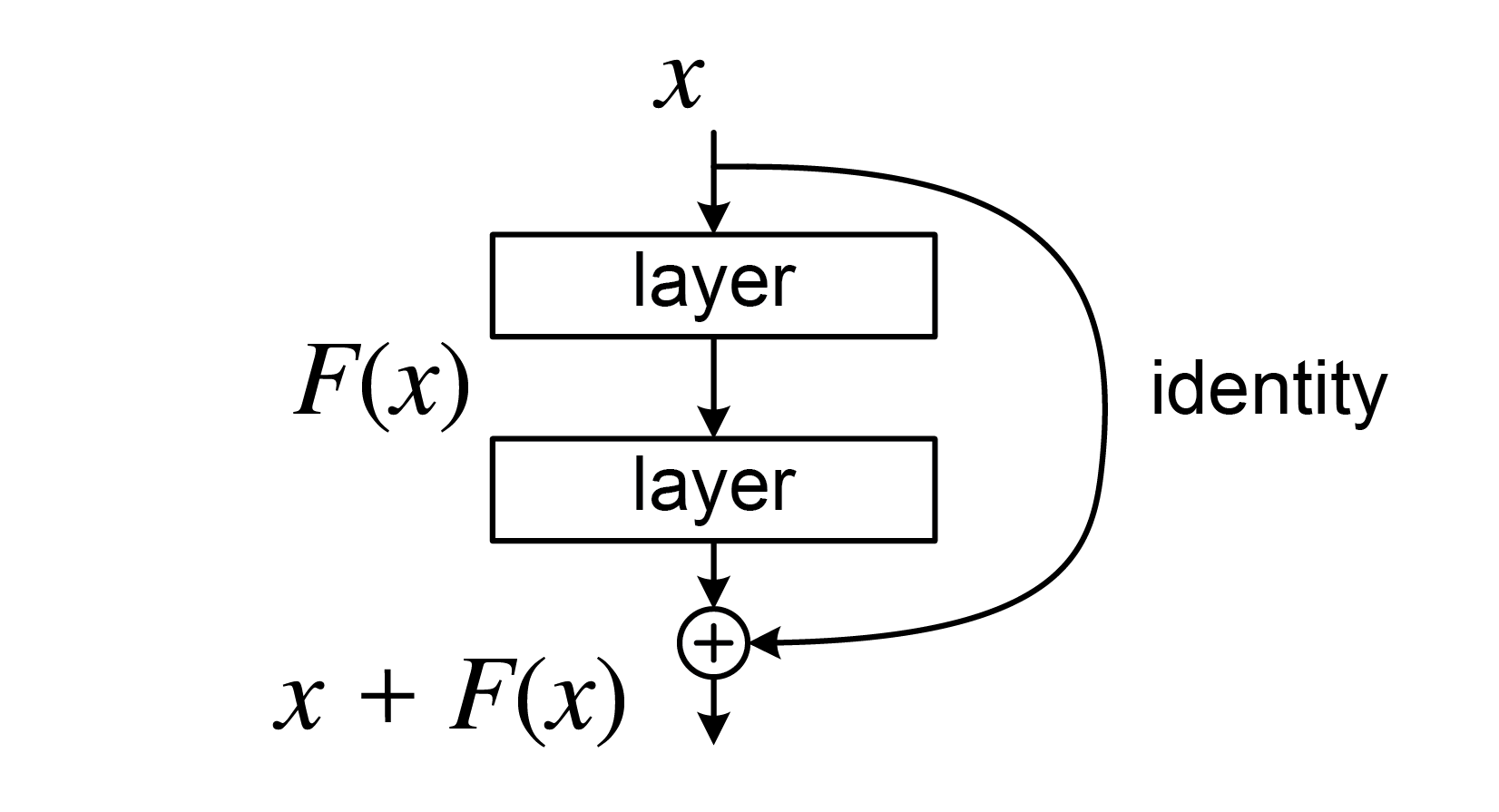
Neural ODE Neural ODE Neural Ordinary Differential Equation 를 다루기 전에 우선 깊이가 $L$인 (Hidden layer의 수가 $L$인) Residual Network Resnet 를 생각해보자 (아래 그림). Residual network (He et al., 2015) 일반적으로 Resnet은 각 레이어에 대해 다른 파라미터를 적용하...
PyMC and Bayesian 이번 글에서는 Python에서 MCMC 기반의 베이지안 분석을 할 수 있도록 고안된 PyMC 라이브러리를 소개해보도록 하겠습니다. PyMC에서는 비교적 간단한 MCMC부터, Bayesian neural network BNN 까지 폭넓은 분석을 진행할 수 있습니다. 여기서는 선형회귀모형과 로지스틱 회귀모형, 그리고 BNN을 활용한 분류를 다루어보도록 하겠습...
이번 글에서는 Point Process 데이터를 분석하는 방법에 대해 Pysal 패키지와 예제 데이터를 바탕으로 살펴보도록 하겠다. 이전에 정리본을 영어로 업로드해두어, 간단한 정의에 대해 먼저 다시 살펴보고, Python을 활용해 intensity meausre와 같은 point process 데이터의 주요 특징을 어떻게 분석하는지 다루어보도록 하겠다. Point Process Def...
이번 글에서는 이전에 Covariance models에서 살펴본 연속형 공간자료를 모델링하는 고전적인 공간통계 방법론들에 대해 살펴보도록 하겠다. 이전 글에서 연속형 geostatistical 자료를 표현하는 방법으로 variogram 등을 살펴보았는데, 이러한 방법을 데이터로부터 어떻게 추론해내는지를 이번 글의 주요 관심사로 볼 수 있다. Geostatistical Model Mode...

Covariance Models Definition 연속형 공간자료는 공간 $\mathcal{D}\subset \mathbb{R}^{d}$와 확률공간 $(\Omega,\mathcal{F},P)$ 에서 정의되는 일종의 확률과정 stochastic process $$ Z(s,\omega),s\in \mathcal{D}, \omega\in\Omega $$ 으로 나타낼 수 있다. 이때 $Z(s...
Differential Privacy Setting $D=(d{1},\ldots,d{n})\in \mathcal{D}$을 입력 데이터베이스라고 하자. 또한, $M:\mathcal{D} \to \mathbb{R}^{d}$를 non-private 알고리즘이라고 하고, $M(D)$를 그에 대응하는 출력이라고 하자. 그러면, 출력 공간 (e.g. $\mathbb{R}^{d}$)을 고려하여, 랜...
DL with DP 이번 포스트에서는 Deep Learning with Differential Privacy (Abadi et al., 2016) 논문을 리뷰하고자 합니다. 이 논문은 neural network 기반의 딥러닝 모델을 Differential Privacy를 만족하도록 학습하는 방법을 제시합니다. 이 과정에서 Stochastic gradient descent (SGD) 자체...

Introduction - Propose a differentially private generative adversarial network - Uses the Wasserstein distance which is better than JS-divergence, i.e. WGAN Framework - GAN : minimax game between generator and discrim...
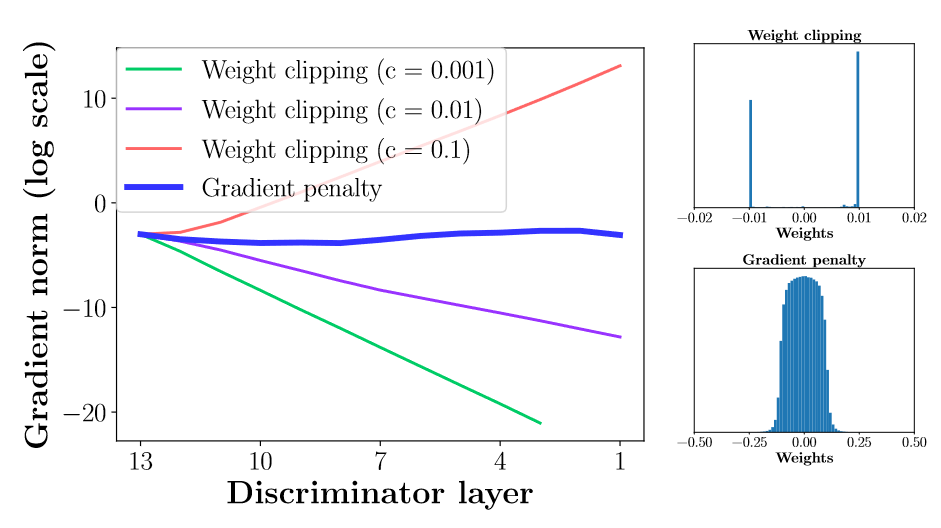
Wasserstein GAN 이전 글에서에 GAN Generative Adversarial Network 은 결과적으로 Jensen-Shannon divergence를 최소화하는 문제로 귀결되는 것을 확인했다. 이 경우 density ratio를 discriminator $D$로 추정하는 상황으로부터 도출되었는데, 이번에는 density ratio 대신 적분의 차이 형태로 주어지는 me...
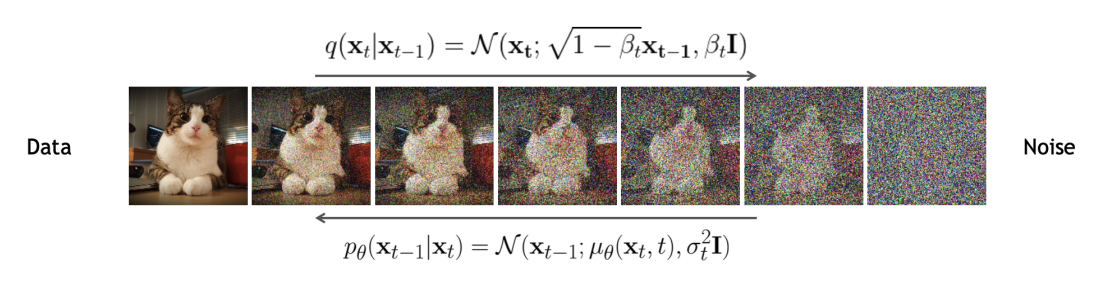
Diffusion Models 디퓨전 모델 Diffusion Models 은 최근 이미지 생성 분야에서 가장 널리 사용되고 있는 딥러닝 아키텍쳐 중 하나이고, VAE, Normalizing Flow 등의 모델과 유사하다. 기본적인 아이디어는 노이즈로부터 구조화된 데이터(e.g. 이미지)를 찾는 것은 어렵지만, 구조화된 데이터를 노이즈로 변환하는 것은 비교적 간단하다는 것이다.이러한 과정...

Generative Adversarial Networks 이번 글에서는 GAN 모델을 다루고자 한다. 다만, 일반적으로 GAN이 정의되는 방식 대신, 생성형 모델 중 implicit model에서 목적함수를 정의하는 방식을 기반으로 GAN의 목적함수가 도출되는 과정을 살펴보고자 한다. Generative Models 생성 모델 Generative Models 이란, 데이터의 분포($p(...
데이터사이언스 교재/참고자료 로드맵 평소 데이터사이언스의 다양한 분야에 대해 공부하며 여러 교재를 비교해보았습니다. 여러 교재나 참고자료를 보며 추천할만한 교재들을 정리해보면 좋을 것 같다는 생각에 데이터사이언스 로드맵을 만들게 되었습니다. 이 로드맵은 데이터사이언스를 공부하고자 하는 분들에게 도움이 되고자 만들어졌습니다. 데이터사이언스를 공부하고자 하는 분들은 아래 로드맵을 참고하여...
Gaussian Process and Neural Networks 신경망 구조는 일반적으로 Universal Approximation Theorem에 의해 비선형 함수를 근사하는데 효과적으로 이용된다. 이러한 특성을 이용하면, 다음과 같이 신경망의 구조적 특징과 가우시안 프로세스의 비모수적 유연성 nonparametric flexibility 을 결합한 커널을 구성할 수도 있다. $$...
Introduction Markov random field Let $G=(V,E)$ be a graph with $p$ nodes and $C{t}(G)$ be the set of cliques of size at most $t$ in $G$. A Markov random field with alphabet size $k$ and $t$-order interactions is a dis...
Summarize - Uniform grid approach for balancing the noise error and the non-uniformity error - Proposed a method for choosing the grid size. - Traditional differentially private methods for 2D datasets : quadtrees, kd...
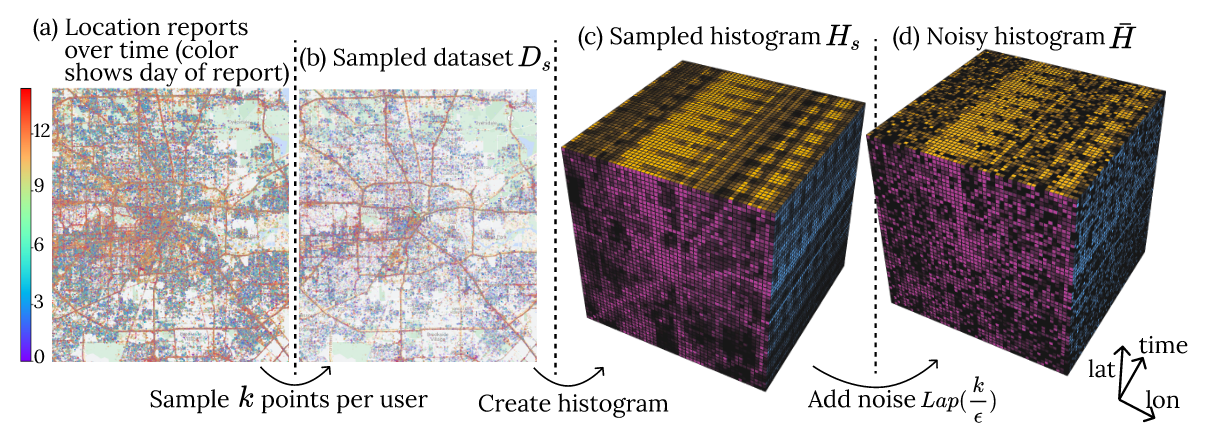
Intro - Most existing work on DP-publication of location data focuses on single snapshot releases (Cormode et al., 2012) - To release multiple snapshot, user-level privacy is required - Two key aspects : Bound sensiti...
본 포스트는 서울대학교 M2480.001200 인공지능을 위한 이론과 모델링 강의노트를 간단히 재구성한 것입니다. Differential Privacy 차등적 정보보호 differential privacy, DP 란, 데이터 분석 과정에서 개별 데이터의 정확한 값(privacy)을 보호하면서 동시에 분석의 결과를 일정 수준 보장할 수 있도록 하는 이론이다. 인과추론 연구에서 무작위 실험...
Normalizing flow 변분추론 Variational Inference 에서 사후분포를 근사하는 것은 가장 중요한 문제 중 하나이다. 일반적으로 사후분포를 근사할 때 정규분포 등 다루기 쉬운 분포를 surrogate distribution으로 사용하여 근사를 진행하는데, 이러한 과정의 문제점은 사후분포의 클래스가 제한된다는 점이다. 이러한 문제를 해결하기 위해 제안된 것이 Nor...
Optimal Transport Optimal Transport는 하나의 확률분포를 다른 확률분포로 옮기는데 필요한 비용을 계산하는 문제라고 생각하면 된다. 즉, 두 확률분포 간의 거리를 측정하는 것이 주요 목적이다. 이러한 문제는 다양한 분야에서 활용되는데, 예를 들어 이미지 처리에서는 두 이미지 간의 색상 분포를 매핑하는데 사용할 수 있다. 이번 포스트에서는 Optimal Trans...
Hidden Markov Model 은닉 마코프 모형 Hidden Markov Model, HMM 이란 message passing algorithm(or belief propagation algorithm)의 일종이다. 여기서 message passing이란, 그래프 구조에서 각 노드가 다음 노드로 정보를 전달하며 어떤 결론을 도출하는 과정을 의미하는데, 전달되는 정보는 확률분포 형태...

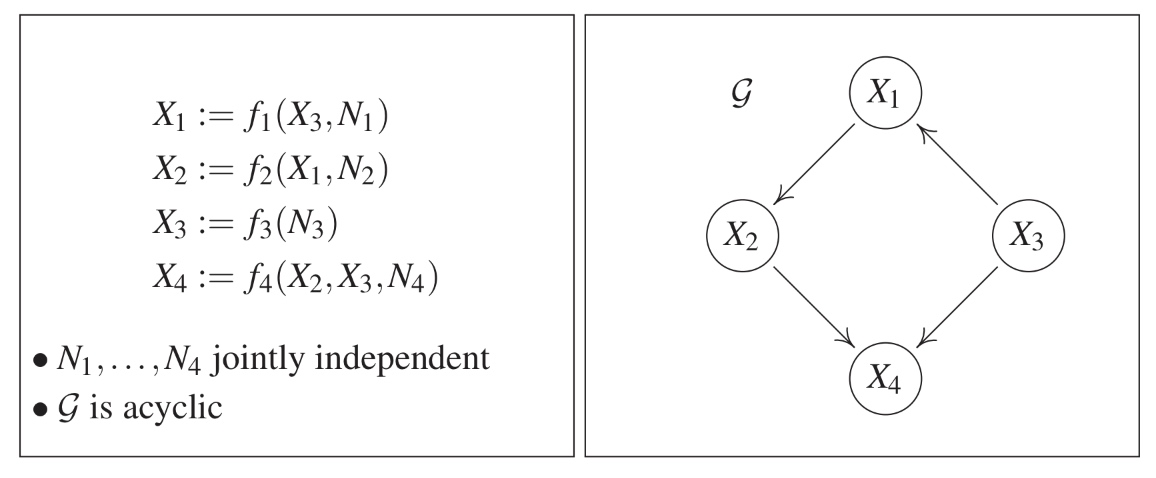
DAG-GNN 이번 포스트는 DAG-GNN: DAG Structure Learning with Graph Neural Networks의 논문 요약입니다. Graph Learning 그래프 학습 Graph Learning 이란, 주어진 관측 데이터 $\mathbf{X}$로부터 데이터가 생성된 그래프 $\mathcal{G}$의 구조를 추정하는 것이다. 그래프의 구조는 인접행렬 $A\in \...
Coordinate Ascent Variational Inference Variational Inference 변분추론 Variational Inference 이란, 베이지안 추론의 근사적 방법론 중 하나입니다. 베이지안 추론에서 사후분포의 확률밀도함수는 다음과 같이 계산할 수 있습니다. $$ p{Z|X}(z|x) = \frac{p{X|Z}(x|z)pZ(z)}{\int p{X|Z}(x|...
본 포스트는 서울대학교 M2480.001200 인공지능을 위한 이론과 모델링 강의노트를 간단히 재구성한 것입니다. Bayesian Network Bayesian network는 아래 예시와 같은 방향성 비순환 그래프(Directed Acyclic graph)를 의미합니다. 각 노드는 확률변수에 대응되는데, (위 예시는 PGM의 유명한 예제인 student network입니다) 각각의 확...
본 포스트는 서울대학교 M2480.001200 인공지능을 위한 이론과 모델링 강의노트를 간단히 재구성한 것입니다. Divergence 발산 Divergence 의 의미는 본래 미분기하학에서 정의되는데, 다양체 $M$에서의 두 점 $P,Q$와 좌표 coordinates $\xi{P},\xi{Q}$ 에 대해 정의되고 다음을 만족하는 함수 $D(P:Q)$ 를 의미한다. 1. $D(P:Q) \...
Sensitivity Analysis 관측 자료로부터 인과추론을 하기 위해서는 unconfoundedness, Overlap의 두 가지 가정이 필요하다. Overlap 가정은 각 처치대상을 기반으로 하므로, 관측 자료로부터 검정이 가능 testable 하다. 반면, unconfoundedness(혹은 ignorability) 가정은 본질적으로 검정은 불가능하지만, 간접적으로 검정할 수는...
ATE estimation 바로 이전 글에서 살펴보았듯이, 교란변수 confounder (공변량)이 모두 관측된다는 가정하에서 평균처치효과가 statistical estimand $\tau$의 함수로 식별가능함을 확인했다. 이제 이로부터 평균처치효과 ATE를 관측데이터로부터 어떻게 추정할지 다루어보도록 하겠다. 평균처치효과를 추정하는 방법에는 크게 두 가지 (1) Outcome Regr...
Bayesian Causal Inference Setting 각 샘플 단위(개체)에 대해 다음과 같이 네 가지 변수가 존재한다. $$ Y{i}(0), Y{i}(1), Z{i}\in\lbrace 0,1\rbrace ,X{i} $$ 이때 결과변수 $Y{i}$에 대해서는 하나만 관측된다. 즉, $$ Y{i}^{mis}=Y{i}(1-Z{i}) $$ 의 관계가 성립한다. 그렇다면, 주어진 처치변...
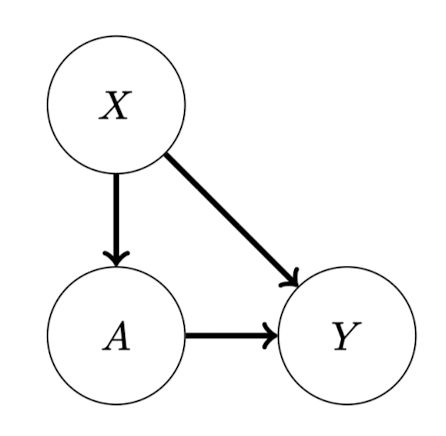
Confounder Adjustment 인과추론에서 실제로 인과관계를 규명해내는 가장 기본적인 방법은 Average Treatment Effect를 추정하는 것이다. 여기서는 아래와 같은 기본적인 SCM 예시를 바탕으로 살펴보도록 하겠다. 우선, 위 SCM에서 처치변수 $A$, 결과변수 $Y$, 공변량 $X$가 모두 관측가능하고 joint distribution $P$는 알려져있지 않다...
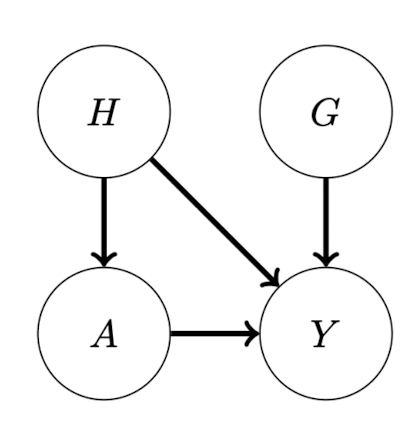
Average Treatment Effect Example 먼저, 이번 글에서 다룰 Structural Causal Model/)로 다음과 같은 예제를 설정하자. 아래 SCM은 흡연 여부 $A$, 암 발병여부 $Y$, 건강 자각도(?) health conciousness $H$, 그리고 유전적 요인 $G$의 인과관계에 대한 것이다. 이때 처치변수는 노드 $A$에 해당한다. Definit...
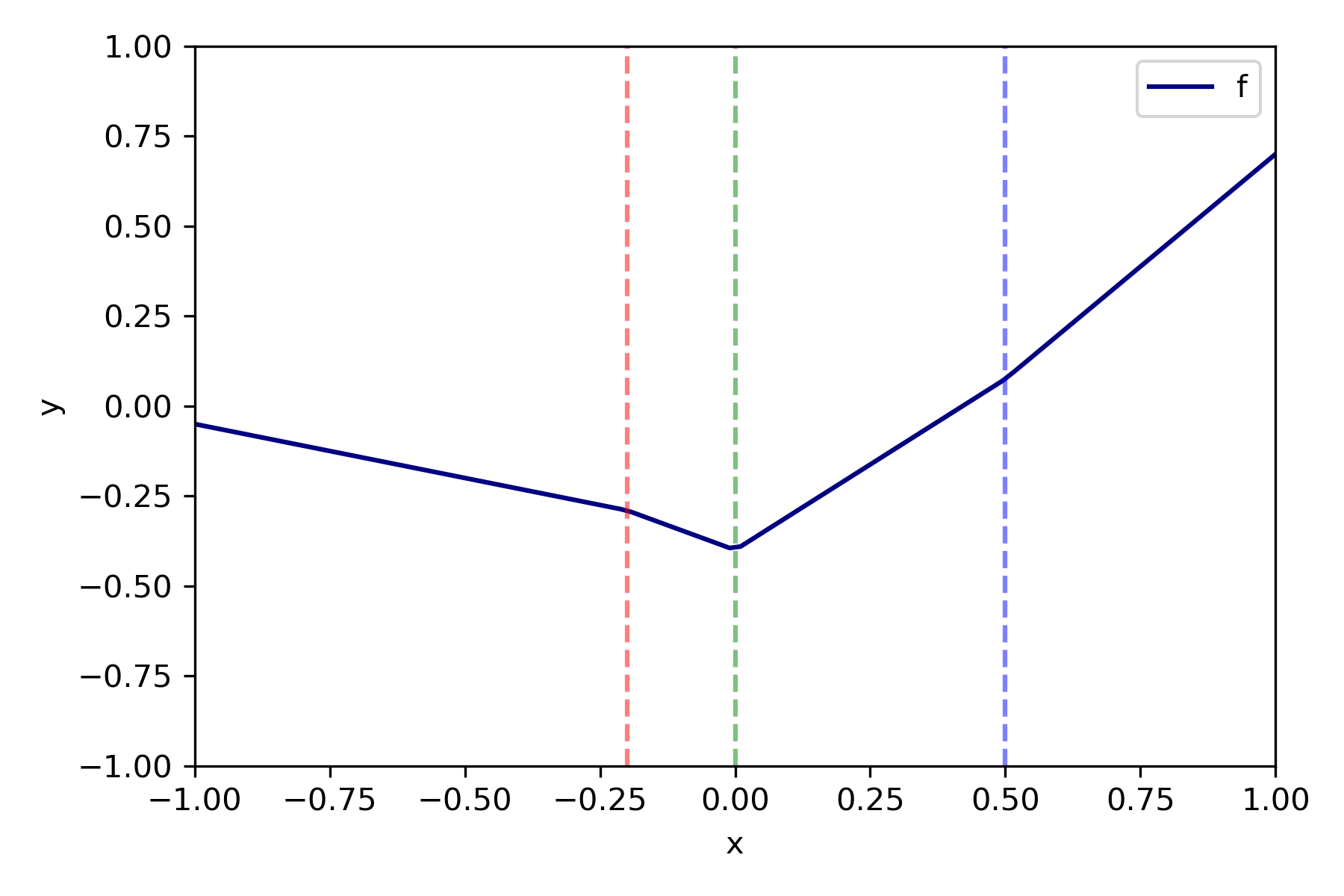
Universal Approximation Theorem 딥러닝이 예측 문제에서 매우 높은 성능을 발휘하는 이유 중 하나는, 바로 딥러닝을 통해 근사한 함수가 보간 interpolation 에 가깝게 원래 함수를 근사한다는 것이다. 바꾸어 말하면, 어떠한 함수든 신경망으로 근사할 수 있다는 것인데, 이러한 이론적 배경을 Universal Approximation Theorem이라고 한다...
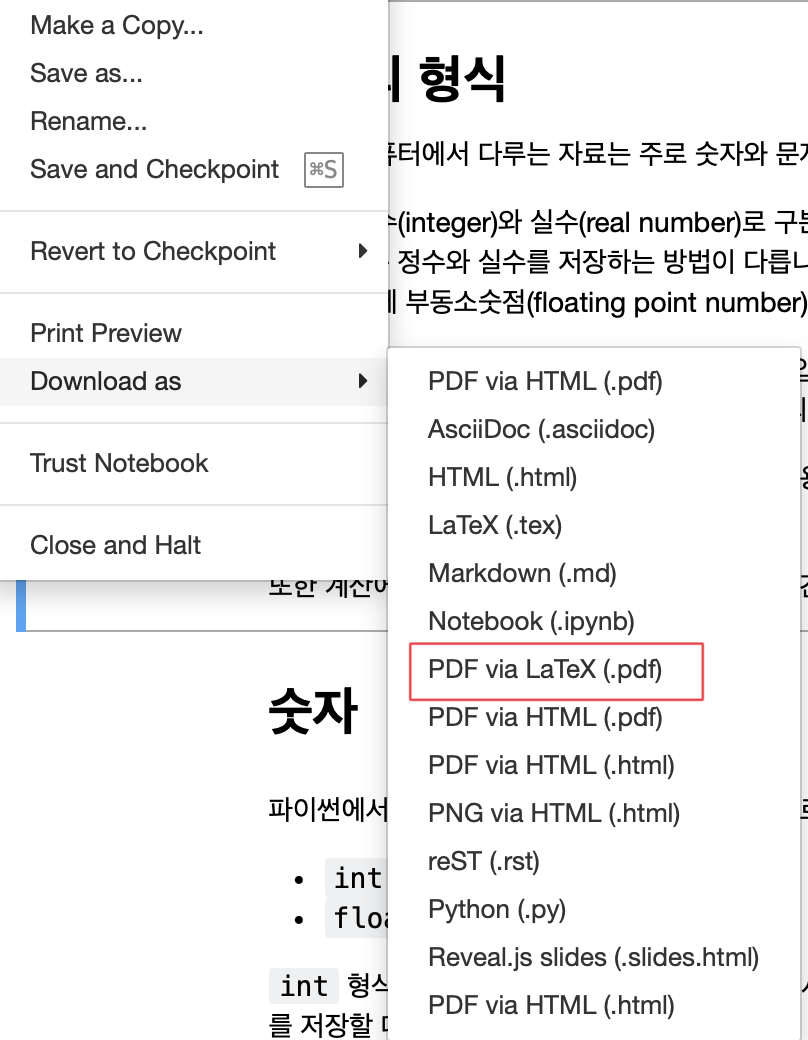
Jupyter Notebook Pdf 변환하기 Jupyter Notebook으로 강의자료를 만들고 pdf 변환을 시도하던 중, 여러 문제들이 있어 해결하고 각각의 해결 방안을 공유하고자 한다. Jupyter Notebook을 아나콘다(miniforge3) 환경에서 사용하기 때문에, 각자 로컬환경에 따라 유동적으로 경로나 이름 등을 확인하면 될 것 같다. Jupyter > Latex >...

[level 3] 양과 늑대 - 92343 문제 링크 성능 요약 메모리: 10.2 MB, 시간: 0.28 ms 구분 코딩테스트 연습 > 2022 KAKAO BLIND RECRUITMENT 채점결과 Empty 문제 설명 문제 설명 2진 트리 모양 초원의 각 노드에 늑대와 양이 한 마리씩 놓여 있습니다. 이 초원의 루트 노드에서 출발하여 각 노드를 돌아다니며 양을 모으려 합니다. 각 노드를...
이진 트리 트리 {: .align-center} 트리 Tree 혹은 트리형 자료구조란, 그래프의 일종으로 부모노드-자식노드의 관계로 자료 구조를 표현한 것을 말한다. 위 그림과 같이 초기 시작노드 Root Node (빨간색 테두리 노드)를 기반으로 아래로 자식노드와 그들의 자식노드를 순차적으로 표현한다. 트리 노드의 특징은, 서로 다른 두 노드를 연결하는 경로가 유일하게 존재한다는 것이...
[level 3] 길 찾기 게임 - 42892 문제 링크 성능 요약 메모리: 10.2 MB, 시간: 0.01 ms 구분 코딩테스트 연습 > 2019 KAKAO BLIND RECRUITMENT 채점결과 Empty 문제 설명 길 찾기 게임 전무로 승진한 라이언은 기분이 너무 좋아 프렌즈를 이끌고 특별 휴가를 가기로 했다. 내친김에 여행 계획까지 구상하던 라이언은 재미있는 게임을 생각해냈고...
최단 경로 알고리즘 최단 경로 알고리즘은 그래프에서 노드 사이의 최단 경로를 찾는 알고리즘이다. 비단 그래프 뿐 아니라 그래프를 활용하는 거리 계산에도 이용되는데, 예를 들어 manifold 상에서 geodesic distance를 구할 때에도 이용된다. 일반적으로 컴퓨터공학과 학부 수준에서 사용되거나 코딩 테스트에서 사용되는 알고리즘은 Dijkstra, Floyd-Warshall 알고...
[level 2] 게임 맵 최단거리 - 1844 문제 링크 성능 요약 메모리: 10.4 MB, 시간: 5.14 ms 구분 코딩테스트 연습 > 깊이/너비 우선 탐색(DFS/BFS) 채점결과 Empty 문제 설명 ROR 게임은 두 팀으로 나누어서 진행하며, 상대 팀 진영을 먼저 파괴하면 이기는 게임입니다. 따라서, 각 팀은 상대 팀 진영에 최대한 빨리 도착하는 것이 유리합니다. 지금부터 당...
[level 3] 합승 택시 요금 - 72413 문제 링크 성능 요약 메모리: 10.2 MB, 시간: 0.86 ms 구분 코딩테스트 연습 > 2021 KAKAO BLIND RECRUITMENT 채점결과 Empty 문제 설명 [본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.] 밤늦게 귀가할 때 안전을 위해 항상 택시를 이용하던 무지 는 최근 야근이 잦아져 택시를 더 많이...
[level 2] 전력망을 둘로 나누기 - 86971 문제 링크 성능 요약 메모리: 10.3 MB, 시간: 3.09 ms 구분 코딩테스트 연습 > 완전탐색 채점결과 Empty 문제 설명 n개의 송전탑이 전선을 통해 하나의 트리 형태로 연결되어 있습니다. 당신은 이 전선들 중 하나를 끊어서 현재의 전력망 네트워크를 2개로 분할하려고 합니다. 이때, 두 전력망이 갖게 되는 송전탑의 개수를...
이전에 지킬 블로그를 시작하면서, 태그 기능을 완벽하게 구현해내신 블로그가 있길래 아이디어를 참고하여 게시글 리스트를 보여주는 화면에 태그 정렬 기능을 위 그림과 같이 설정해보았다. 현재 사용하고 있는 Jekyll의 블로그 테마는 minimal-mistake 이므로 본인이 사용하고 있는 테마의 파일구조에 맞추어서 확인하면 될 것이다. 포스트에 태그 추가하기 Jekyll에서 포스트를 작성...
Markov Random Field Markov Random Field란, 공간자료 중 격자형(lattice) 자료를 모델링하기 위해 사용되는 모델이다. 격자형 자료란, 말그대로 (규칙적 혹은 불규칙적) 격자 단위에서 변수들의 값이 주어지는 것을 의미한다. 이때 데이터셋을 구성하는 각 격자는 정사각형이나 정육각형처럼 규칙적일 필요는 없지만, 격자들 간의 인접구조(neighborhood...
[level 2] 피보나치 수 - 12945 문제 링크 성능 요약 메모리: 13.9 MB, 시간: 23.94 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 피보나치 수는 F(0) = 0, F(1) = 1일 때, 1 이상의 n에 대하여 F(n) = F(n-1) + F(n-2) 가 적용되는 수 입니다. 예를들어 F(2) = F(0) + F(1) = 0 + 1 = 1...
[unrated] 당구 연습 - 169198 문제 링크 성능 요약 메모리: 10.3 MB, 시간: 1.40 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 프로그래머스의 마스코트인 머쓱이는 최근 취미로 당구를 치기 시작했습니다. 머쓱이는 손 대신 날개를 사용해야 해서 당구를 잘 못 칩니다. 하지만 끈기가 강한 머쓱이는 열심히 노력해서 당구를 잘 치려고 당구 학원에...
[unrated] 광물 캐기 - 172927 문제 링크 성능 요약 메모리: 10.1 MB, 시간: 0.03 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 마인은 곡괭이로 광산에서 광석을 캐려고 합니다. 마인은 다이아몬드 곡괭이, 철 곡괭이, 돌 곡괭이를 각각 0개에서 5개까지 가지고 있으며, 곡괭이로 광물을 캘 때는 피로도가 소모됩니다. 각 곡괭이로 광물을 캘 때...
[level 3] 정수 삼각형 - 43105 문제 링크 성능 요약 메모리: 14.5 MB, 시간: 36.99 ms 구분 코딩테스트 연습 > 동적계획법(Dynamic Programming) 채점결과 Empty 문제 설명 위와 같은 삼각형의 꼭대기에서 바닥까지 이어지는 경로 중, 거쳐간 숫자의 합이 가장 큰 경우를 찾아보려고 합니다. 아래 칸으로 이동할 때는 대각선 방향으로 한 칸 오른쪽...
[unrated] 과제 진행하기 - 176962 문제 링크 성능 요약 메모리: 10.7 MB, 시간: 1.65 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 과제를 받은 루는 다음과 같은 순서대로 과제를 하려고 계획을 세웠습니다. 과제는 시작하기로 한 시각이 되면 시작합니다. 새로운 과제를 시작할 시각이 되었을 때, 기존에 진행 중이던 과제가 있다면 진행 중이던...
[unrated] 연속된 부분 수열의 합 - 178870 문제 링크 성능 요약 메모리: 10.2 MB, 시간: 0.00 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 비내림차순으로 정렬된 수열이 주어질 때, 다음 조건을 만족하는 부분 수열을 찾으려고 합니다. 기존 수열에서 임의의 두 인덱스의 원소와 그 사이의 원소를 모두 포함하는 부분 수열이어야 합니다. 부분 수...
크롬 브라우저의 백준허브를 이용하면 프로그래머스와 백준에서 푼 코딩테스트 연습문제들을 깃허브에 자동으로 커밋&푸시 해주는데, 이 결과를 이용해 아래처럼 블로그에도 자동으로 포스트를 생성할 수 있게 코드를 짜보았다. 1. 로컬저장소에 알고리즘 깃 저장소 불러오기 2. 디렉토리 변수 설정 blogdir와 targetdir 에 ...은 자신의 로컬 환경에 맞게 수정하면 된다. question...
[unrated] 요격 시스템 - 181188 문제 링크 성능 요약 메모리: 10.1 MB, 시간: 0.00 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 A 나라가 B 나라를 침공하였습니다. B 나라의 대부분의 전략 자원은 아이기스 군사 기지에 집중되어 있기 때문에 A 나라는 B 나라의 아이기스 군사 기지에 융단폭격을 가했습니다. A 나라의 공격에 대항하여 아이...
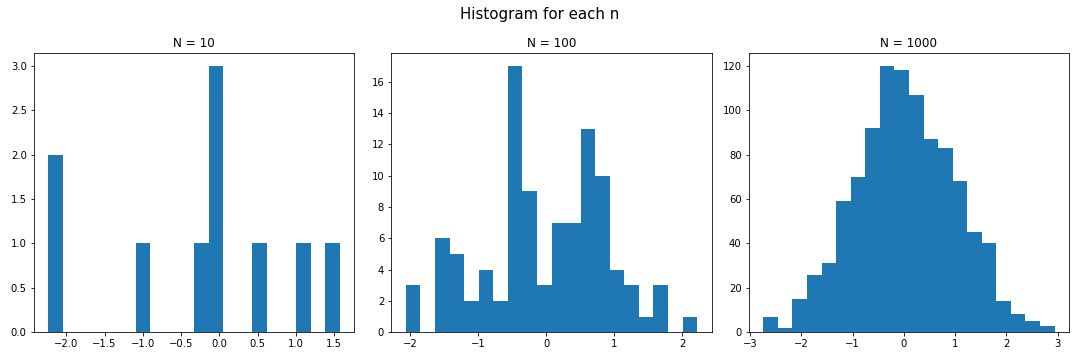
Generating random samples 이번 글에서는 주어진 확률분포로부터 랜덤 샘플들을 생성하는 방법에 대해 살펴보도록 하자. Simple method 만약 표본을 추출하고자 하는 대상 확률분포가 분포함수(cdf)로 주어지고, 그것의 역함수를 구할 수 있다면 다음 정리로부터 쉬운 표본추출이 가능하다. Theorem 만약 확률변수 $U$가 균등분포 $\mathrm{Unif}[0,...
[unrated] 두 원 사이의 정수 쌍 - 181187 문제 링크 성능 요약 메모리: 10.2 MB, 시간: 928.27 ms 구분 코딩테스트 연습 > 연습문제 채점결과 Empty 문제 설명 x축과 y축으로 이루어진 2차원 직교 좌표계에 중심이 원점인 서로 다른 크기의 원이 두 개 주어집니다. 반지름을 나타내는 두 정수 r1 , r2 가 매개변수로 주어질 때, 두 원 사이의 공간에 x...
Kolmogorov-Smirnov Test 일반적으로 데이터사이언스에서 데이터의 정규성을 검정하고자 할 때, 샘플 수가 적은 경우 Shapiro-Wilk 검정을 이용하고 그렇지 않은 경우 Kolmogorov-Smirnov(줄여서 ks) 검정을 이용한다고 알려져 있다. 사실 콜모고로프-스미르노프 검정은 정규성을 검정한다기 보다는 주어진 데이터로부터 얻은 경험적 분포(empirical di...
The contents are mainly based on Professor ChaeYoung Lim's lecture materials and \"Handbook of Spatial Statistics\"(2010) textbook. In this chapter, we introduce some spatial methodology for disease mapping. Disease m...
The contents are mainly based on "Handbook of Spatial Statistics"(2010) textbook. In this chapter, we introduce some basic concept related to hierarchical modeling strategies for handling and modeling spatial data. Hi...

Matrix Completion {: .align-center width="50%"} 행렬에서의 결측치(missing data) 문제는 최근 데이터사이언스 분야에서 중요한 화두이다. 특히 Netflix, Youtube 등의 알고리즘 기반 미디어 플랫폼들이 등장하며 사용자에게 적합한 미디어를 추천해주는 알고리즘이 중요해졌다. 추천 알고리즘의 큰 비중을 차지하는 협업 필터링(Collabor...
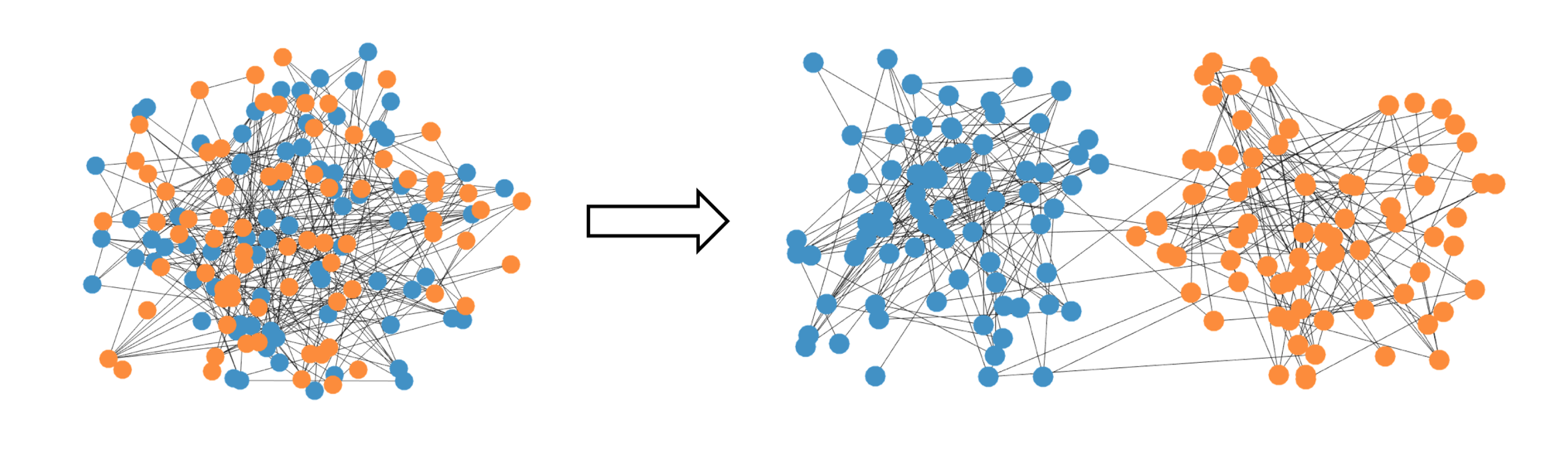
Graph Clustering Graph Clustering Graph Clustering(혹은 community recovery)란, 위 그림과 같이 그래프의 노드들을 서로 다른 커뮤니티(그룹)으로 나누는 방법론을 의미한다. 특히 소셜 미디어의 발달로 인해 최근 들어 개인간 연결성이 강조되며, SNA(social network analysis) 영역에서 주로 연구되는 방법론이며, 컴퓨...
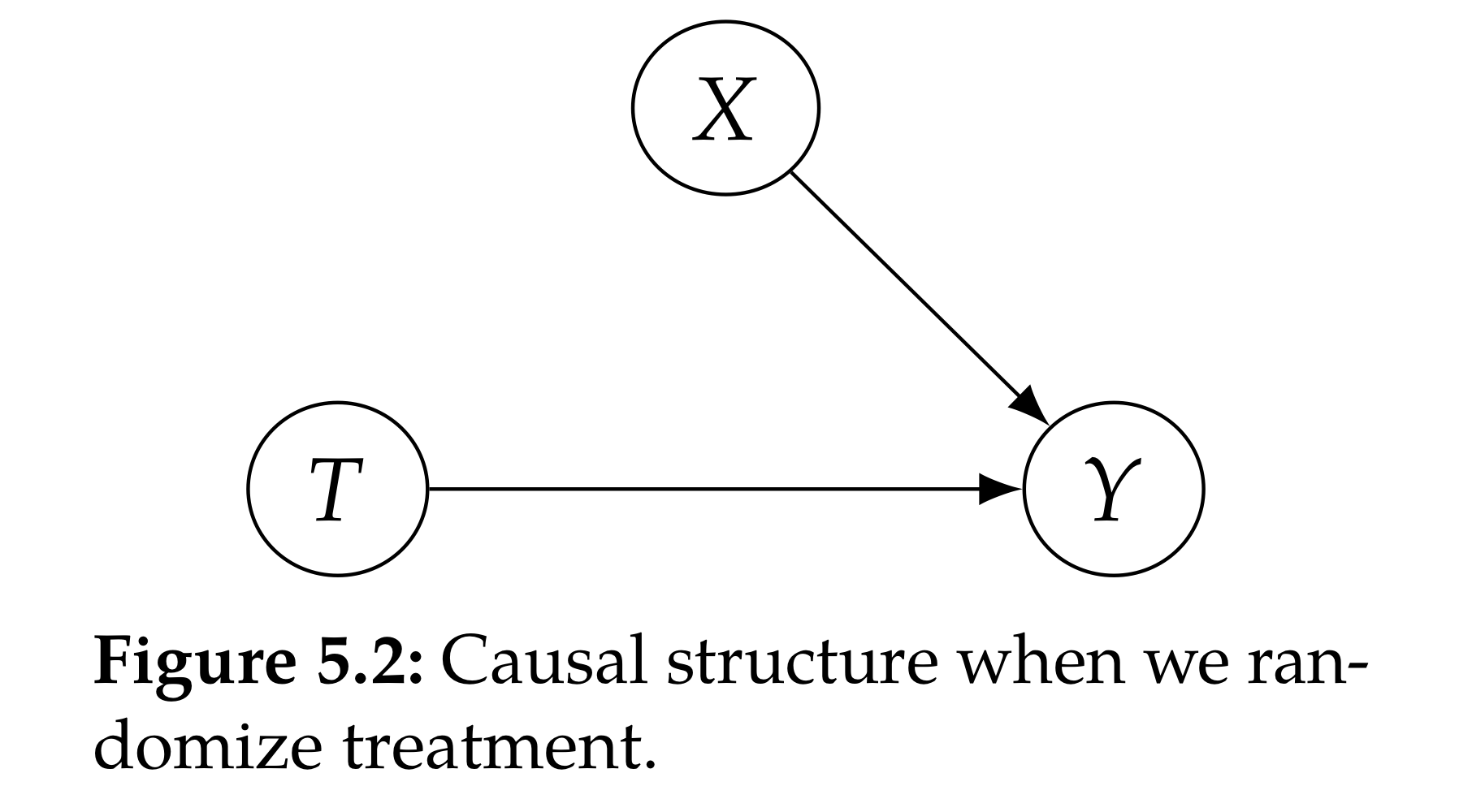
Randomized Experiment Randomized Experiment, 혹은 Randomized Control Test(RCT)라고 부르는 실험 계획 방식은 일반적인 연구방법에 약간의 확률변수를 추가하여 인과추론을 가능하게끔 하는 실험 방식이다. 일반적인 관찰 연구에서는(ex. 의학/약학 연구) 실험군(treatment group)과 대조군(control group)을 나누기...
Preliminary Matrix Bernstein Inequality Theorem Independent random matrix sequence $$\lbrace X{i}\rbrace {1\leq i\leq m}, X{i}\in\mathbb{R}^{n{1}\times n{2}}$$ 에 대해 다음을 가정하자. $$ \begin{aligned} \mathbb{P}(\Vert X{i}-\...
PCA and Factor Models PCA는 Spectral analysis의 대표격인 방법론으로, 데이터 차원 축소, 시각화, 이상치 탐지 등 여러 가지 목적으로 활용가능하다. 여기서는 Perturbation Theory를 바탕으로 PCA와 Factor model을 다루어보도록 하겠다. Problem Formulation 고차원 데이터 간의 종속성(dependence)를 측정하는...
Basics of matrix analysis Perturbation 실행렬 $M^{\star}$와 교란(perturbed)된 실행렬 $M$ 에 대해 다음 관계를 가정하자. $$ M=M^{\star}+E $$ 여기서 $E$는 perturbation matrix 라고 하며, 통계학적인 관점에서 $M, M^{\star}$ 이 각각 관측치와 기댓값이라면 $E$를 오차 정도로 볼 수 있다(아래...
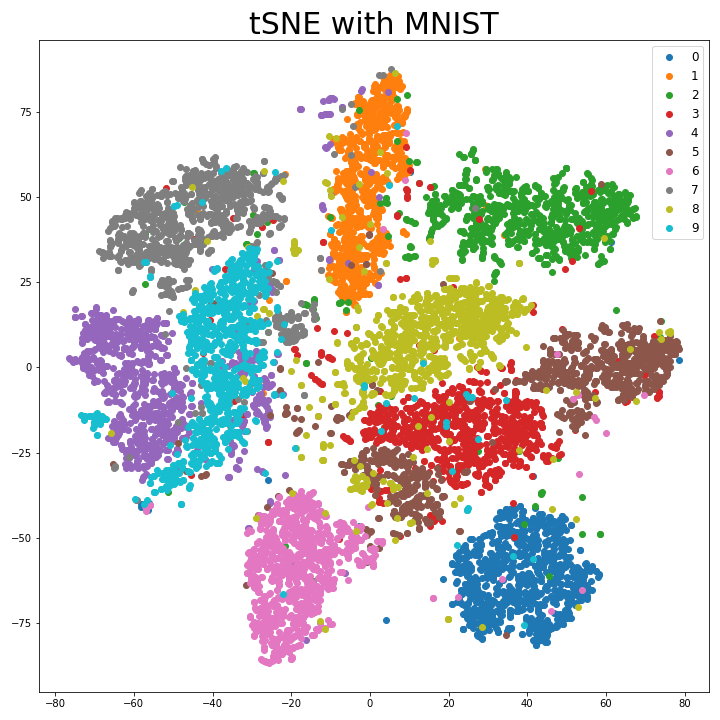
t-distributed Stochastic Neighbor Embedding Stochastic Neighbor Embedding Stochastic Neighbor Embedding이란 고차원 공간에서 각 데이터들의 유사성(similarity)을 조건부 확률로 나타내는 차원축소 내지 클러스터링 기법을 의미한다. 가까운 데이터들에 대해서 조건부 확률을 크게 설정한다. 이를 수식으로 다...
Point Process Definition Notation - $\mathcal{S}$ : a metric space with metric $d$ - $X$ : point process on $\mathcal{S}$ - $x$ : realization of a point process $X$ - $x$ is said to be locally finite if $n(xB) 0$. $wd...
Testing CSR Monte Carlo Tests - Let $T$ be any test statistic where larger $T$ cast doubt on the null hypothesis. - Let $t1$ be the value of $T$ calculated from dataset. - For convenience, assume that the null samplin...
Complete Spatial Randomness As the first step to analyze spatial point pattern data, we need to check CSR, the complete spatial randomness. Preliminaries 1 Consider a point process $N$, as a random counting measure on...

Robust PCA Background Robust PCA는 Principal component analysis가 그 이름에 포함되어 있지만, 본질적으로 접근 방식이 일반적인 PCA와는 사뭇 다르다. PCA는 일반적으로 특이값분해(SVD)를 이용해 분산을 최대화하는 고유벡터와 그것에 대한 projection을 구하는 방식이다. 다만, PCA의 경우 이상치에 대해 매우 민감한데, 아래 그...
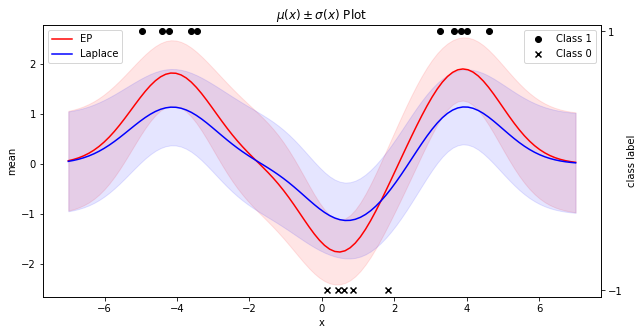
Expectation Propagation(EP) 알고리즘은 Laplace approximation에서 살펴본 것과 같이 사후확률분포를 근사하는 알고리즘 중 하나이다. 이번 글에서는 Expectation Propagation 알고리즘을 살펴보고 Gaussian Process에 어떻게 적용될 수 있는지와 Laplace approximation과 어떤 성능 차이를 보이는지를 살펴보고자 한다...
SOM 이라고 줄여 부르는 Self-organizing maps는 고차원(High dimensional) 데이터를 저차원(주로 2차원 평면)에 표현하는 차원축소 기법의 일종이다. 차원축소 기법으로 많이 사용되는 PCA와는 다르게, SOM은 데이터의 고차원 구조(topological structure)를 보존하여 Feature space에 embedded된 2D manifold(다양체)로...
Classification Problem 분류 문제의 두 가지 관점 베이지안 관점에서 분류(Classification) 문제를 정의하는 과정을 생각해보면, 설명변수 $\mathbf{x}$와 반응변수(class) $y$의 결합확률분포 $p(y,\mathbf{x})$를 접근하는 방식에 두 가지 방법이 있음을 고려할 수 있다. $$ p(y,\mathbf{x}) = p(y)p(\mathbf{x...
바로 이전 글에서 Gaussian Process classifier는 사후확률분포가 정규분포형태가 아니고, 이로 인해 직접 계산이 어렵다는 점을 살펴보았다. Laplace Approximation은 사후확률분포 $p(\mathbf{f}\vert X,y)$ 를 정규분포 형태로 근사할 수 있는 테크닉이다. Laplace Approximation 베이즈 규칙에 의해 latent variabl...
Gaussian Process는 함수들의 사전분포에 대한 것이다. 이때, 함수들의 사전분포를 정하는 이유는 주어진 데이터로부터 함수를 추정하는 과정에서 특정 조건을 부여하여 추론 혹은 예측 과정을 더 용이하게 하기 위함이다. 이 과정에서 Gaussian, especially Multivariate Gaussian distribution을 사용하는 이유는 조건부 확률분포의 정규성 등 Ga...
Introduction to DL Traditional Linear Model > suffers at specific tasks(ex. MNIST) - Why : Designed to use at low-dimensional data - At higher dimension(ex. Image, Video data) : curse of dimensionality occurs - How ab...
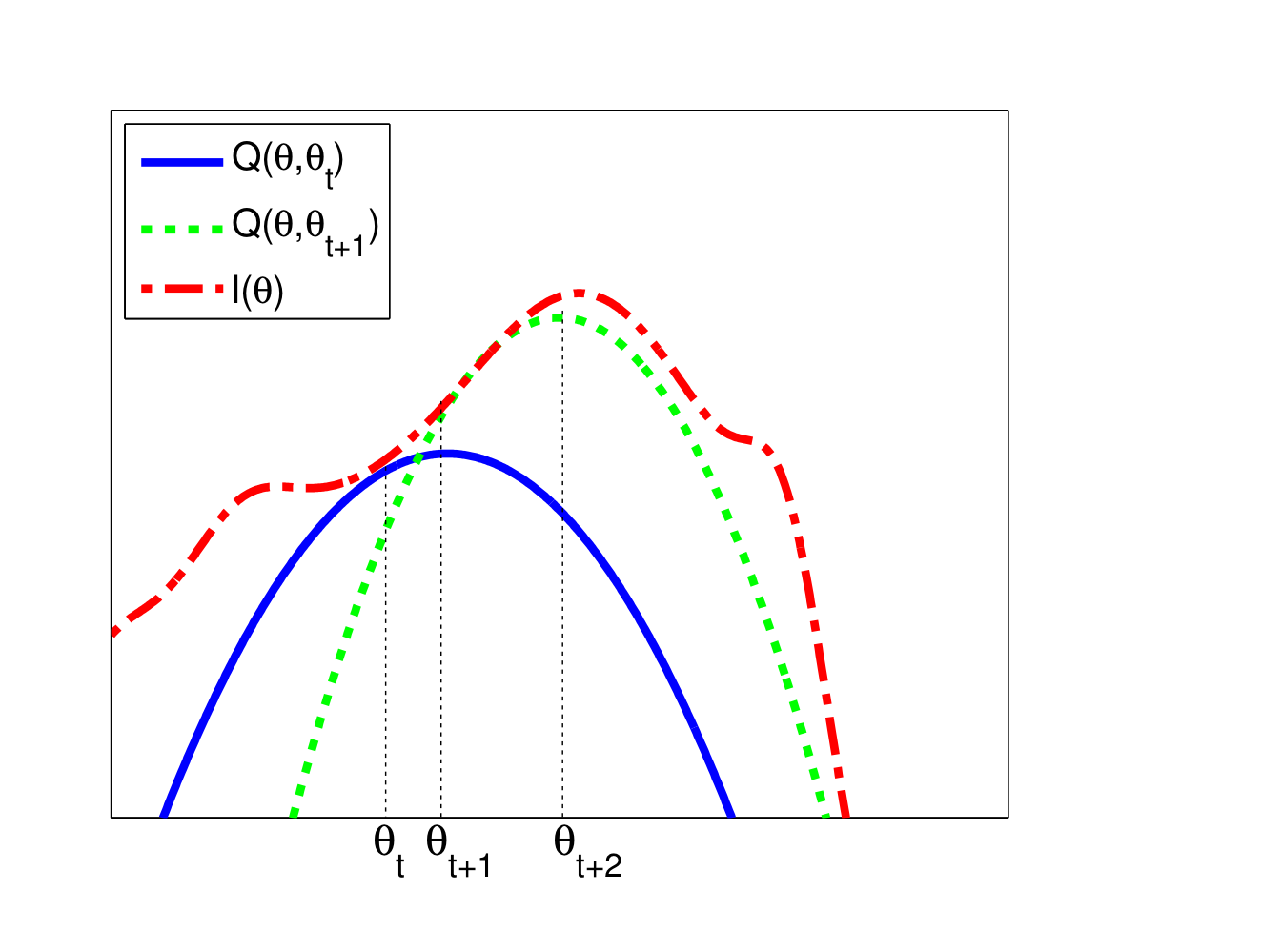
MM algorithm은 EM algorithm의 일반화된 버전으로 이해하면 되는데, MM은 maximization 관점에서 minorize-maximize를 나타낸다. MM algorithm은 최대화하고자 하는 목적함수 $l(\theta)$ 에 대한 lower bound function(surrogate function) $Q(\theta,\theta^{t})$ 를 찾고 이를 maxi...
Fixed and Random effect $i$번째 그룹에 대한 $j$번째 관측값 $y{11},\ldots,y{nn}$ 들이 주어질 때, 이들의 평균을 모델링하는 다음과 같은 모형을 생각해보자. $$ \mathrm{E}[y{ij}] = \mu + \alpha{i}+\epsilon{ij} $$ 이때 각 parameter $\mu,\alpha$ 는 평균에 영향을 미치는 모수이고 $\mu$...
데이터사이언스 영역에서 갈수록 중요해지는 토픽 중 하나인 추천시스템 recommender system 에 대해 공부해 포스팅해보고자 한다. 추천시스템의 목적은 궁극적으로 사용자에게 적절한 아이템을 추천해주는 것인데, 기존의 statistical learning model과는 다른 상황이 분명히 존재한다. 사용자에게 추천해주는 아이템은 그 사용자가 경험해보지 못한 아이템, 즉 유저 피드백...
일반화 선형모형(GLM)은 일반적인 선형모형(Linear Model, 반응변수와 설명변수의 관계가 선형이고 오차항의 분포가 normal인 모형)을 확장한 모형이다. 확장 방식은 반응변수와 설명변수의 관계를 nonlinear(ex. Exponential form)하게 바꾸거나, 혹은 오차항의 분포를 정규분포가 아닌 다른 분포로 가정하는 것이다. GLM을 정의하기 위해서는 세 가지 요소가...
이번 포스트에서는 통계학의 추정, 검정 등에서 중요하게 사용되는 통계량의 충분성에 대해 정리하고자 한다. 확률공간 $(\Omega,\mathcal{F},P)$ 을 이용해 random experiment를 정의할 때, 우리는 확률측도 $P$를 population이라고 정의하기도 한다. 이때 random sample이란, 주어진 population $P$로부터 데이터를 생성하는 random...
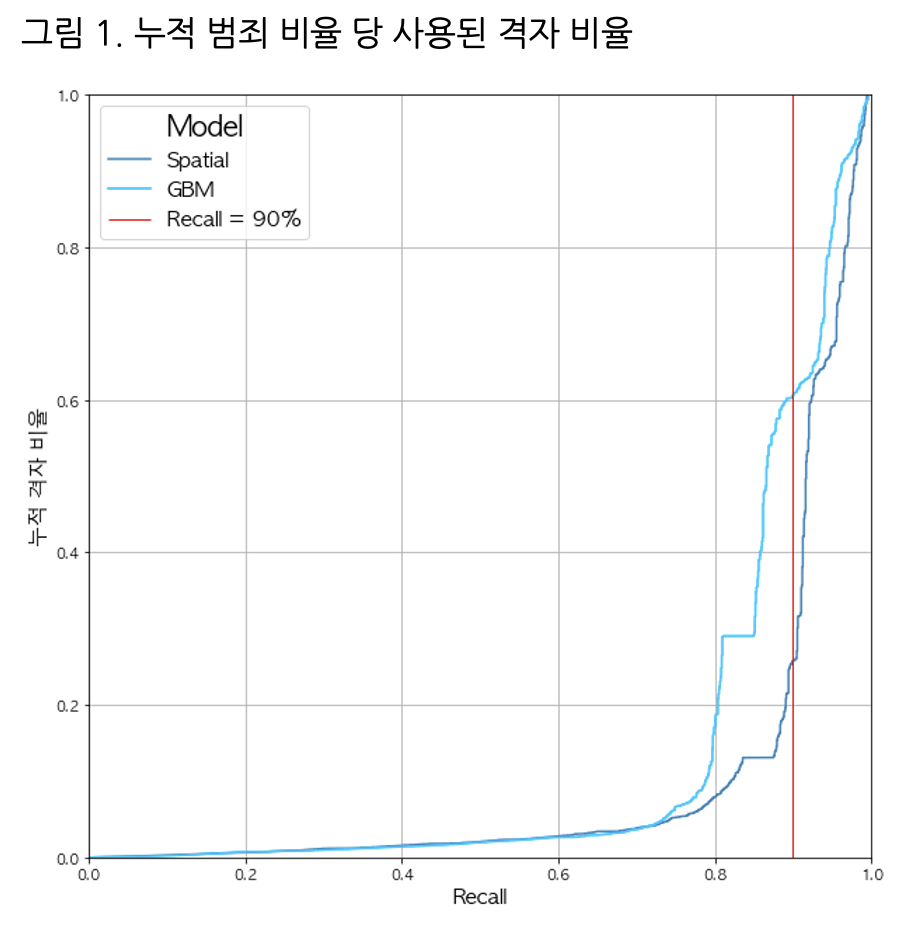
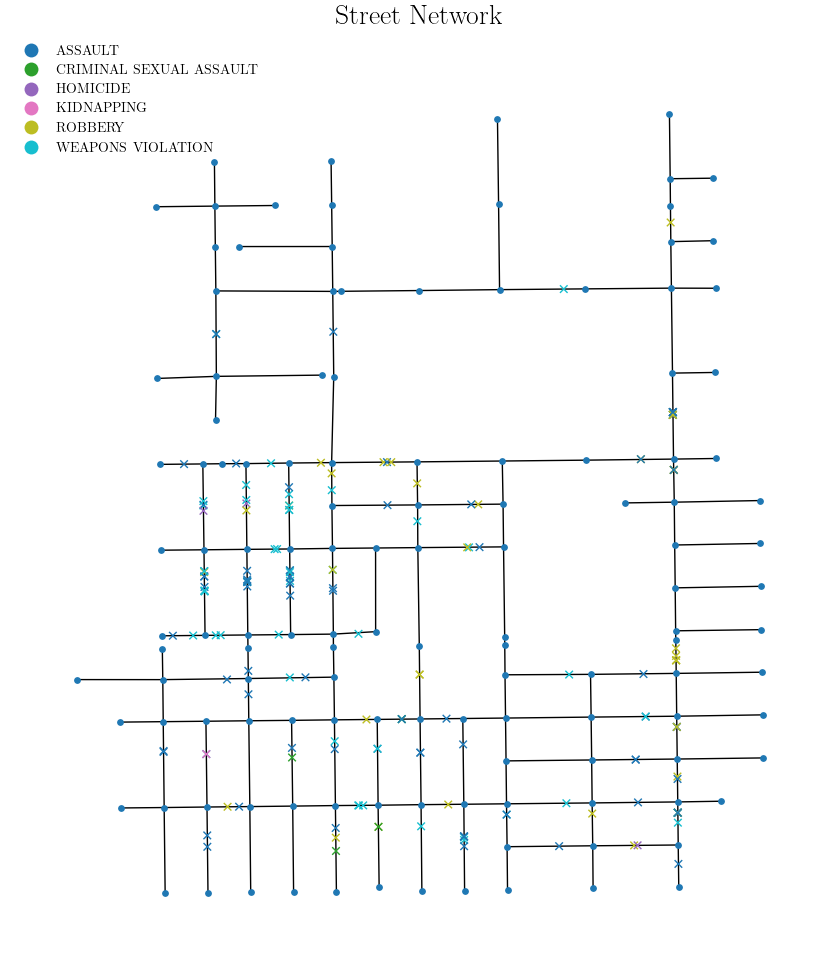
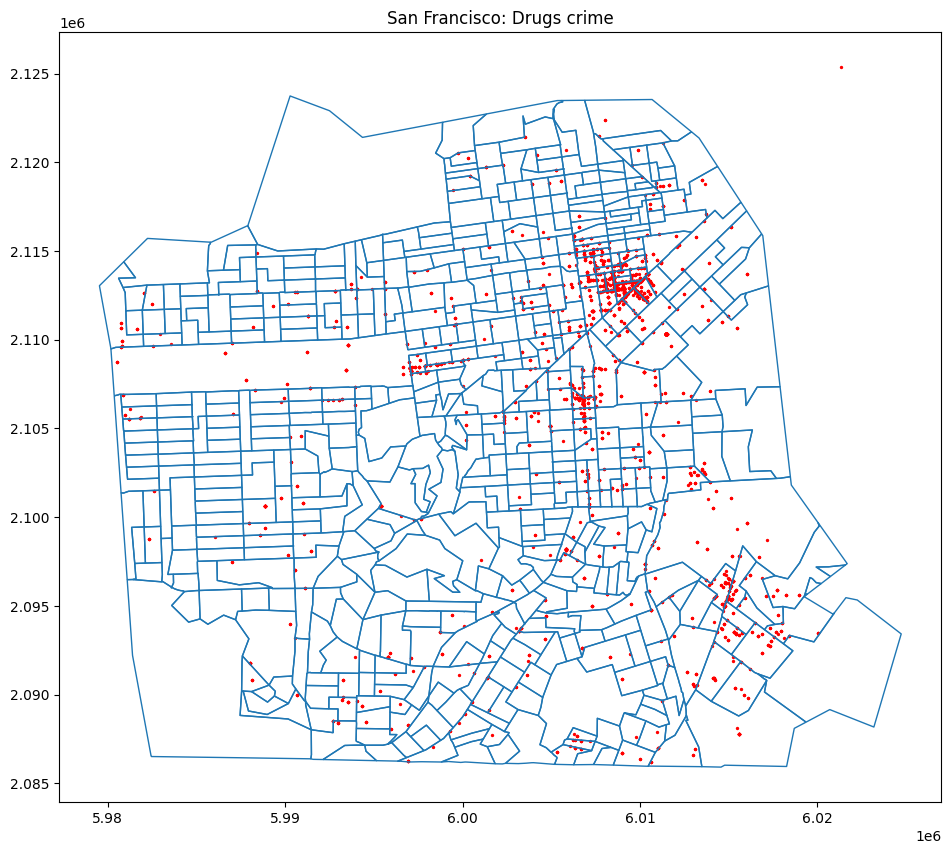
23년도 첫 공모전이자 대학원 입학 전 마지막 공모전으로 경찰대학 치안정책연구소 등에서 주관한 치안 데이터 기반의 공모전 지역치안데이터분석경진대회에 참가하게 되었다. 평소 도메인 지식이 치안이나 교통쪽에 한정되어 있기도 하고, 결국 안전한 사회를 위해 데이터를 활용하고 싶다는 내 평소 가치관과 부합하기 때문에 참가하지 않을 이유가 없었다. 우리 팀은 주어진 신고데이터를 활용해 보이스피싱...
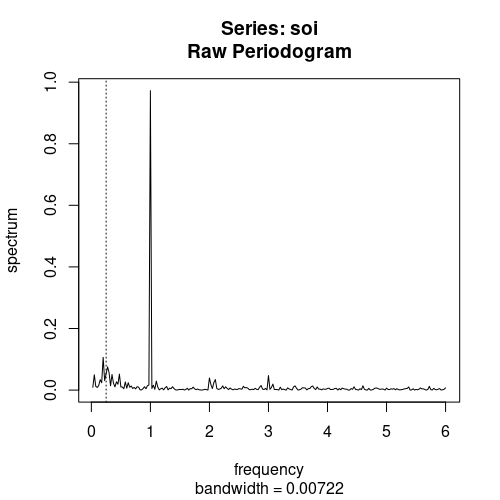
Spectral Representation Theorem 시계열 자료는 $\lbrace x{t}: t=1\ldots T\rbrace $ 형태로 discrete하게 주어진다. 반면, 파동함수(cosine, sine function)를 이용해 시계열 자료를 근사하는 방법이 있는데, 이러한 형태로 주어진 자료를 spectral 하다고 한다. Spectral Representation Theo...
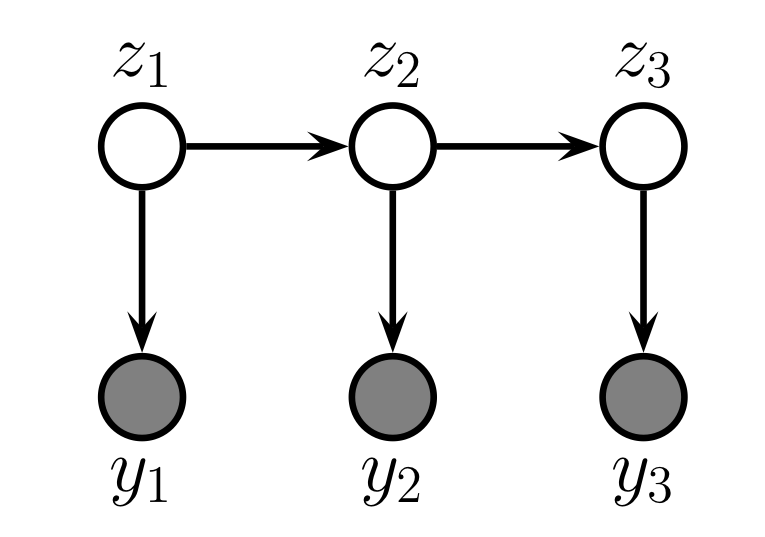
상태공간모형(State-Space Model, 이하 SSM)은 Markov chain을 기반으로 하는 시계열 모형의 일종이지만, 실제 관측가능한 observation 데이터와 hidden state data가 결합하여 만들어진다. Definition 상태공간모형은 다음과 같이 정의된다. 각 t 시점에서는 세 종류의 벡터가 주어지는데, 먼저 벡터 $$\mathbf{x}t \in \math...
Conditional Expectations Measure Theory를 기반으로 한 조건부 기댓값 및 조건부 확률을 정의해보도록 하자. 일반적으로 measure를 다루지 않는 통계학에서는 조건부 확률을 먼저 정의하고, 이후에 조건부 기댓값을 조건부 확률을 이용해 정의하는데 measure를 이용하면 좀 더 엄밀한 정의가 가능하다. 또한, 측도를 기반으로 한 새로운 조건부 기댓값의 정의와...
MA Model & Trend Estimation Moving Average Model 시계열 모형에는 다양한 구조가 존재하는데, 여기서는 가장 기본적인 MA model(이동평균 모형)에 대해 다루어보도록 하자. MA는 Moving Average(이동평균)의 약자인데, 각 시점의 확률변수는 이전 시점들의 White Noise들로 구성된다. MA(q) 모델은 다음과 같이 주어진다. $$...
Stationarity 우리말로 정상성이라고 정의하는 Stationarity는 시계열 분석을 수행하기 위해 가정해야 하는 가장 중요한 도구이다. 회귀분석에 비유하자면, 회귀모형의 오차항(흔히 $\epsilon$으로 나타나는)이 정규성을 가진다고 가정하는 것과 비슷하다. 가장 단순한 (단변량) 시계열은 다음과 같이 시간 $t$에 대해 변화하는 확률변수의 sequence로 정의된다. $$...
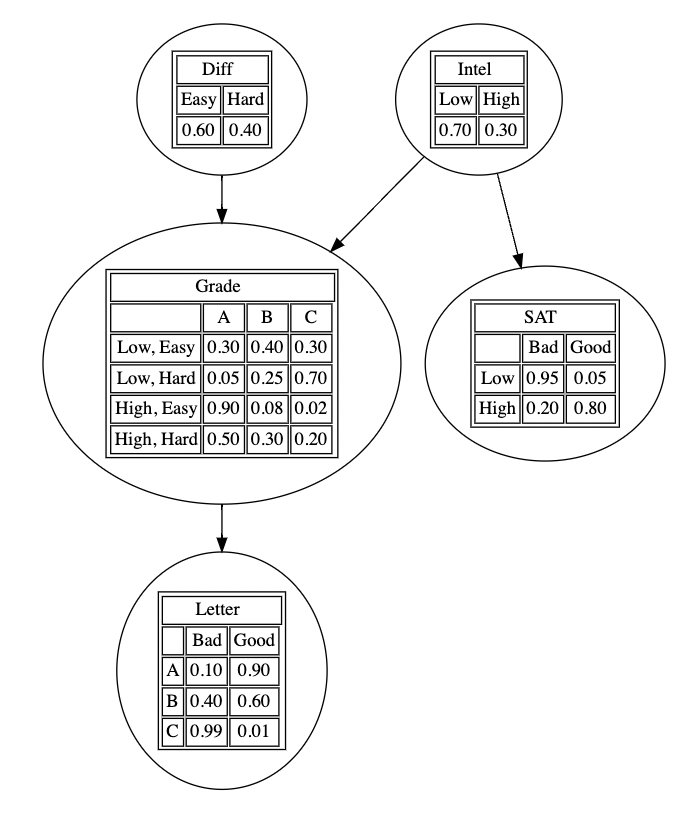
Probabilistic Graphical Models 이전에 graph의 markov property/)을 살펴보며 markov property 하에서(parent 노드가 주어질 때 다른 노드들과의 조건부 독립성) graphical model을 다음과 같은 markov chain 형태로 나타낼 수 있음을 알았다. $$ p(\mathbf x{1:V}) = \prod{i=1}^Vp{\th...
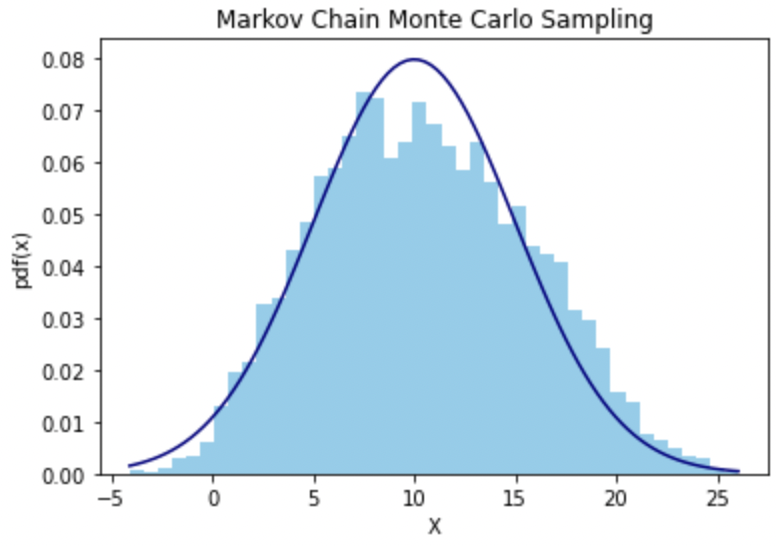
Markov Chain Monte Carlo MCMC라고도 하는 Markov Chain Monte Carlo 기법은 확률분포에서 샘플을 추출하는 여러 종류의 알고리즘을 일컫는다. 다양한 머신러닝 이론들이 등장하며, 기존 통계학에서 다룰 수 없을 정도의 수만-수백만 개의 변수 및 파라미터를 사용하는 모델들 역시 등장했고, 특히 신경망과 같은 모델들은 너무나도 널리 사용되고 있다. 하지만...
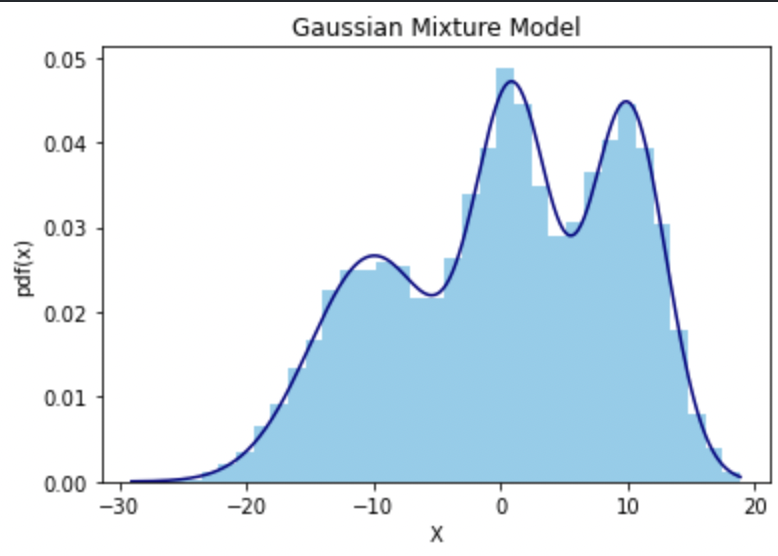
Mixture Model & EM Algorithm Mixture Model Mixture Model은 Latent Variable Model(LVM)의 일종이다. 여기서 LVM은 관측된 변수들간의 상관관계를 숨겨진 공통원인(common cause)에서 비롯된 것으로 가정한 모델이다. LVM을 이용하면, 차원축소(ex. PCA)를 수행하는 것과 같이 하나의 공통변수에 여러 기존 변수들을...
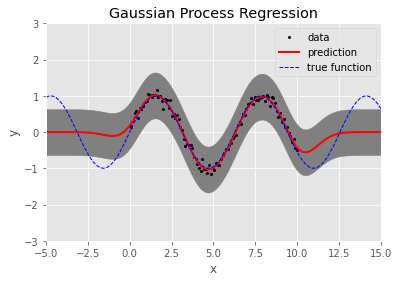
Gaussian Process (1) Definition Gaussian Process(줄여서 GP라고도 한다)는 비모수방법의 일종으로, 사전분포를 표현하여 베이즈 정리를 바탕으로 사후확률을 추론하는 기법으로 사용된다. 길이 $N$의 가우시안 랜덤 벡터(Gaussian Random Vector)란 $$ \mathbf{f} = [f1,\ldots,fN] $$ 의 형태로 주어지며, 평균벡터...
서울 IOT 공공도시데이터 활용 해커톤 후기 일정 통계학과 코딩 공부를 시작하고 나서 실력을 검증받고, 또 경험을 쌓고자 꾸준히 참여할 공모전이나 프로젝트를 알아보던 중에 위 대회를 알게 되었다. 평소 스마트시티와 관련된 비전을 갖고있던 나에게는 도시데이터 활용이라는 점이 매우 매력적으로 다가왔고, 현재 직업의 특성을 살려보고자 교통안전을 필두로 한 주제로 대학 동기들과 함께 참여해보기...
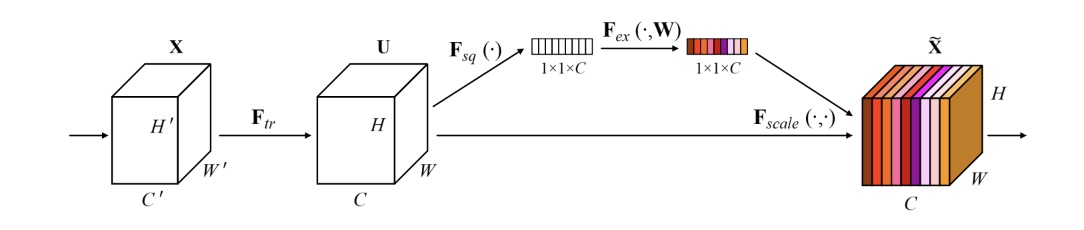
Multivariate LSTM-FCN 이번 글에서는 저번에 살펴본 단변량 시계열 분류모형인 LSTM-FCN을 다변량으로 확장한 Multivariate LSTM-FCN을 살펴보도록 할 것이다. 모형의 근본적인 구조는 LSTM-FCN과 동일하지만 convolutional layer들에서 Squeeze and Excite 라는 새로운 블록이 추가된다. Squeeze and Excite 블록...
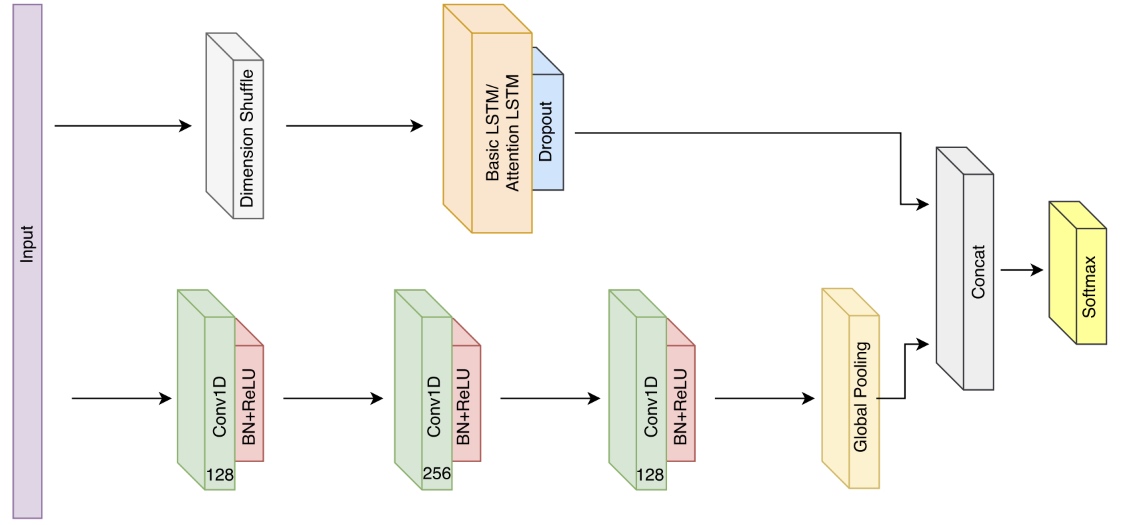
LSTM Fully Convolutional Networks for Time Series Classification 최근 공모전 준비로(추후에 마무리 후 포스팅 예정) Time Series Classification 기법들에 대해 알아보면서, 딥러닝(RNN, CNN) 기반의 방법중 하나인 LSTM-FCN을 알게 되었다. RNN의 개념부터 LSTM-FCN으로 시계열을 처리하는 네트워크까지...
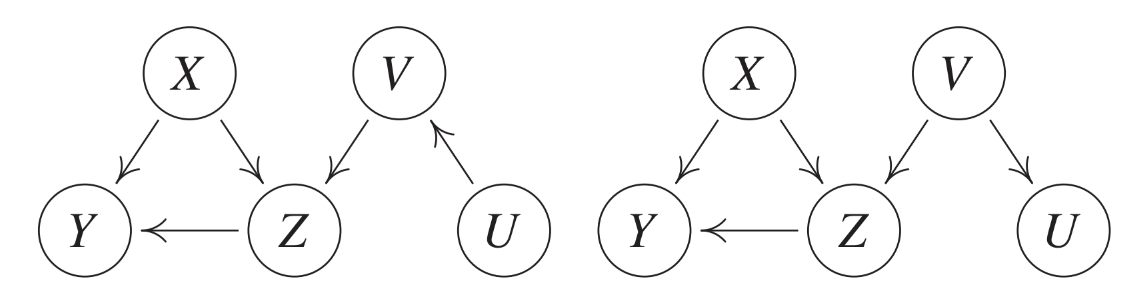
Multivariate Causal Model (2) 이번 글에서는 저번에 이어 노드가 여러개인 multivariate causal model에 대해 계속 다루어보도록 할텐데, 그래피컬 모델과 관련된 중요한 개념중 하나인 Markov property, equivalence, blanket 등 개념에 대해 다루어보도록 할 것이다. Markov Property Markov property는...
Multivariate Causal Models 이전까지는 변수가 2개인 SCM, 즉 원인-결과의 SCM을 살펴보았었다. 이제부터는 변수가 여러개인(multivariate) causal model들에 대해 살펴보도록 하자. 우선, cause-effect 모델도 포함되지만 다변량 causal model은 일반적으로 그래프(graph)의 형태로 표현된다. Graph의 정의 그래프란, 확률변...
Learning Cause-Effect Models (2) 이번 게시글에서는 저번/)에 이어 다른 Cause-Effect 모델들과 이들의 식별가능성에 대해 계속 살펴보도록 하자. Post-nonlinear Models Post-nonlinear model은 이전에 살펴본 Nonlinear ANM의 일반화된 모델이다. 결합분포 $P{X,Y}$가 X에서 Y로의 post-nonlinear m...
따릉이 데이터 분석하기 (7) - AutoML 이번 게시글을 끝으로 데이콘의 따릉이 데이터 분석 관련 포스팅을 마치고자 한다. 마지막 내용은 AutoML을 다룰 것인데, AutoML이란 이전에 살펴본 여러 종류의 모델들을 선택하고, hyperparameter들을 최적화하는 일련의 모든 과정들을 자동화하는 방법을 총칭하는 단어이다. 사실 최근 비즈니스 실무 영역에서는 AutoML이 대세로...
Bayesian Data Analysis(2) - Noninformative prior distribution 이전 게시글에서는 single parameter model에서 이루어지는 bayesian inference의 대략적인 과정과, 그 과정에서 관찰되는 conjugate prior-posterior distribution에 대해 살펴보았다. 이번에는 prior distributio...
Learning Cause-Effect Models 통계적 학습이론(Statistical Learning)의 관점에서 살펴보면, 가장 간단한 케이스인 cause-effect model을 학습하는 것 조차 어려움이 존재한다. Statistical Learning은 소위 주어진 관측값 $(X,Y){i=1\ldots,N}$ 들로부터(observation) $X,Y$의 joint distrib...
Frequentist, 즉 빈도주의적 관점에서는 확률은 반복되는 시행과정에서 해당 사건의 발생 빈도를 의미한다. 즉, 어떤 분류 모델의 성능이 95%라면, 이는 임의의 예제 100개 중 95개의 비율로 정확성을 갖는다는 것을 의미한다. 반면, 베이지안 관점에서는 해당 분류 모델이 정확하다고 '95%' 확신할 수 있다고 해석하게 된다. 즉, 보편적인 확률의 정의는 빈도주의적 관점에 해당하...
Causal Inference Causal Inference, 즉 인과관계추론은 통계학의 한 분야로 사회과학 등 다양한 분야에 응용될 수 있는 영역이다. 2021년 노벨경제학상이 인과관계추론 분야에서 수상되며 전통적인 방법론이었으면서도, 최근 통계학의 중요한 분야로 떠오르는 추세이다. 기존의 선형모형론부터 최근의 데이터사이언스 기법들은 대개 input data와 target variab...
Cause-Effect Model Structural Causal Model 줄여서 SCM이라고 하는 Structural Causal Model은 인과관계모델을 구조화한 표현이다. 여기서는 우선 원인(C)과 결과(E) 두 변수로 구성된 Cause-Effect 모델만을 다루고, 이에 대한 SCM을 다음과 같이 정의한다. Def. $C\to E$에 대한 SCM $\mathfrak C$는 두...
Empirical Risk 사용의 근거? 이번 게시글은 Statistical Learning, 즉 통계적 학습이론의 근간이 되는 추정 이론 중 Empirical risk 사용의 근거와 관련 이론에 대해 살펴보도록 하자. 내용은 대표적인 머신러닝 알고리즘인 Support Vector Machine의 공동 창시자 Vladimir N. Vapnik의 ’An Overview of Statist...
Incomplete mathematical mosaic of DL 이번 글에서는 논문 Fit without fear: remarkable mathematical phenomena of deep learning through the prism of interpolation(M.Belkin et al.)을 리뷰해보도록 하겠다. 이 논문은 최근학술적 및 산업적으로 괄목할만한 성과를 내고 있는...
데이터 분석 = 모델 성능 개선 ? Background 요새는 데이터사이언스에 대한 기틀을 잡고자 꾸준히 머신러닝 관련 공부를 하며, 이론 공부와 더불어 (가공되었지만 그래도 실생활에서 비롯된)몇몇 데이터셋을 대상으로 실제 데이터분석을 간간히 진행하고 있다. 하지만 분석도 해보고, 이와 관련되어 포스팅도 진행하며(ex. 따릉이 프로젝트) 느낀 것은 왜 이러한 데이터셋에 대해 해당 모델을...
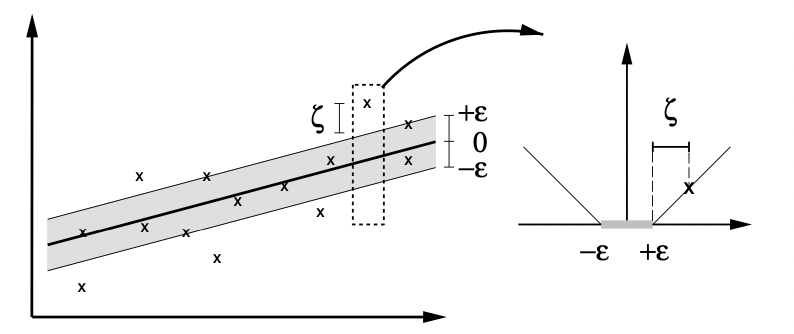
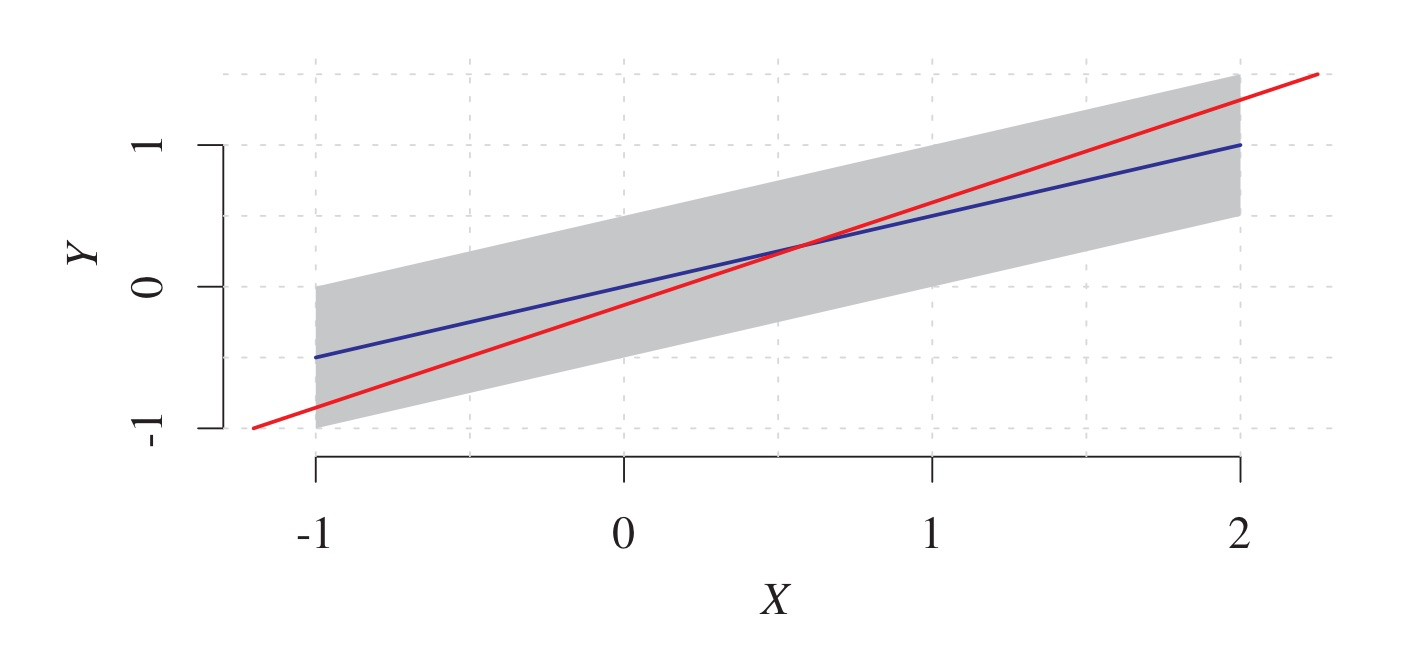
Support Vector Regression 이전 게시글에서 SVM의 작동 원리와 SVR, 즉 support vector regression이 SVM의 원리를 차용하여 생성되는 모델이라는 점에 대해 살펴보았다. 이번에는 paper "A Tutorial on Support Vector Regression(2003)"을 바탕으로 SVM이 회귀분석에 사용되는 경우만 특히 집중해서 살펴보고,...
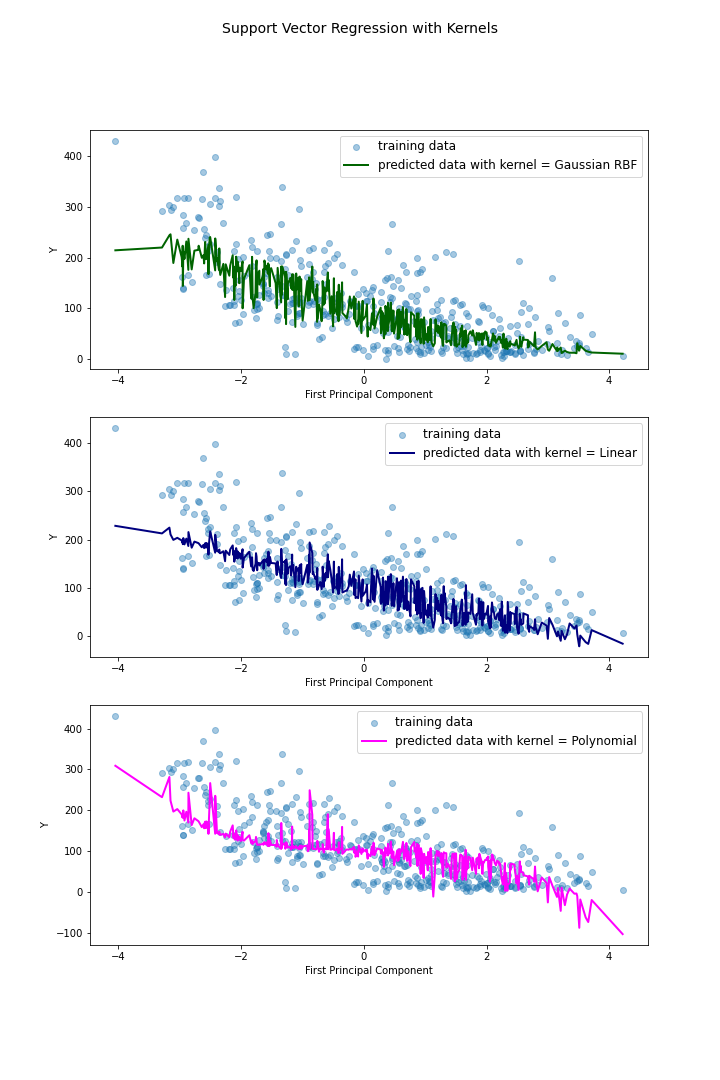
따릉이 데이터 분석하기 (6) Support Vector Machine 이번 글에서는 대표적인 머신러닝 모델인 SVM(Support Vector Machine)을 이용해 따릉이 이용 데이터의 분석을 진행해보도록 하자. 본래 SVM은 classification의 목적을 위해 고안된 기법으로, 데이터들의 레이블을 분류하는 기준이 되는 초평면을 찾아내는 과정이다. 그런데 이 과정의 아이디어를...
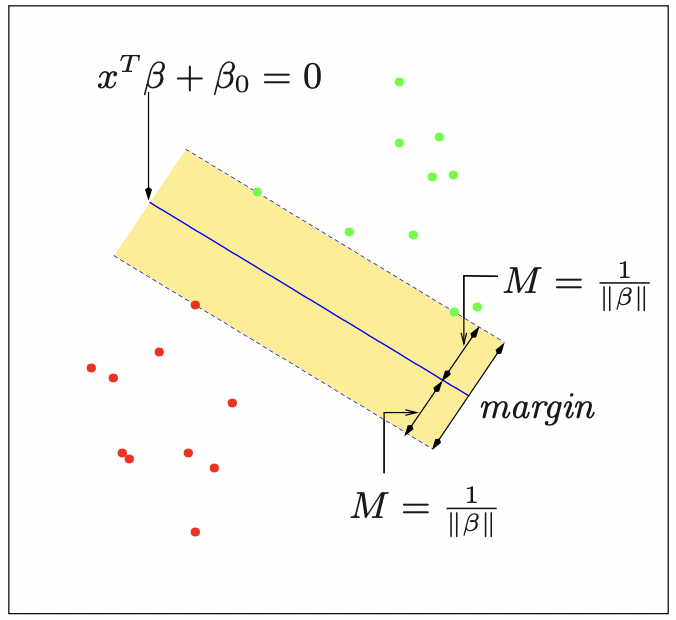
Support Vector Machine 이전에 Linear Classification에서 Fischer's LDA에 대해 다룬 적 있었다. 이는 특성공간에서 데이터들을 분류하기 위한 선형 경계를 만드는 것인데, support vector classifier/machine은 이와 유사하나 비선형인 결정경계를 만들 수 있다는 점에서 좀 더 일반화된 개념으로 생각하면 된다. Support...

Gradient Boosting Machine 이번 글에서는 Boosting 알고리즘과 관련하여, 특히 함수추정과 예측 문제에서 뛰어난 성능을 보이는 Gradient Boosting Machine에 대해 살펴보고자 한다. 여기서는 GBM을 제안한 Jerome H. Friedman의 Greedy Function Approximation: A Gradient Boosting Machine...
Boosting Tree 이전에 Regression Tree와 Classification Tree(CART) 모형에 대해 살펴보았는데, Tree에 대해서도 boosting algorithm을 적용할 수 있다. Tree 모델은 기본적으로 partition된 region $Rm$들에 대한 예측값 $\gammam$을 부여하는 것인데, 이를 이용해 $J$개의 region을 분리하는 Tree를...
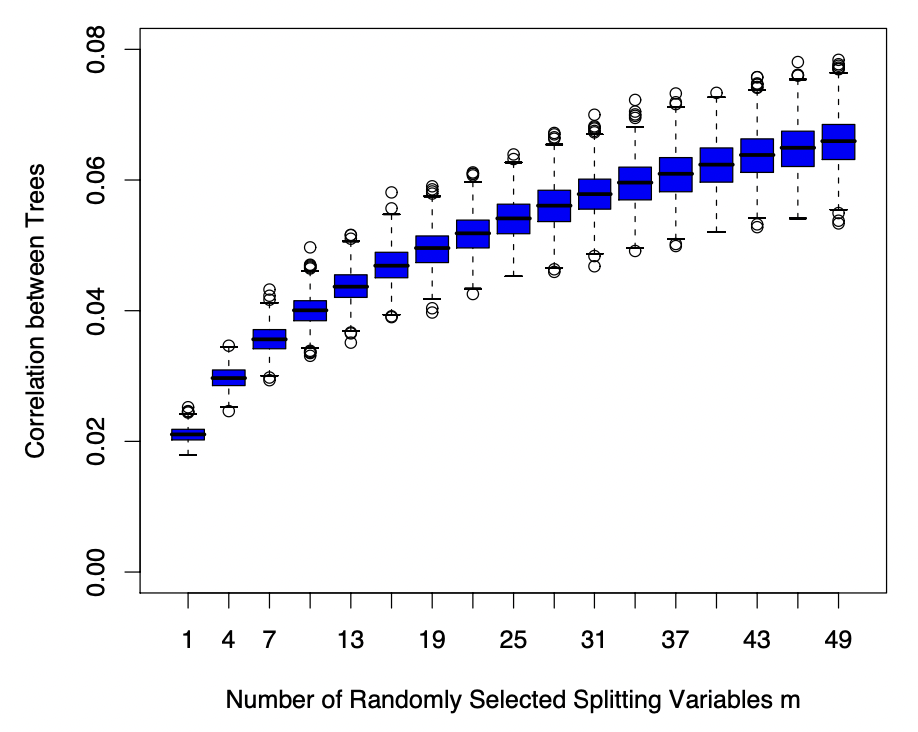
Random Forest Random Forest는 Bagging 배깅 방식을 이용한 Tree algorithm의 일종이다. 즉, 서로 상관관계가 없는 (de-correlated, randomized) tree들을 매우 많이 생성하여, 이들의 평균값을 바탕으로 분류 혹은 회귀를 진행하는 알고리즘이다. Tree model이 Bagging algorithm을 실행하는데 가장 최적인 이유는...
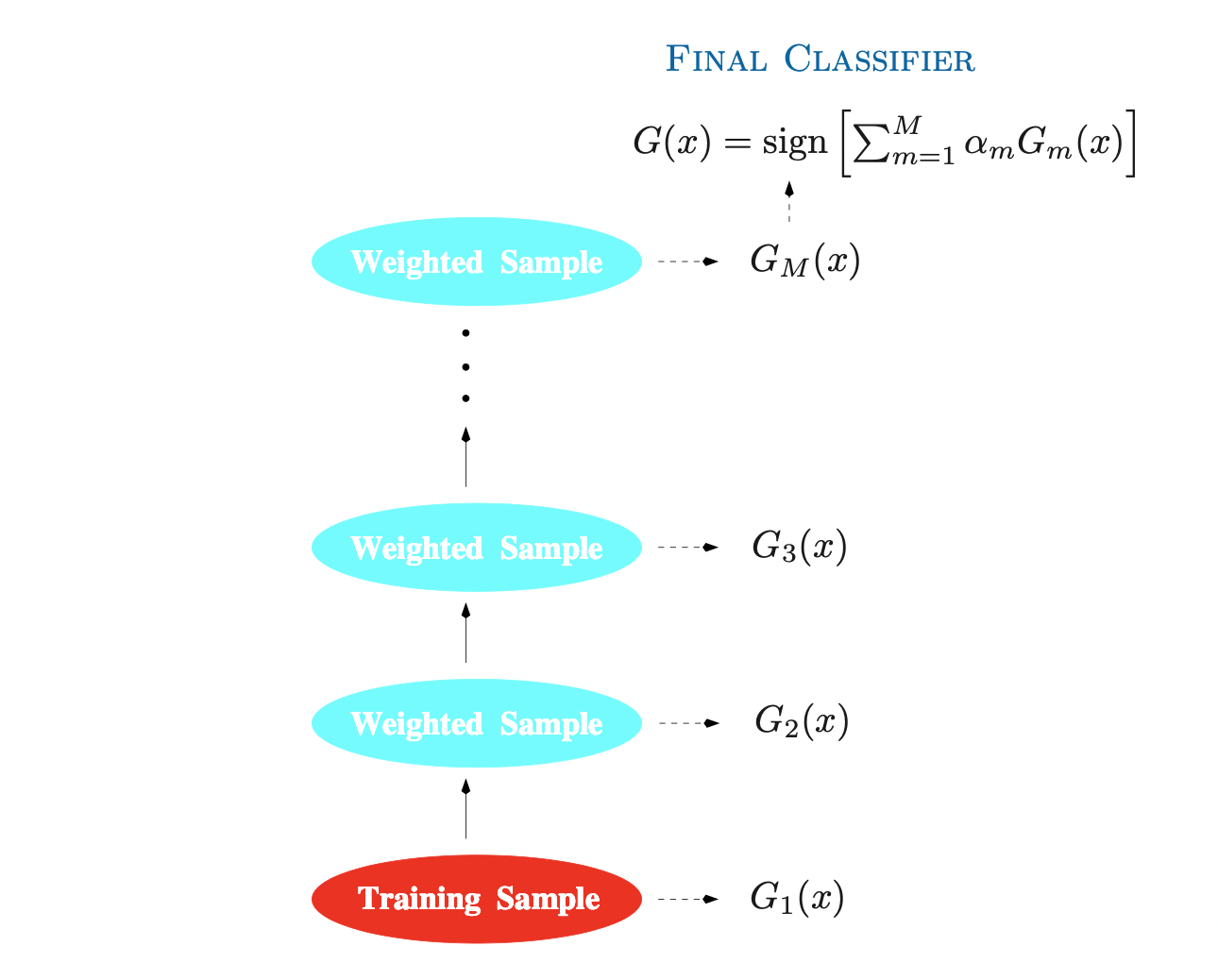
Boosting Methods Boosting 부스팅 은 21세기부터 statistical learning의 주요한 모델로 사용되고 있는 방법이다. 초기에는 분류 모델에 주로 이용되었으나, 회귀 문제로도 확장되어 사용된다. Boosting 방법들의 핵심 아이디어는 기본적인 Ensemble 기법, 즉 overfitting 가능성이 작은 weak classifier 여러개를 결합시킨 것을...
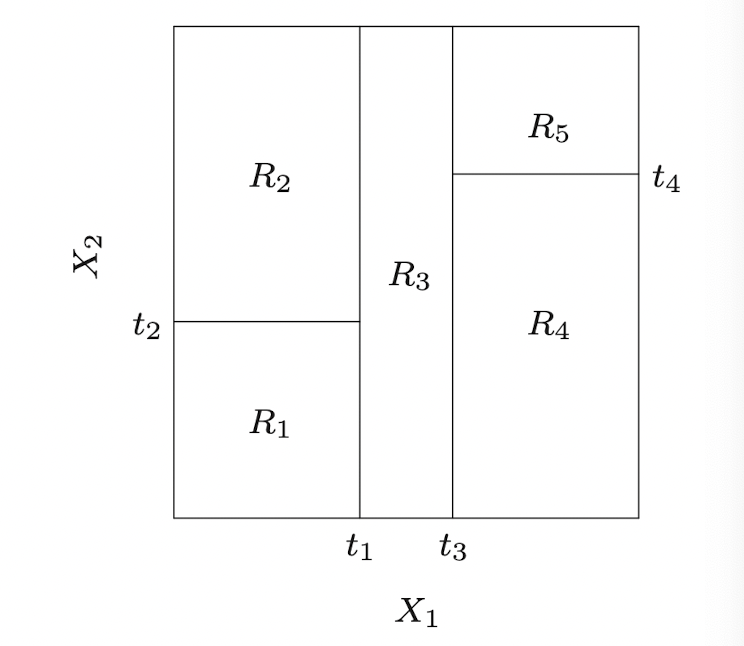
Tree-Based Methods Tree를 이용한 알고리즘은 기본적으로 Feature space 특성공간 을 직사각형들의 집합으로 분할 partition 하고, 각 집합들에 대해 매우 간단한 모델(e.g. constant)을 적용하는 원리이다. Tree를 기반으로 한 알고리즘에는 CART, ID3, C4.5 등이 있으며, 수많은 Tree를 적용시킨 Ensemble method으로 대표...

따릉이 데이터 분석하기 (5) Tree 이번에는 Tree 관련 모델들로 주어진 데이터셋을 훈련시켜보고 이를 검증해보도록 하자. 저번 Transformation 데이터 분석 과정과 마찬가지로 scikit-learn의 Pipeline을 이용해 데이터 전처리부터 모델링까지의 파이프라인을 구성해보도록 하겠다. Data Load와 Preprocessing 관련 코드 및 자세한 설명은 시리즈의 이...
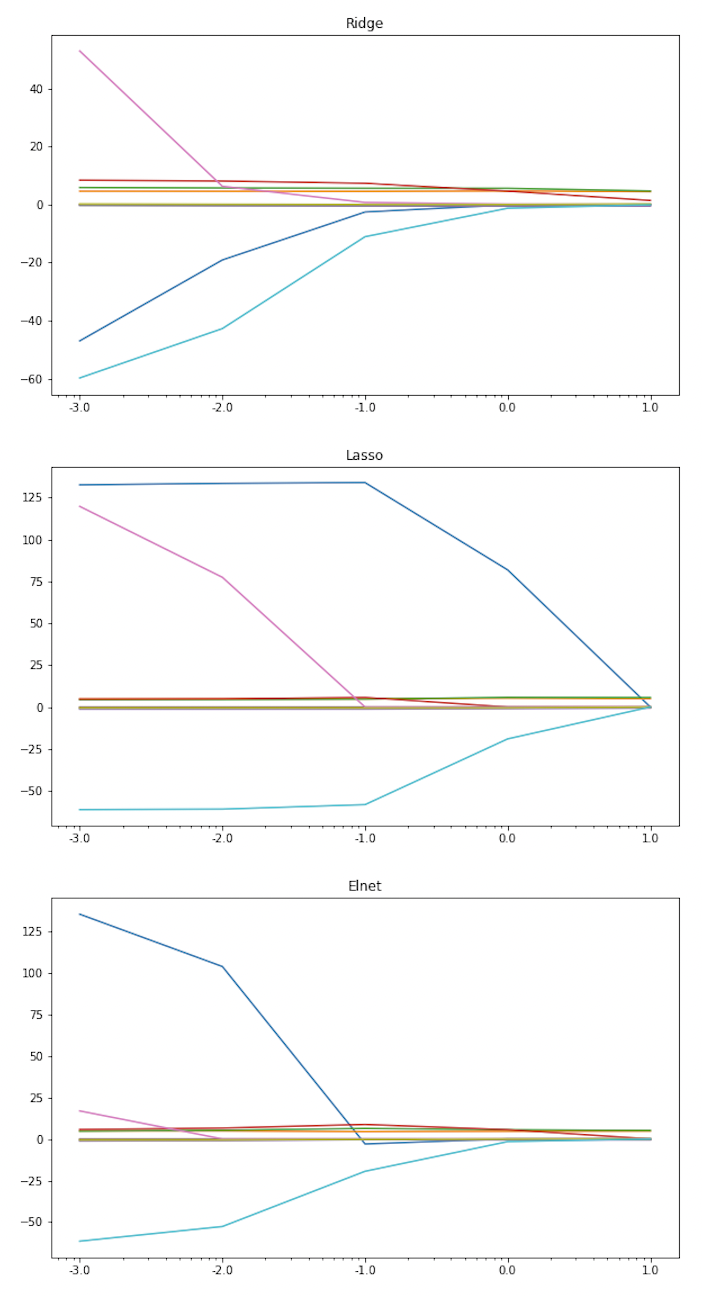
따릉이 데이터 분석하기 (3) Modified Linear Methods 이번 글에서는 Linear regression을 계속 다룰 것인데, 그중에서도 regularization method나 spline regression과 같은 변형된 방법들을 다루어보고자 한다(역시 Regression 문제가 Linear Model로 다루기 최적인듯 하다🤣). 우선 Lasso, Ridge 등을 포...
따릉이 데이터 분석하기 (4) Transformation 이번에는 PCA를 비롯해 예측변수의 데이터셋을 변환시키는 transformation 여러 가지 방법들에 대해 다루어보도록 하겠다. 대표적으로 PCA는 기본적인 회귀문제에 응용되어 PCR로 사용되거나, 고차원 문제의 차원 축소 기법으로 필수적인 역할을 한다. 여기서는 우선 PCA를 진행하고, 이 결과를 바탕으로 PCR을 진행하여 이...
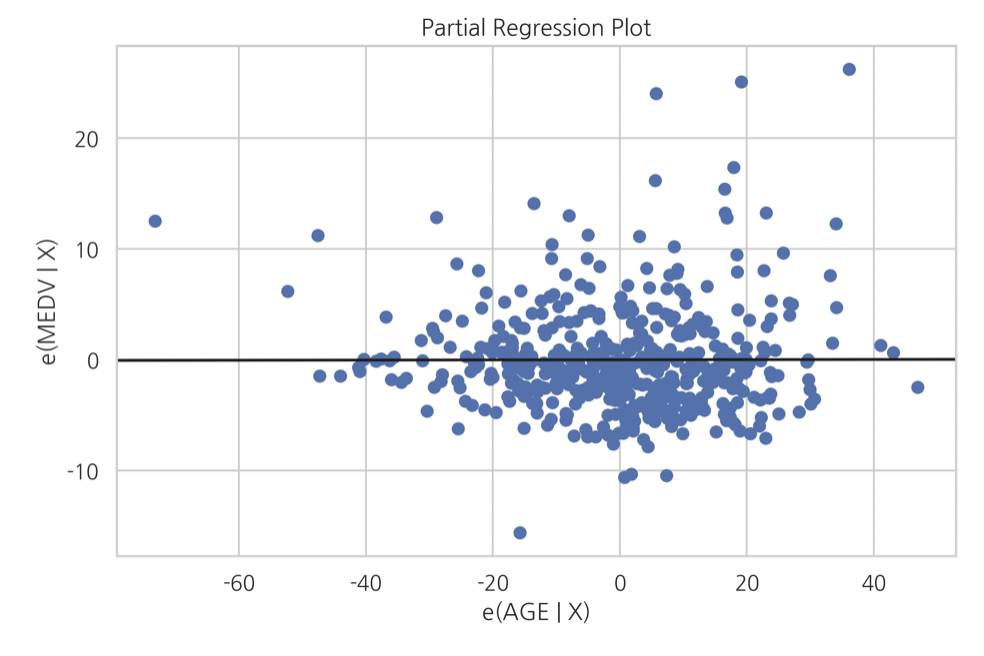
Partial Regression Linear Regression model에서 예측변수가 여러개일 때, 즉 multiple linear regression인 경우 각각의 변수 고유의 영향력을 파악하는 방법으로 partial regression이 있다(Partial Least Square algorithm과 명백히 다르다!). 이에 대해 간단히 다루어보도록 하자. 우선 다음과 같은 회귀...
따릉이 데이터 분석하기 (2) Linear Regression 먼저, 앞서 살펴본 따릉이 데이터셋을 이용해 가장 간단한 Linear Regression Model을 구현해보도록 하자. Python에는 statsmodels라는 패키지가 있는데, 이는 R에서 사용하는 형태로 통계분석을 가능하게 해주는 패키지이다(공식 문서 참고). 이를 이용해 선형모형을 만들고, 이를 개선시켜나가는 방법을...
따릉이 데이터 분석하기 (1) EDA 이번 시리즈는 공공데이터인 서울시 공유자전거 따릉이의 데이터를 이용한 small project를 진행해보고자 한다. 데이터를 비롯한 프로젝트의 내용은 데이콘의 내용을 바탕으로 진행했으며, 원래 주제는 데이터를 바탕으로 한 AI 모델을 개발하는 것이다. 하지만 여기서는 AI모델을 개발하기 전에, 회귀문제로 얼마나 높은 성능까지 끌어올릴 수 있는지를 먼...
Regularization on Neural Network Neural Network는 기본적인 feedforward network조차도 학습해야 할 파라미터 개수가 많다. MNIST 데이터셋을 사용하는 네트워크에서, input layer의 값을 받는 첫번째 fully-connected hidden layer의 경우 노드가 30개라면 $784\times30 = 23520$ 개의 para...
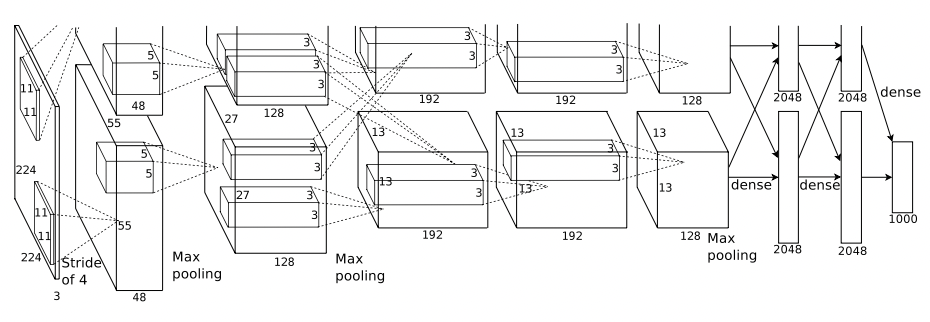
AlexNet 이번 글에서는 “ImageNet Classification with Deep Convolutional Neural Networks”(2012) paper를 리뷰해보고자 한다. 이 논문은 2012년 ImageNet 대회에서 우승한 합성곱 신경망을 다루고 있다. 네트워크 이름은 대표저자 Alex Krizhevsky의 이름을 따 AlexNet이라고 부른다. 이전에 살펴본 LeN...
Bootstrap Methods Bootstrap 방법은 정확도(accuracy)를 측정하기 위해 사용되는 일반적인 방법이다. Cross-validation과 마찬가지로 bootstrap은 (conditional) test error $\text{Err}\mathcal T$ 를 추정하기 위해 사용되지만, 일반적으로 기대예측오차 $\text {Err}$ 만을 잘 추정해낸다. 정의 크기가...
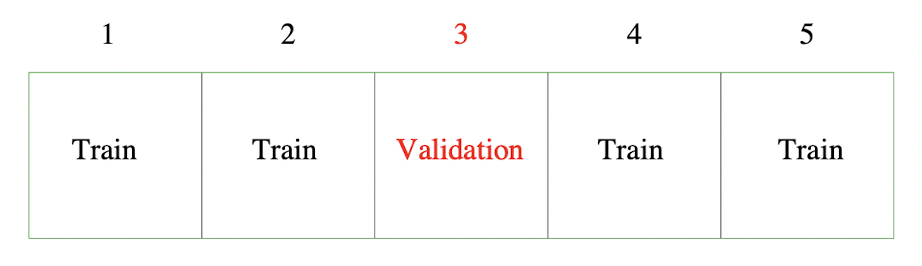
Cross-Validation Cross-validation 교차검증 은 prediction error을 추정하는 과정에서 가장 널리 사용되는 방법 중 하나이다. 딥러닝을 포함한 대부분의 머신러닝 영역에서 기본적으로 교차검증을 사용하며, 또한 대부분의 패키지 역시 이와 관련된 메서드를 포함한다. 이번 글에서는 교차검증의 이론적인 내용을 살펴보도록 하자. K-Fold Cross Valid...
Convolutional Neural Network Convolutional Neural Network(이하 CNN)은 합성곱 신경망이라고 불리는데, 딥러닝의 여러 활용 분야 중 특히 computer vision 영역에서 주로 사용된다. Gradient-Based learning applied to Document Recognition 이라는 1998년 논문(링크)에서 손글씨 이미지를...
Entropy and its related loss Entropy 엔트로피는 확률론에 기반한 정보이론에서 매우 중요하게 쓰이는 개념이다. 확률변수 random variable $\xi$ 가(random element 참고) density $f\geq 0$ 을 가진다고 하자 (✅ density function은 Radon-Nikodym 참조). 이때 $\xi$의 엔트로피는 다음과 같이 정...
Simple Neural Network with Tensorflow Tensorflow를 이용해, 이전까지 알아본 신경망의 기본적인 내용을 바탕으로 간단한 신경망을 구현해보자. 우선, 필자는 M1 Macbook Air에 python 3.9버전을 올려 apple tensorflow 2.8 버전 환경을 사용하고 있음을 알린다. M1 환경에서 tensorflow를 설치하는 방법은 Apple...
Backpropagation 이전에 최적화와 관련된 내용에서 살펴보았듯이, 어떤 머신러닝 모델을 최적화하는 기본적인 아이디어는 입력에 따른 출력의 변화, 즉 그래디언트를 계산하는 것에 있다. 그러나 딥러닝에서는 레이어와 노드의 수가 많아질수록 연결관계가 기하급수적으로 복잡해지고 이에 따라 하나의 가중치벡터(혹은 행렬)에 대한 그래디언트를 explicitly하게 구하기 어렵다. 따라서 이...
Neural Networks 인공신경망 Artificial Neural Network 이론은 2010년대부터 급속도로 성장한 머신러닝 분야 중 하나이다. 특히 이와 관련된 분야를 딥러닝이라고 하며, CPU 및 GPU의 성능이 비약적으로 향상되며 다른 머신러닝 기법들에 비해 그 성능이 급속도로 증가하고 있다. 이번 글에서는 인공신경망의 기초적인 내용에 대해 다루도록 하겠다. Linear...

Optimization 최적화 optimization 과 관련된 내용은 통계학 및 머신러닝 뿐 아니라 다른 자연과학, 사회과학 분야들에서 널리 사용된다. 머신러닝 영역에서 최적화 문제는 다음 식 한줄로 표현할 수 있다. $$ w^{}=\mathop{\arg\min}\limitsw L(w) $$ 이때 argmin, 즉 최대화가 아닌 최소화 표현이 사용되는 이유는 머신러닝에서 사용하는 최적...
How to make an assessment of a model? 우리가 어떤 머신러닝 모델을 만들었을 때, 모델의 성능은 어떻게 측정할 수 있을까🤔? 간단히 생각해보면, 서로 다른 데이터셋들에 대해 모델의 정확도를 측정하고, 이들을 종합해서 지표화하면 될 것이다(이때 데이터셋들은 확률적으로 독립이어야 할 것이다). 모델의 성능을 측정하는 것은 매우 중요한 문제이다. 실제로 모델을...
Distributions 이전 게시글에서는 random elements에 대해 다루었으며, 확률분포 distribution 가 어떻게 새로운 측도로 정의되는지 살펴보았다. 이번에는 random elements의 분포와 분포 함수 및 수리통계학에서 다룬 기댓값, 적률 등을 살펴보고자 한다. Finite-dimensional distribution $X$를 어떤 finite index se...
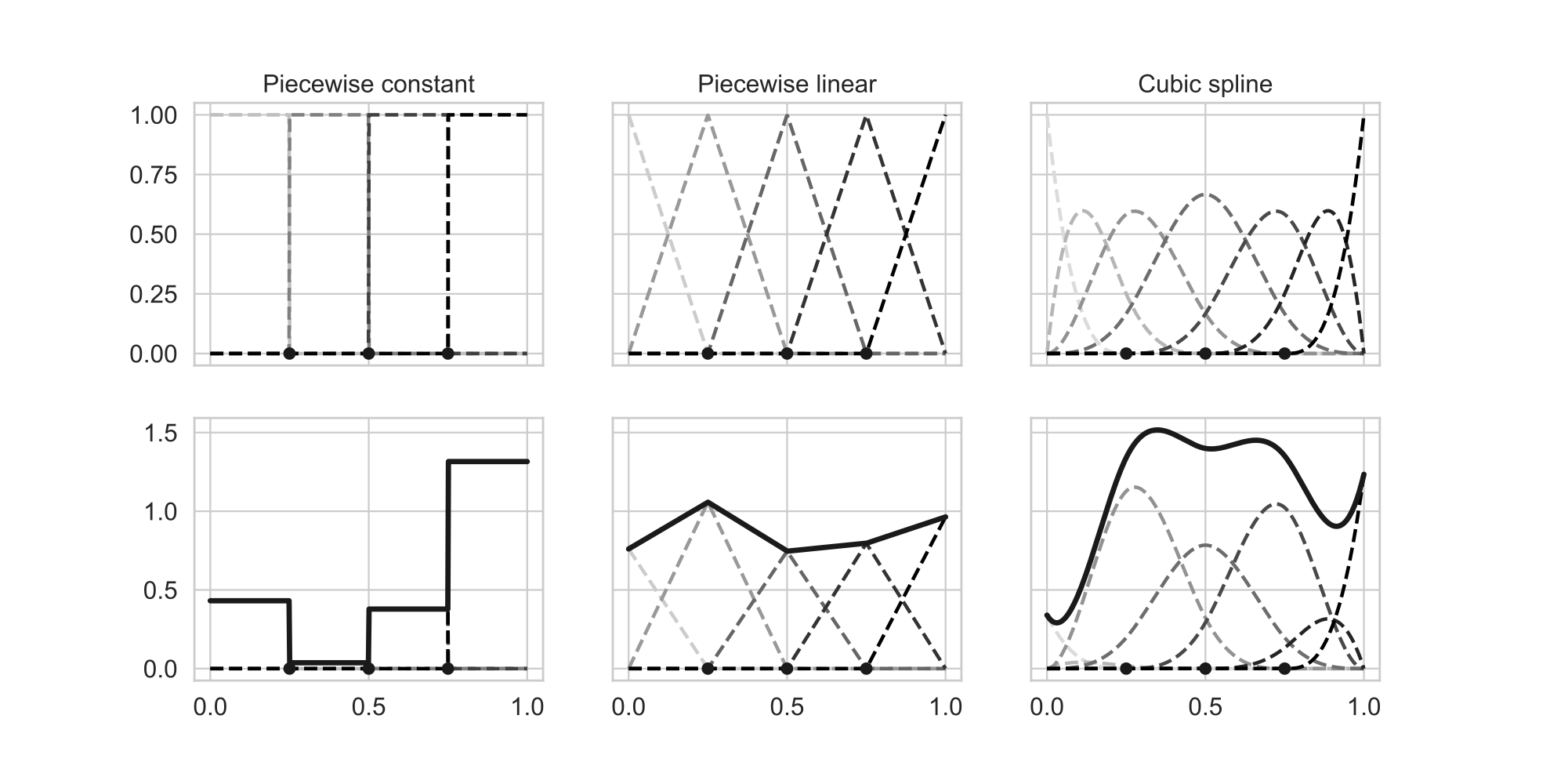
Splines Spline 스플라인 은 데이터셋을 부분적으로 나누어 각 부분에 대해 다항식을 적합하는 방법입니다. 추정하고자 하는 회귀모형이 비선형적인 형태를 가지고 있을 때, 이를 선형모형으로 근사하는 방법 중 하나입니다. 이는 기저확장 basis expansion 의 한 형태로 볼 수 있습니다. 이번 글에서는 B-spline을 중심으로 spline의 구성요소와 이를 이용한 회귀모형을...
Random Elements 저번에 다룬 확률측도 공간(Probability Space, 이하 확률공간) $(\Omega,\mathcal{F},P)$ 를 바탕으로 확률론의 대상이 되는 random elements 대한 내용을 다루도록 할 것이다. (확률측도의 $\sigma$-algebra에 대해서도 인식의 편의(🤔)를 위해 $\mathcal{M}$ 대신 $\mathcal{F}$을 사용...
Absolute Continuity 정의 measurable space $(X,\mathcal{X})$ 에서 두 측도 $\mu,\nu$ 가 정의되었다고 하자. 이때 임의의 $\mu$-null set이 $\nu$-null set이라면, 즉 $$ \mu(A)=0\Rightarrow\nu(A)=0 $$ 이라면 $\nu$를 $\mu$에 대해 absolutely continuous 하다고 정의한...
Product Integral 이번 글에서는 르벡적분에 대한 다중적분을 정의해보도록 할 것이다. 다중적분을 하기 위해서는 곱함수가 정의되는 product space와, product space에서 측도로 사용될 수 있는 product meausre이 필요할 것이다. Product Space 두 위상공간 $X,Y$에 대한 cartesian product $X\times Y$ 는 다음과 같...
Lebesgue Integration with General Measure 이전 글들에서 르벡 측도를 이용해 정의한 르벡적분과 앞으로 살펴볼 일반측도 $\mu$를 이용해 정의하는 르벡적분은 크게 다르지 않다. 르벡측도를 이용한 르벡적분은 $\mu=m$ 의 특수한 경우이지만 대부분의 중요한 정리들은 그대로 성립한다. 르벡적분의 정의 이전에 살펴본 단순함수근사로부터 양함수 $f:X\to[0...
Monotone Class Argument Dynkin's $\pi-\lambda$ system이라고도 불리는 체계는 실변수함수론에서 다양한 정리들을 증명하거나 할 때 유용하게 사용된다. 또한, 확률론에서도 사건이나 random event의 독립성을 확인할 때 역시 이용된다. 우선 $\pi$ system, $\lambda$ system이 무엇인지 살펴보고, 간단한 예시를 통해 이들이 어...
Basis Expansion 기저 확장이란 데이터셋 $\mathbf{X}$의 각 벡터 $X\in\mathbf{X}$에 새로운 변수를 추가하거나, 기존 변수를 대체하는 방법으로 새로운 모형을 구성하는 것이다. 총 M개의 변환이 존재한다고 하고, 이때 $m$번째($m= 1,\ldots,M$) 변환을 $$ hm(X) : \mathbb{R^p\to R} $$ 로 표기하자(기존 데이터는 p개의...
Logistic Regression 로지스틱 회귀분석은 회귀분석의 일종으로 보기 쉽지만, 사실 분류문제의 사후확률을 선형함수로 표기한것에서 비롯되기 때문에 분류기법으로 보는 것이 더 정확하다. 즉, 각 데이터 $X=x$ 가 클래스 $G=k\;(k=1\cdots K)$ 를 가질 확률을 비율로 치환(한개 클래스를 기준으로, 여기서는 $G=K$)한 뒤 $$ \log\frac{P(G=k\ver...
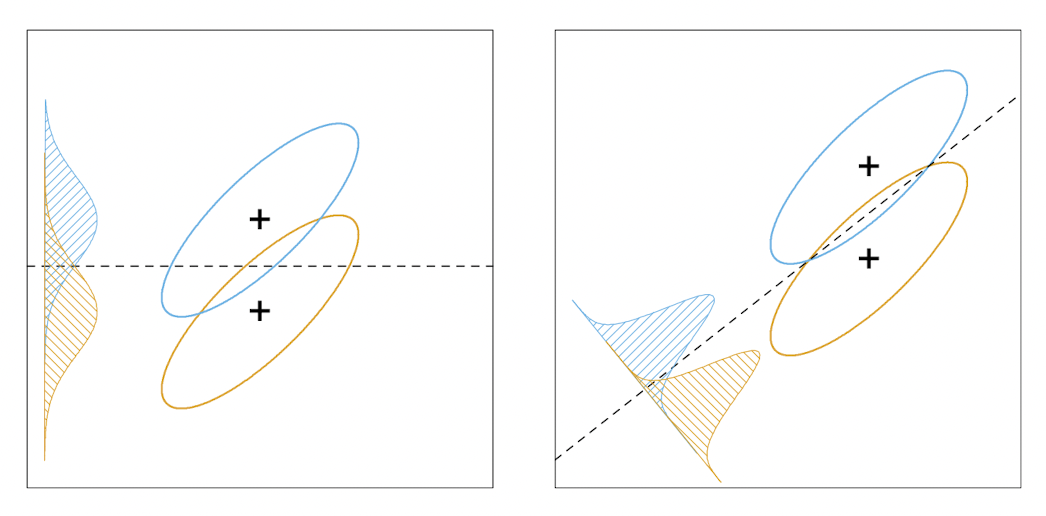
LDA의 다른 관점 이전 포스트에서 살펴본 것 처럼, LDA는 데이터셋의 정규성을 가정하여 분류하는 방법이다. 이를 제한된 가우시안 분류기 restricted gaussian classifier 라는 관점으로 본다면, 이번에 다룰 내용은 LDA가 데이터를 저차원으로 투영시켜 본다는 정사영 projection 의 관점이다. 클래스가 $K$개인 데이터셋이 있고, 각각의 데이터는 $p$개의...
Linear Classification 이번 포스트부터는 선형 방법으로 분류 문제를 해결하는 방법들에 대해 살펴보고자 한다. 여기서 분류 classification 문제란, 종속 변수와 예측값 $G(x)$ 가 이산집합 $\mathcal{G}$의 원소를 갖는 문제를 의미한다. 분류 문제의 핵심은 결정경계 decision boundary 를 찾는 것인데, 결정경계가 선형인 것들만 우선 다루...
Linear Regression - Using Substituted Input 이전 게시글에서는 주어진 변수들을 그대로 사용하여 회귀분석하는 다양한 방법을 다루었다. 이번 포스팅에서는 주어진 변수들을 기반으로 새로운 변수들을 만들어 회귀분석을 진행하는 방법을 다루어보도록 한다. 주성분회귀 Principal Components Regression 주성분(Principal Component...
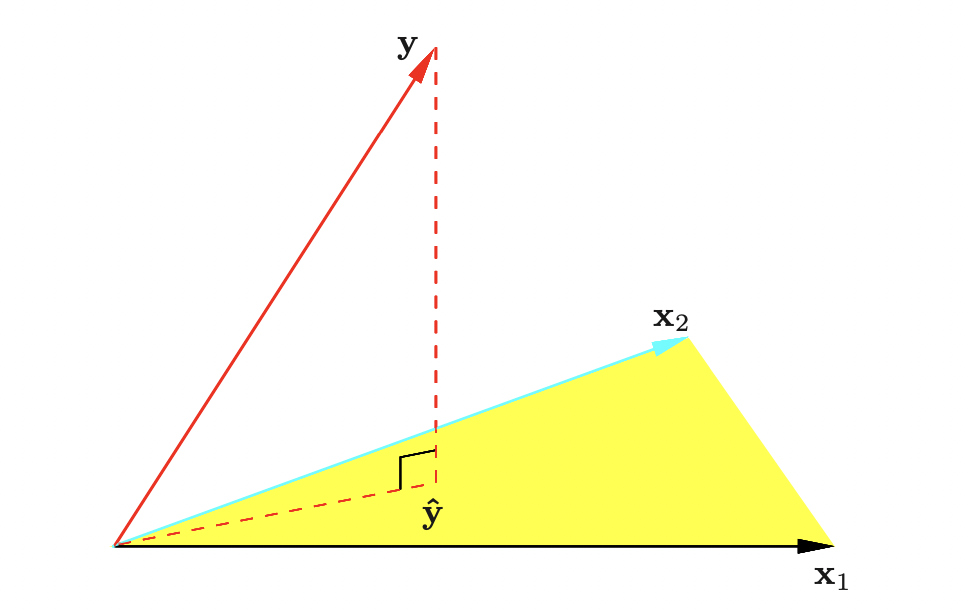
Linear Methods for Regression 선형회귀는 통계적 학습의 고전적인 방법이다. 하지만 문학에서의 고전 명작과 마찬가지로 현대의 수많은 머신러닝 기법들의 가장 기초가 된다. 또한 Simple is best 라는 말과 같이, 때로는 선형관계가 명확한 데이터에서 가장 효율적으로 작동하기도 한다. 이번 포스팅에서는 선형회귀의 기본이 되는 최소제곱법과 각종 규제법을 살펴보고자...
무한차원특성공간 vs 유한차원특성공간 커널 트릭에서 살펴보았듯이, 커널을 이용하면 데이터셋을 특성 매핑(feature mapping)을 사용하지 않고도 동일한 연산을 수행할 수 있다. Input Space $\mathbf{X}$의 데이터가 벡터 $\mathbf{x1,\ldots,xk}$ 로 주어진다고 하자. 특성 매핑(사상) $\phi(\mathbf{x}):\mathbf{X}\to\ma...
확률측도 정의 공간 $\Omega$와 $\Omega$의 부분집합들로 구성된 Borel Field $\mathscr{F}$ 에서 정의된 확률측도 probability measure $P$ 는 다음 공리를 만족시킨다. 1. $\forall E\in \mathscr{F}: P(E)\geq 0$ 2. (가산가법성) $\mathscr{F}$의 서로소인 가산모임 {$Ek:k\in \mathbb{N...
측도의 일반화 이전까지 다루었던 측도의 개념은 르벡 측도에 관한 것으로, 가측집합의 모임들이 시그마 대수인 것을 외측도의 제한으로 보였으며, 이를 통해 측도론을 구성해왔다. 이를 르벡 측도의 Caratheodory construction 이라고 부르는데, 여기서는 이러한 기술을 좀 더 일반화하는 방법을 살펴본다. 흔히 통계학에서 다루는 확률 측도 probability measure 의...
커널 주성분분석 Kernel PCA PCA 주성분분석(Principal Component Analysis, 이하 PCA) 의 기본원리는 Input Matrix의 고유값을 이용해 Input 데이터들의 성분을 분리하는 것이다. 원리 Input Matrix $\mathbf{X}$가 p개의 성분과 첫 열로 일벡터를 가지는 n개의 데이터셋, 즉 $n\times (p+1)$ 행렬이라고 하자. 즉,...
Kernel Methods 이번 포스트에서는 저번에 살펴본 커널함수를 이용한 방법론들을 살펴보고자 한다. 커널에 의해 정의된 유사성 행렬 similarity matrix 을 입력받아 처리하는 알고리즘을 Kernel Methods 라고 한다. 앞서 살펴본 것 처럼 커널은 유사성의 측도로도 정의되고, 데이터공간의 원소들을 커널에 입력하면 실행렬을 얻을 수 있는데, 이를 유사성 행렬이라 한다...
위상공간에서의 연속사상 정의 위상공간 $(X,\mathcal{T})$와 $(Y,\mathcal{S})$ 를 연결하는 사상 $f:X\to Y$ 가 점 $x0$에서 연속이기 위한 조건은 다음과 같다. $f(x0)$의 임의의 근방 $\mathcal{O}$ 에 대해 $x0$의 근방 $\mathcal{U}$ 가 존재하여 $f(\mathcal{U)}\subseteq\mathcal{O}$ 가 성립한...
위상공간의 분리 Separation 위상공간 X의 부분집합 $A,B \subset X$ 가 서로소라고 하자. 만일 $A,B$ 각각의 서로소인 근방이 존재한다면, 이를 근방에 의해 분리된다고 표현한다. 이 장에서는 네 가지의 주요 분리 성질을 바탕으로 위상공간을 분류하는 것을 다룬다. 티호노프 Tychonoff 분리 성질 위상공간 $X$의 두 점 $u,v \in X$에 대해 $v$를 포함...
위상공간 Topological Spaces 위상공간은 집합의 일종으로, 위상(토폴로지, topology)이 부여된 공간을 의미한다. 앞서 살펴본 거리공간 역시 위상공간의 일종인데, 거리공간에서의 거리의 개념이 위상을 정의하기 때문이다. 이 장에서 다루고자 하는 위상공간은, 거리공간보다 더 일반적인 개념이며 이를 바탕으로 가산성, 사상의 연속성과 같은 내용을 다룰 것이다. 정의 우선, 공...
바나흐 고정점 정리 바나흐 고정점 정리(혹은 축약 사상 정리)는 축약사상에 대해 고정점이 하나만 존재한다는 정리이다. 우선 이를 알기 위해 축약 사상과 고정점의 개념에 대해 다루어보자. Def 거리공간 X에서의 점 $x\in X$ 와 사상 $T:X\to X$ 에 대해 $T(x)=x$ 이 성립하면 점 $x$를 X의 고정점이라고 한다. Def 거리공간 $(X,\rho)$ 에서의 사상 $T$...
거리공간 Metric Spaces 이번 포스팅에서는 실해석학에서 다뤄지는 거리 metric 의 개념과, 이를 이용해 정의된 거리공간과 그 특성들에 대해 대략적으로 다루어보고자 한다. 해석개론에서 다루어지는 기본적인 열린/닫힌 집합의 개념과 열린/닫힌 집합에서의 수열과 같은 내용들은 분량상 생략하도록 하겠다. 정의 우선, Metric의 개념을 다음과 같은 실함수로 정의한다. Def 비어있...
Convex Functional and its minimization Convex / Closed subset의 정의 Def 선형공간 $X$의 부분집합 $C$가 Convex set 이다: $\forall f.g\in C, \quad \forall \lambda \in [0,1]$ 에 대해 $\lambda f+(1-\lambda)g \in C$ 가 성립한다. 또한, 다음과 같이 노음선형공...
Weak Sequential Compactness 약한 점열 컴팩트성 헬리 Helley 의 정리 THM 14 가측집합 $E$와 $1 증명. 노음선형공간 $X$가 separable 하므로, 조밀한 가산부분집합 {$fj:j\in\mathbb{N}$} 을 생각하자. 이때 선형범함수열 $Tn$이 유계이므로, 실수열 {$Tn(f1) : n \in \mathbb{N}$} 을 생각하면 이는 유계실수...
L^p 공간에서의 측도의 약한 수렴 정의 L^p 공간에서의 함수열의 수렴을 정의하기 위해서는 노음선형공간에서의 함수열의 수렴이 먼저 정의되어야 한다. Def 노음선형공간 $X$의 함수열 $fn$이 $f$ 로 약한 수렴한다는 것 ($fn \to f$) 은 다음을 의미한다. $$ \limnT(fn) = T(f)\quad \forall T \in X^\ast $$ Def $fn$이 $f$로...
크로스오버 28인치 4K 모니터 2890CU 리뷰 평소 데스크탑은 따로 장만할 필요가 없어 M1맥북으로 집이나 밖에서 모두 작업을 하는 편이다. 밖에서 간단히 작업을 하는 경우에는 상관이 없는데, 집에서 오래 맥북의 작은 13인치 모니터를 보고 있는 경우 눈에 좀 무리가 가는 것 같아 모니터를 장만하기로 했다. 우선 모니터를 선정하는데 가장 중요한 기준은 - USB-C 타입 포트를 이용...
Duality 선형 범함수 쌍대성(Duality)을 정의하기 이전에, 선형 범함수(linear functional)에 대해 알 필요가 있다. 우선 범함수란, 함수들의 함수로 어떠한 함수공간을 정의역으로 하고 실수 혹은 복소수 집합을 공역으로 하는 함수이다. 이때, 함수공간은 벡터공간이기 때문에 벡터공간에서부터 실수로 정의되는 함수로 이해하는 것이 쉽다. 예로 이전에 살펴보았던 르벡 적분...
Completeness of $L^p$ Spaces 완비성 Def 노음선형공간 X에서 함수열의 수렴 $fn \to f$ 은 다음과 같이 정의한다. $$ \limn\Vert f-fn\Vert = 0 $$ 마찬가지로, 함수열 $fn$이 코시수열임은 다음과 같이 정의한다. $\forall\epsilon>0,\; \exists N \in \mathbb{N}\quad s.t. \\ \Vert f...

MX Keys for mac 키보드 리뷰 평소 아이패드를 위주로 사용하며 공부를 하다가 블로그 포스트 작성이나 코딩과 같이 본격적으로 노트북을 사용해야 할 일이 많아져서 맥북을 구입했었다. 맥북 자체의 키보드도(M1 에어) 워낙 훌륭하다보니 사용하면서 불편함을 그닥 느끼지 못해왔다. 다만 자세를 올바르게 하고자 스탠드에 올려 노트북을 사용하다보니 오히려 손목에 좀 무리가 가는 것 같아...
$L^p$ Spaces Normed Linear Spaces 노음선형공간 이 장을 시작하기에 앞서, 집합 $E$는 실수 집합의 가측부분집합이고 집합족 $\mathcal{F}$는 $E$에서의 모든 유한(a.e. on E), 가측 실함수들의 모임으로 가정하자. Def 함수간의 동치관계 만약 집합 E에서의 함수 $f,g$ 가 E의 거의 모든점(almost everywhere)에서 같다면 $f...
Lebesgue Integral General Vitali Theorem Def $E$에서의 가측함수들의 집합족 $\mathcal F$가 다음을 만족할 때 $E$에서 Tight 하다고 정의한다. $$\forall \epsilon>0,\; \exists E0 \subseteq E \text{ w/ } m(E0) 일반화된 비탈리 수렴정리 가측집합 $E$에서의 함수열 {$fn$}이 균등적분가...
이번 포스트에서는 'An Introduction to Kernel-Based Learning Algorithms' 라는 Paper을 리뷰하며 머신러닝에서 널리 사용되는 커널 이론의 원리와 배경에 대해 알아보고자 한다. 이번 장에서는 먼저 커널 함수가 대표적으로 이용되는 서포트 벡터 머신을 간단하게 살펴볼 것이다, 분류 이론의 기초 서포트 벡터 머신은 회귀 문제에도 사용되지만, 대표적인...
Lebesgue Integral General Lebesgue Integral Def 함수 $f$에 대해 다음 두 nonnegative 함수를 정의하면 - $f^+ = \max(f, 0)$ - $f^-= -\min(f, 0)$ $$\vert f\vert = f^+ +f^- ,f = f^+-f^- $$ 임을 알 수 있다. 위 두 함수는 nonnegative function 이므로, 이전에...
Lebesgue Integral 유계,유한 가측함수에 대한 르벡 적분 단순함수의 르벡 적분 유한측도를 갖는 $E$ 에서 Canonical Form $\psi = \sum{i=1}^n ai\chi{Ei}$ 을 갖는 단순함수의 적분은 다음과 같이 정의된다. $$\intE \psi = \sum{i=1}^n ai\cdot m(Ei)$$ Lebesgue Integral of bounded $f$...
Lebesgue Measurable Function (르벡 가측함수) 1. Sums, Products, and Compositions Def 다음 조건을 만족시키는 실함수 $f:E \to \mathbb{R}$ 는 르벡 가측함수 Lebesgue Measurable Function 이다: 1) 정의역 E가 가측집합이다. 2) 임의의 실수 $c\in \mathbb{R}$에 대해 집합 $$\l...
Lebesgue Measurable Function (2) Egoroff's THM THM. 유한 측도를 갖는 가측집합 $E$와 $E$에서의 실함수열 $\lbrace fn\rbrace $에 대해 $fn \to f$ 일때 $\cdots$ (a) $\forall \epsilon>0$ 에 대해 닫힌 집합 $F$가 존재하여 $F$에서 $fn$이 $f$로 균등수렴하고 $m(E-F) 0$에 대해...
Lebesgue Measure (르벡 측도) 3. Outer / Inner Approximation of Lebesgue measurable sets Excision Property - 유한 외측도(finite outer measure)를 갖는 가측 집합 $A$가 $A \subseteq B$를 만족한다면 $$m^{\ast}(B-A) = m^{\ast}(B)-m^{\ast}(A)$$ (단...
Lebesgue Measure (르벡 측도) 1. Lebesgue Outer Measure Def 가산개의 비어 있지 않은 열린, 유계 구간열 $\lbrace Ik\rbrace \{k=1}^\infty$ 을 생각하자. 이때 임의의 집합 A에 대해서 $A\subseteq \bigcup{k=1}^\infty Ik$ 를 만족한다면 집합 A의 외측도(outer measure)을 다음과 같이 정...
1. Three Major Axioms in Real Numbers 1. Field Axiom (체공리) 다음 9가지 성질을 만족하는 set $F$ 를 Field(체) 라고 정의한다. 덧셈에 대한 교환법칙(Commutativity) 덧셈에 대한 결합법칙(Associativity) 덧셈에 대한 항등원(Identity) 존재 덧셈에 대한 역원(Inverse) 존재 곱셈에 대한 교환법칙(Co...
1. Countability Def 집합 $E$가 가산무한집합 Countably finite set : $E$가 자연수 집합 $\mathbb{N}$과 equipotent하다. 2. $\sigma$-Algebra Def 집합 $X$의 부분집합들의 모임 collection $F$가 다음 조건을 만족하면 $F$를 $X$의 시그마 대수라고 한다. P1. $\emptyset \in F$ P2....